
Write-Ahead Logging for Durable Key/Value Persistence
We develop write-ahead logging for our
partitioned, log-structured
merge-tree key/value store
to improve durability. Different
sync
strategies are developed and
benchmarked for committing log entries. We find a large penalty for always syncing, but a modest penalty for
frequent syncing in a background thread.
Introduction
Our previously developed
partitioned, log-structured merge-tree (LSMTree)
key/value store
has a significant flaw; the storage engine is not durable. With writes collected in memory for
batch persistence to disk, writes would be lost should the process crash or if the machine itself crashes or loses
power. We address this deficiency in the current project by adding write-ahead logging (WAL) to ensure that a
record of all
PUT
or
DELETE
operations are persisted to disk at the time of the
operation. Additionally, we explore different strategies for committing WAL records to disk through
sync
system calls and benchmark the performance penalties of each strategy.
Write-Ahead Logging
Our previously developed
LSMTree
writes data to disk in large
batches so that each batch can be sorted and indexed for efficient key lookups in subsequent
GET
operations. While this does eventually persist all data to disk in normal operation, writes collected in memory
would be lost if the process or host crashes. This is a common challenge in many database designs where writes are
written in batches so that the structure of the written file is amenable to searching.
Therefore a common strategy has been developed for enhancing data durability in the form of write-ahead logging (WAL). In WAL, separate files are maintained that include a record of all write operations performed on the database. Entries are added in chronological order at the time of the operation as shown in the follow diagram.

The WAL files lack sorted and indexed structure and are therefore not amenable to efficient searching like the container files used in the LSMTree. That is fine because these files serve a different purpose. In the event of a crash, a database can reads the WAL files when it is restarted and perform any write operations that weren't already persisted. Writes are persisted to the WAL before performing the operation within the database, hence the term "write-ahead", and this therefore ensures that any write operation successfully applied on the database are durably persisted to the WAL.
Committing WAL Entries Through sync System Calls
Simply writing WAL entries to a file is insufficient to ensure the data is actually persisted to disk due to the various layers of abstraction between our program and 1s and 0s on the disk. As previously discussed, the Operating System Page Cache and Disk Buffers can hold the data in volatile memory before they are persisted to disk. Hence, if the host machine were to crash or lose power, we could lose entries written to the WAL.
For many applications, including database WALs, it essential to ensure data is actually persisted to disk before
continuing on in the application. To this end, operating systems provide the
sync
system call.
sync
is called for a
file handle and it instructs the operating system to commit all writes for that file to disk. The system call
doesn't return until this has succeeded, which thereby allows the application to proceed confident that data has
been persisted.
Waiting for disk persistence can introduce significant performance penalties in applications. For this reason, some persistent storage systems don't perform a sync call on every write. For example, MongoDB performs sync operations on its WAL every 100ms by default. We'll explore different syncing strategies in developing WAL for our LSMTree and quantify the performance impact for each in benchmarking.
Note that
sync
generally doesn't address the issues with
Disk Buffers, although
recent version of linux will flush disk caches within fsync. Some drives support entirely disabling the disk buffer, although doing so can result in massively
degraded performance.
Alternatively, high-end RAID controllers commonly include an
onboard battery
that allows them to successfully persist
all writes should the machine itself lose power. One should consider how their drives handle power loss when
creating a highly durable storage system.
Developing Write-Ahead Logging
We begin our development of WAL by creating a simple class for writing
PUT
and
DELETE
operations to a log file. A generic
LogSynchronizer
interface is introduced so that we can experiment
with different syncing strategies.
public class WriteAheadLogWriter implements Closeable {
private final String name;
private OutputStream outputStream;
private final LogSynchronizer logSynchronizer;
public WriteAheadLogWriter(String name, OutputStream outputStream, LogSynchronizer logSynchronizer) {
this.name = name;
this.outputStream = outputStream instanceof BufferedOutputStream ? outputStream :
// use a buffer to collect the small writes used for prefix characters
// always flush the buffer after writing an entry
new BufferedOutputStream(outputStream, 2048);
this.logSynchronizer = logSynchronizer;
}
@NotNull public String getName() {
return name;
}
public synchronized void logPut(@NotNull ByteArrayWrapper key, @NotNull ByteArrayWrapper value) throws IOException {
Preconditions.checkState(outputStream != null, "%s is already closed", name);
outputStream.write(WriteAheadLogConstants.PUT);
PrefixIo.writeBytes(outputStream, key);
PrefixIo.writeBytes(outputStream, value);
outputStream.flush();
logSynchronizer.registerLog();
}
public synchronized void logDelete(@NotNull ByteArrayWrapper key) throws IOException {
Preconditions.checkState(outputStream != null, "%s is already closed", name);
outputStream.write(WriteAheadLogConstants.DELETE);
PrefixIo.writeBytes(outputStream, key);
outputStream.flush();
logSynchronizer.registerLog();
}
@Override public synchronized void close() throws IOException {
logSynchronizer.close();
outputStream.close();
outputStream = null;
}
}
Different Syncing Strategies
The
LogSynchronizer
interface encapsulate the
OutputStream
for a WAL file and provides
a single method for notification when a log entry has been written.
public interface LogSynchronizer extends Closeable {
void registerLog() throws IOException;
interface Factory<T extends OutputStream> {
LogSynchronizer create(FileOperations<T> fileOperations, T outputStream) throws IOException;
}
}
One implementation of this interface simply performs a
sync
system call every time that a log entry
is written to provide the highest level of durability.
public class ImmediateLogSynchronizer<T extends OutputStream> implements LogSynchronizer {
private final FileOperations<T> fileOperations;
private final T outputStream;
public ImmediateLogSynchronizer(FileOperations<T> fileOperations, T outputStream) {
this.fileOperations = fileOperations;
this.outputStream = outputStream;
}
@Override public void registerLog() throws IOException {
fileOperations.sync(outputStream);
}
@Override public void close() throws IOException {
// do nothing, all of our writes have been sync'd
}
public static <T extends OutputStream> LogSynchronizer.Factory<T> factory() {
return ImmediateLogSynchronizer::new;
}
}
An alternative implementation performs syncing in a background thread with a configurable delay between each
sync
system call. Its
registerLog
method simply sets the member boolean
dirty
to true so that the background thread knows a
sync
is needed the next time it is
ran.
public class FrequencyLogSynchronizer<T extends OutputStream> implements LogSynchronizer {
private static final Logger LOGGER = Dbf0Util.getLogger(FrequencyLogSynchronizer.class);
private final FileOperations<T> fileOperations;
private final T outputStream;
private ScheduledFuture<?> checkingFuture;
private boolean dirty = false;
private boolean errorInSync = false;
public FrequencyLogSynchronizer(FileOperations<T> fileOperations, T outputStream) {
this.fileOperations = fileOperations;
this.outputStream = outputStream;
}
public synchronized void schedule(ScheduledExecutorService scheduledExecutorService, Duration frequency) {
Preconditions.checkState(checkingFuture == null);
checkingFuture = scheduledExecutorService.scheduleWithFixedDelay(this::synchronizeRunnable,
frequency.toMillis(), frequency.toMillis(), TimeUnit.MILLISECONDS);
}
@Override public void registerLog() throws IOException {
Preconditions.checkState(checkingFuture != null, "not initialized");
if (errorInSync) {
throw new RuntimeException("error in synchronizing and write-ahead-log is no longer usable");
}
dirty = true;
}
@Override public synchronized void close() throws IOException {
if (checkingFuture != null) {
checkingFuture.cancel(false);
checkingFuture = null;
synchronize();
}
}
private void synchronize() throws IOException {
if (dirty) {
fileOperations.sync(outputStream);
dirty = false;
}
}
private synchronized void synchronizeRunnable() {
try {
synchronize();
} catch (Exception e) {
LOGGER.log(Level.SEVERE, "error in synchronizing", e);
errorInSync = true;
checkingFuture.cancel(false);
checkingFuture = null;
}
}
public static class Factory<T extends OutputStream> implements LogSynchronizer.Factory<T> {
private final ScheduledExecutorService scheduledExecutorService;
private final Duration frequency;
public Factory(ScheduledExecutorService scheduledExecutorService,
Duration frequency) {
this.scheduledExecutorService = scheduledExecutorService;
this.frequency = frequency;
}
@Override
public FrequencyLogSynchronizer<T> create(FileOperations<T> fileOperations,
T outputStream) throws IOException {
var synchronizer = new FrequencyLogSynchronizer<T>(fileOperations, outputStream);
synchronizer.schedule(scheduledExecutorService, frequency);
return synchronizer;
}
}
public static <T extends OutputStream> Factory<T> factory(
ScheduledExecutorService scheduledExecutorService, Duration frequency) {
return new Factory<>(scheduledExecutorService, frequency);
}
}
Encapsulating WAL Management
Now that we have the components for writing a WAL and performing syncing, we develop a class to encapsulate a
collection of WAL files. This will allow a storage engine using WAL to create multiple WAL files and delete files
once they are no longer needed. For our LSMTree, a WAL file isn't needed once the corresponding write entries have
been persisted to disk in one of the file-based containers. Additionally, the
WriteAheadLog
class
takes a
Supplier<LogConsumer>
on initialization so that the storage engine can persist any
writes in previous WAL files in crash recovery.
public class WriteAheadLog<T extends OutputStream> {
private static final Logger LOGGER = Dbf0Util.getLogger(WriteAheadLog.class);
private final FileDirectoryOperations<T> directoryOperations;
private final LogSynchronizer.Factory<T> logSynchronizerFactory;
private enum State {
UNINITIALIZED,
INITIALIZED,
CORRUPTED
}
private State state = State.UNINITIALIZED;
private int nextLogIndex = 0;
public WriteAheadLog(FileDirectoryOperations<T> directoryOperations,
LogSynchronizer.Factory<T> logSynchronizerFactory) {
this.directoryOperations = directoryOperations;
this.logSynchronizerFactory = logSynchronizerFactory;
}
public void initialize(@NotNull Supplier<LogConsumer> logConsumerSupplier) throws IOException {
Preconditions.checkState(state == State.UNINITIALIZED);
if (!directoryOperations.exists()) {
directoryOperations.mkdirs();
} else {
var contents = directoryOperations.list();
if (!contents.isEmpty()) {
try {
loadLogs(contents, logConsumerSupplier.get());
} catch (Exception e) {
state = State.CORRUPTED;
var msg = "Exception in loading write-ahead-log. Assuming corrupted.";
LOGGER.log(Level.SEVERE, msg, e);
throw new RuntimeException(msg, e);
}
}
}
Preconditions.checkState(directoryOperations.list().isEmpty());
state = State.INITIALIZED;
}
@NotNull public WriteAheadLogWriter createWriter() throws IOException {
Preconditions.checkState(state == State.INITIALIZED);
var name = String.valueOf(nextLogIndex++);
LOGGER.info("Creating write-ahead-log " + name);
var fileOperations = directoryOperations.file(name);
Preconditions.checkState(!fileOperations.exists());
var stream = fileOperations.createAppendOutputStream();
return new WriteAheadLogWriter(name, stream,
logSynchronizerFactory.create(fileOperations, stream));
}
public void freeWriter(@NotNull String name) throws IOException {
Preconditions.checkState(state == State.INITIALIZED);
LOGGER.info("Freeing write-ahead-log " + name);
var fileOperations = directoryOperations.file(name);
fileOperations.delete();
}
private void loadLogs(Collection<String> unorderedLogs, LogConsumer logConsumer) throws IOException {
LOGGER.warning("write-ahead-logs exist from previous run. loading: " + unorderedLogs);
var orderedLogs = unorderedLogs.stream()
.sorted((a, b) -> Ints.compare(Integer.parseInt(a), Integer.parseInt(b)))
.collect(Collectors.toList());
for (String name : orderedLogs) {
loadLog(name, logConsumer);
}
}
private void loadLog(String name, LogConsumer logConsumer) throws IOException {
LOGGER.info("loading write-ahead-log " + name);
var fileOperations = directoryOperations.file(name);
try (var stream = new BufferedInputStream(fileOperations.createInputStream())) {
while (true) {
var code = stream.read();
if (code < 0) {
break;
}
ByteArrayWrapper key;
switch ((byte) code) {
case WriteAheadLogConstants.PUT:
key = PrefixIo.readBytes(stream);
var value = PrefixIo.readBytes(stream);
logConsumer.put(key, value);
break;
case WriteAheadLogConstants.DELETE:
key = PrefixIo.readBytes(stream);
logConsumer.delete(key);
break;
default:
var msg = "Unexpected control code " + code + " in log " + name;
LOGGER.log(Level.SEVERE, msg);
throw new RuntimeException(msg);
}
}
}
logConsumer.persist();
LOGGER.info("finished loading and persisting write-ahead-log " + name + ". deleting");
fileOperations.delete();
}
}
Note that WAL files are named with ascending integers to allow reading the files in the appropriate order when recovering from a crash.
Adding WAL to Our LSMTree
Next, we extend our
LSMTree
class to use our newly developed WAL. This is accomplished by
associating each batch of pending writes with a WAL file so that the file can be deleted once the batch of pending
writes has been successfully persisted to disk.
class PendingWritesAndLog {
final Map<ByteArrayWrapper, ByteArrayWrapper> writes;
@Nullable final WriteAheadLogWriter logWriter;
public PendingWritesAndLog(Map<ByteArrayWrapper, ByteArrayWrapper> writes,
@Nullable WriteAheadLogWriter logWriter) {
this.writes = writes;
this.logWriter = logWriter;
}
}
Only a few modifications are needed for our
LSMTree
to record all
PUT
and
DELETE
operations to the WAL.
public class LsmTree<T extends OutputStream>
implements CloseableReadWriteStorage<ByteArrayWrapper, ByteArrayWrapper> {
...
@Nullable private final WriteAheadLog<?> writeAheadLog;
private PendingWritesAndLog pendingWrites;
private LsmTree(...,
@Nullable WriteAheadLog<?> writeAheadLog) {
...
this.writeAheadLog = writeAheadLog;
}
@Override public void initialize() throws IOException {
baseDeltaFiles.loadExisting();
if (writeAheadLog != null) {
writeAheadLog.initialize(() -> {
// these pending writes don't need a log since they are already persisted in current log that we're reading
pendingWrites = new PendingWritesAndLog(new HashMap<>(pendingWritesDeltaThreshold), null);
return new LogConsumer() {
@Override public void put(@NotNull ByteArrayWrapper key, @NotNull ByteArrayWrapper value) throws IOException {
pendingWrites.writes.put(key, value);
}
@Override public void delete(@NotNull ByteArrayWrapper key) throws IOException {
pendingWrites.writes.put(key, DELETE_VALUE);
}
@Override public void persist() throws IOException {
sendWritesToCoordinator();
coordinator.addWrites(pendingWrites);
pendingWrites = new PendingWritesAndLog(new HashMap<>(pendingWritesDeltaThreshold), null);
}
};
});
}
mergerCron.start();
createNewPendingWrites();
}
@Override public void put(@NotNull ByteArrayWrapper key, @NotNull ByteArrayWrapper value) throws IOException {
Preconditions.checkState(isUsable());
var writesBlocked = lock.callWithWriteLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
if (pendingWrites.logWriter != null) {
pendingWrites.logWriter.logPut(key, value);
}
pendingWrites.writes.put(key, value);
return checkMergeThreshold();
});
if (writesBlocked) {
waitForWritesToUnblock();
}
}
@Override public boolean delete(@NotNull ByteArrayWrapper key) throws IOException {
Preconditions.checkState(isUsable());
var writesBlocked = lock.callWithWriteLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
if (pendingWrites.logWriter != null) {
pendingWrites.logWriter.logDelete(key);
}
pendingWrites.writes.put(key, DELETE_VALUE);
return checkMergeThreshold();
});
if (writesBlocked) {
waitForWritesToUnblock();
}
return true;// doesn't actually return a useful value
}
private void createNewPendingWrites() throws IOException {
pendingWrites = new PendingWritesAndLog(new HashMap<>(pendingWritesDeltaThreshold),
writeAheadLog == null ? null : writeAheadLog.createWriter());
}
private void sendWritesToCoordinator() throws IOException {
if (pendingWrites.logWriter != null) {
pendingWrites.logWriter.close();
}
coordinator.addWrites(pendingWrites);
}
Lastly, the
DeltaWriterCoordinator
is revised to use the
PendingWritesAndLog
as its
unit of work for writing a delta. Further, it deletes the underlying WAL file once all writes have been
successfully committed to disk.
public class DeltaWriterCoordinator<T extends OutputStream> {
...
void addWrites(PendingWritesAndLog originalWrites) {
Preconditions.checkState(!hasMaxInFlightWriters());
Preconditions.checkState(isUsable());
var writes = new PendingWritesAndLog(
Collections.unmodifiableMap(originalWrites.writes), originalWrites.logWriter);
...
}
private void commitWritesWithLogging(WriteSortedEntriesJob<T> writer) {
try {
if (state == State.WRITING_BASE) {
Preconditions.checkState(writer.isBase());
baseDeltaFiles.setBase();
state = State.WRITE_DELTAS;
} else {
Preconditions.checkState(state == State.WRITE_DELTAS);
baseDeltaFiles.addDelta(writer.getDelta());
}
var logWriter = writer.getPendingWritesAndLog().logWriter;
if (logWriter != null) {
Preconditions.checkState(writeAheadLog != null);
writeAheadLog.freeWriter(logWriter.getName());
}
var removed = inFlightWriters.remove(writer);
Preconditions.checkState(removed);
} catch (Exception e) {
LOGGER.log(Level.SEVERE, e, () -> "error in committing writes. aborting");
abortWrites(writer);
}
}
...
}
Unit Testing
Tests for WAL Components
It is important to test for the correctness of the newly developed WAL components since they are essential for
preserving data durability. Simple tests are developed using mocking with
Mockito
for each of the
LogSynchronizer
implementations.
ImmediateLogSynchronizerTest code
public class ImmediateLogSynchronizerTest {
@Before public void setUp() throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINER, true);
}
@Test public void testScheduledSynchronization() throws Exception {
var fileOperations = (FileOperations<OutputStream>) mock(FileOperations.class);
var outputStream = mock(OutputStream.class);
var factory = ImmediateLogSynchronizer.factory();
var synchronizer = factory.create(fileOperations, outputStream);
verifyZeroInteractions(fileOperations);
synchronizer.registerLog();
verify(fileOperations, times(1)).sync(outputStream);
synchronizer.close();
verify(fileOperations, times(1)).sync(outputStream);
}
}
Testing
FrequencyLogSynchronizer
is slightly more complicated since we want to access the
Runnable
that it registers for scheduled execution without actually creating a
ScheduledExecutorService
and waiting for the background task to run. For this we use an
ArgumentCaptor
to access the
Runnable
and then run it directly to simulate scheduled
execution.
FrequencyLogSynchronizerTest code
public class FrequencyLogSynchronizerTest {
@Before public void setUp() throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINER, true);
}
@Test public void testScheduledSynchronization() throws Exception {
var frequency = Duration.ofMillis(32094);
var executor = mock(ScheduledExecutorService.class);
var future = mock(ScheduledFuture.class);
var fileOperations = (FileOperations<OutputStream>) mock(FileOperations.class);
var outputStream = mock(OutputStream.class);
when(executor.scheduleWithFixedDelay(any(Runnable.class), eq(frequency.toMillis()), eq(frequency.toMillis()), eq(TimeUnit.MILLISECONDS)))
.thenReturn(future);
var factory = FrequencyLogSynchronizer.factory(executor, frequency);
var synchronizer = factory.create(fileOperations, outputStream);
var runnableCapture = ArgumentCaptor.forClass(Runnable.class);
verify(executor, times(1))
.scheduleWithFixedDelay(runnableCapture.capture(), eq(frequency.toMillis()), eq(frequency.toMillis()), eq(TimeUnit.MILLISECONDS));
var runnable = runnableCapture.getValue();
assertThat(runnable).isNotNull();
verifyZeroInteractions(fileOperations);
synchronizer.registerLog();
runnable.run();
verify(fileOperations, times(1)).sync(outputStream);
runnable.run();
verify(fileOperations, times(1)).sync(outputStream);
synchronizer.close();
verify(future, times(1)).cancel(anyBoolean());
}
}
We also test the
WriteAheadLog
to ensure that it persists entries to disk, deletes files when
requested, and can enable crash recovery by reading remaining WAL files on initialization.
public class WriteAheadLogTest {
@Before public void setUp() throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINER, true);
}
@Test public void testDoNothing() throws Exception {
var directoryOperations = new MemoryFileDirectoryOperations();
var log = new WriteAheadLog<>(directoryOperations, ImmediateLogSynchronizer.factory());
log.initialize(() -> {
throw new AssertionError("should not be called");
});
assertThat(directoryOperations.list()).isEmpty();
}
@Test public void testFree() throws Exception {
var directoryOperations = new MemoryFileDirectoryOperations();
var initialLog = new WriteAheadLog<>(directoryOperations, ImmediateLogSynchronizer.factory());
initialLog.initialize(() -> {
throw new AssertionError("should not be called");
});
assertThat(directoryOperations.list()).isEmpty();
var writer = initialLog.createWriter();
writer.logPut(ByteArrayWrapper.of(1), ByteArrayWrapper.of(2));
writer.logDelete(ByteArrayWrapper.of(3));
writer.close();
assertThat(directoryOperations.list()).hasSize(1);
initialLog.freeWriter(writer.getName());
assertThat(directoryOperations.list()).isEmpty();
var secondLog = new WriteAheadLog<>(directoryOperations, ImmediateLogSynchronizer.factory());
secondLog.initialize(() -> {
throw new AssertionError("should not be called");
});
}
@Test public void testRecover() throws Exception {
var directoryOperations = new MemoryFileDirectoryOperations();
var initialLog = new WriteAheadLog<>(directoryOperations, ImmediateLogSynchronizer.factory());
initialLog.initialize(() -> {
throw new AssertionError("should not be called");
});
var putKey = ByteArrayWrapper.of(1);
var putValue = ByteArrayWrapper.of(2);
var deleteKey = ByteArrayWrapper.of(1);
var writer = initialLog.createWriter();
writer.logPut(putKey, putValue);
writer.logDelete(deleteKey);
writer.close();
var consumer = new LogConsumerCapture();
var recoverLog = new WriteAheadLog<>(directoryOperations, ImmediateLogSynchronizer.factory());
recoverLog.initialize(() -> consumer);
assertThat(consumer.operations).isEqualTo(
List.of(
Pair.of("put", Pair.of(putKey, putValue)),
Pair.of("delete", deleteKey),
Pair.of("persist", null)));
assertThat(directoryOperations.list()).isEmpty();
var postRecoverLog = new WriteAheadLog<>(directoryOperations, ImmediateLogSynchronizer.factory());
postRecoverLog.initialize(() -> {
throw new AssertionError("should not be called");
});
}
private static class LogConsumerCapture implements LogConsumer {
private final List<Pair<String, Object>> operations = new ArrayList<>();
@Override public void put(@NotNull ByteArrayWrapper key, @NotNull ByteArrayWrapper value) throws IOException {
operations.add(Pair.of("put", Pair.of(key, value)));
}
@Override public void delete(@NotNull ByteArrayWrapper key) throws IOException {
operations.add(Pair.of("delete", key));
}
@Override public void persist() throws IOException {
operations.add(Pair.of("persist", null));
}
}
}
Testing LSMTree Recovery Using WAL
We also develop a unit test for our
LSMTree
to ensure that it can recover from a crash using the
WAL. A crash is simulated by a developing a
FlakyLengthMemoryFileDirectoryOperations
that allows us to
trigger a failed write in delta generation at configured number of written bytes. In the test, we generate a
sequence of key/value entries and record those that the
LSMTree
allows us to write. These writes
happen in memory until the set of pending writes grows large enough for delta generation. The flaky file ensures
delta generation fails, which in turn causes the
LSMTree
to report itself as unusable.
The test then loads a new
LSMTree
using the same WAL as the original one. The test performs
GET
operations on this newly created storage engine for all of the previously
PUT
keys to
ensure that they exist in the recovered
LSMTree.
public class LsmTreeTest {
...
@Test
public void testRecoverFromCrashUsingLogs() throws IOException {
var logDirectory = new MemoryFileDirectoryOperations();
var createLsmTree = (Function<MemoryFileDirectoryOperations, ReadWriteStorageWithBackgroundTasks<ByteArrayWrapper, ByteArrayWrapper>>)
(dataDirectory) ->
LsmTree.builderForTesting(dataDirectory)
.withPendingWritesDeltaThreshold(1000)
.withWriteAheadLog(new WriteAheadLog<>(logDirectory, ImmediateLogSynchronizer.factory()))
.withScheduledThreadPool(2)
.withIndexRate(10)
.withMaxInFlightWriteJobs(10)
.withMaxDeltaReadPercentage(0.5)
.withMergeCronFrequency(Duration.ofMillis(250))
.buildWithBackgroundTaks();
var flakingTree = createLsmTree.apply(new MemoryFileDirectoryOperations("flaking",
Map.of("base", Either.left(new FlakyLengthMemoryFileDirectoryOperations(1000)))));
flakingTree.initialize();
var map = new HashMap<ByteArrayWrapper, ByteArrayWrapper>();
var random = RandomSeed.CAFE.random();
assertThatThrownBy(() -> {
for (int i = 0; i < 100 * 1000; i++) {
var key = ByteArrayWrapper.random(random, 16);
var value = ByteArrayWrapper.random(random, 100);
flakingTree.put(key, value);
map.put(key, value);
}
}).isInstanceOf(IllegalStateException.class);
flakingTree.close();
LOGGER.info("Wrote " + map.size() + " entries before failing");
assertThat(map).isNotEmpty();
var readingTree = createLsmTree.apply(new MemoryFileDirectoryOperations());
readingTree.initialize();
for (var entry : map.entrySet()) {
assertThat(readingTree.get(entry.getKey())).isEqualTo(entry.getValue());
}
readingTree.close();
}
...
}
Additionally, the logs from the unit test show the WAL components functioning properly.
08:09:45.308 INFO LsmTreeTest testRecoverFromCrashUsingLogs Wrote 6000 entries before failing
08:09:45.313 WARNING WriteAheadLog loadLogs write-ahead-logs exist from previous run. loading: [0, 1, 2, 3, 4, 5, 6]
08:09:45.317 INFO WriteAheadLog loadLog loading write-ahead-log 0
08:09:45.319 INFO DeltaWriterCoordinator lambda$addWrites$0 Creating new base for writes
08:09:45.326 INFO DeltaWriterCoordinator lambda$addWrites$0 Creating new delta for writes
08:09:45.326 INFO WriteSortedEntriesJob run Sorting 1000 writes for write0
08:09:45.335 INFO WriteSortedEntriesJob run Sorting 1000 writes for write1
08:09:45.335 INFO BaseDeltaFiles setBase Setting initial base
08:09:45.337 INFO WriteAheadLog loadLog finished loading and persisting write-ahead-log 0. deleting
08:09:45.338 INFO WriteAheadLog loadLog loading write-ahead-log 1
Benchmarking
We quantify the impact of WAL with different syncing strategies using benchmarking methods from our previous partitioned LSMTree project. See that project's benchmarking section for details. Present benchmarking considers several different strategies for WAL and syncing.
| WAL / Syncing Strategy | Description |
|---|---|
| No Log | No WAL. Uses results from past benchmarking |
| Always |
WAL with syncing after every write using the
ImmediateLogSynchronizer
|
| 10 |
WAL with syncing in background thread every 10ms using
FrequencyLogSynchronizer
|
| 100 | WAL syncing every 100ms |
| 1000 | WAL syncing every 1000ms |
Simple revisions are made to the benchmarking harness to create a partitioned LSMTree storage engine with WAL and configurable syncing strategy.
public class Benchmark {
...
private static ReadWriteStorageWithBackgroundTasks<ByteArrayWrapper, ByteArrayWrapper>
createPartitionedLsmTreeWithWriteAheadLog(Iterator<String> argsItr, File directory) throws IOException {
var pendingWritesMergeThreshold = Integer.parseInt(argsItr.next());
var indexRate = Integer.parseInt(argsItr.next());
var partitions = Integer.parseInt(argsItr.next());
var logSyncFrequency = Duration.parse(argsItr.next());
var executor = Executors.newScheduledThreadPool(8);
var base = new FileDirectoryOperationsImpl(directory);
base.mkdirs();
base.clear();
return new ReadWriteStorageWithBackgroundTasks<>(
HashPartitionedReadWriteStorage.create(partitions,
partition -> {
var partitionDir = base.subDirectory(String.valueOf(partition));
return createLsmTree(partitionDir.subDirectory("data"),
pendingWritesMergeThreshold, indexRate, executor,
new WriteAheadLog<>(partitionDir.subDirectory("log"),
logSyncFrequency.isZero() ? ImmediateLogSynchronizer.factory() :
FrequencyLogSynchronizer.factory(executor, logSyncFrequency)));
}),
executor);
}
...
}
Analysis of Benchmarking Results
Impact of WAL on Performance
We begin our analysis by quantifying the impact of WAL logs on a single partition LSMTree with several different workloads. Each axes shows a results for a single workload and results are ordered by overall performance, quantified by sum operations/second. Additionally, each result for a WAL scenario includes its change in performance relative to the results without WAL.
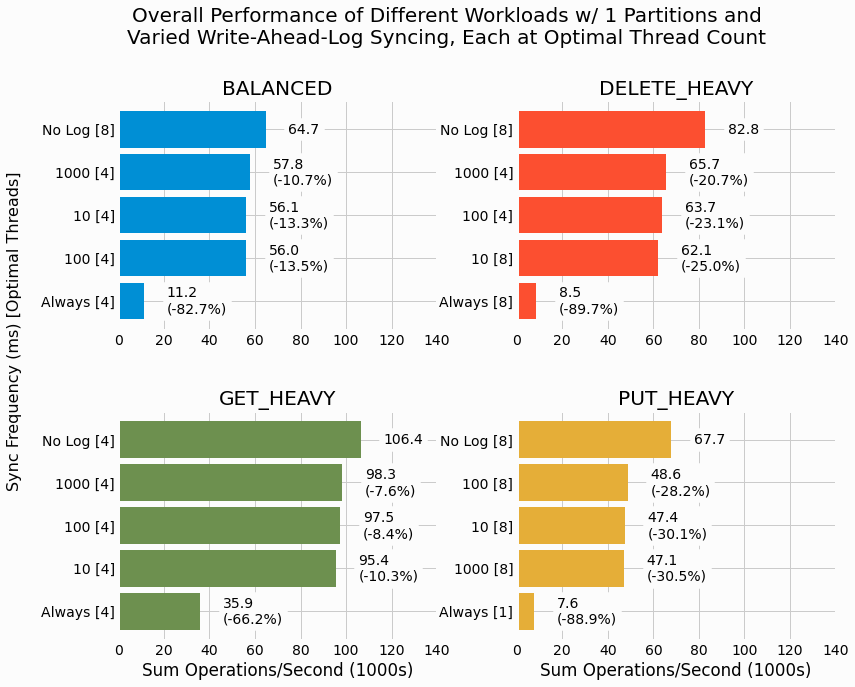
We see massive performance penalties for
Always
syncing WAL with performance drops ranging from
roughly 66% for the
GET_HEAVY
workload to a whopping 90% for
PUT_HEAVY
and
DELETE_HEAVY. It makes sense for the write-heavy workloads to be most strongly impacted. In all cases
the drop in performance is significant with
Always
syncing.
In contrasts, the results for WAL with background syncing show a more modest drop in performance ranging from
roughly 8% for the
GET_HEAVY
workload to 30% for
PUT_HEAVY. This shows that background
syncing can substantially reduce performance degradation relative to immediate syncing. Further, it is interesting
to see that syncing rates has a minor effect on performance and we'll consider why this may be the case in the
discussion section of this project.
Next, we investigate the penalty for WAL when partitioning our LSMTree into 16 independent partitions, each with their own WAL. Since the earlier results show syncing rate to have a minor impact, benchmarks are only performed for the syncing rate of 100ms.
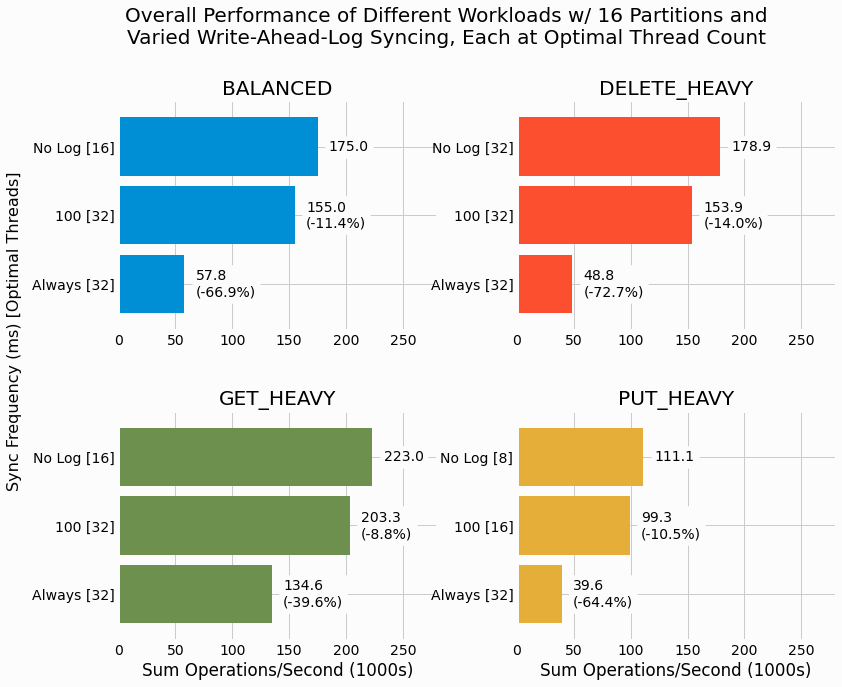
In general, we see that the WAL performance penalty is smaller for the partitioned cases than for the single
partition cases. Further, we still see
Always
syncing results in significantly degraded performance
for all workloads even with partitioning. Syncing in the background significantly improves performance, but still
always under performs the scenarios without WAL. Nonetheless, the drop in performance may certainly be worth the
enhanced data durability for many applications.
Time-Dependent Performance
We also explore the time-dependent performance of our partitioned LSMTree with WAL to gain more insight into how it functions. Results are plotted using the same methods from our previous time-dependent analysis of partitioned LSMTree performance. The following figure shows the time-dependent performance for a BALANCED workload with 16 partitions and 16 threads, with WAL syncing every 100ms.
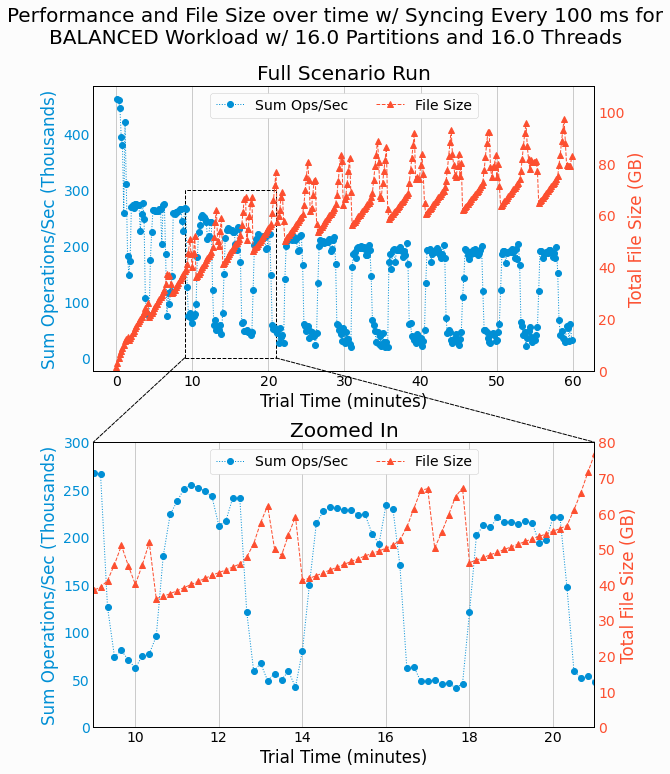
The periodic behavior of performance and file size are similar to what we
previously saw without WAL.
One notable difference is that the periods of fixed file size are replaced by periods of modest growth. These
regions of time correspond to collecting pending writes in memory and the increasing file size correspond to
writing WAL files. We still see periods of rapid increase in disk usage, followed by a drop, as corresponds to
writing delta files and merging deltas and base files into a new base. As before, these regions of time show
degraded performance as attributed to disk usage contention between
GET
operations and IO performed in
writing deltas and merging files.
Next, we repeat this analysis for WAL with
Always
syncing.
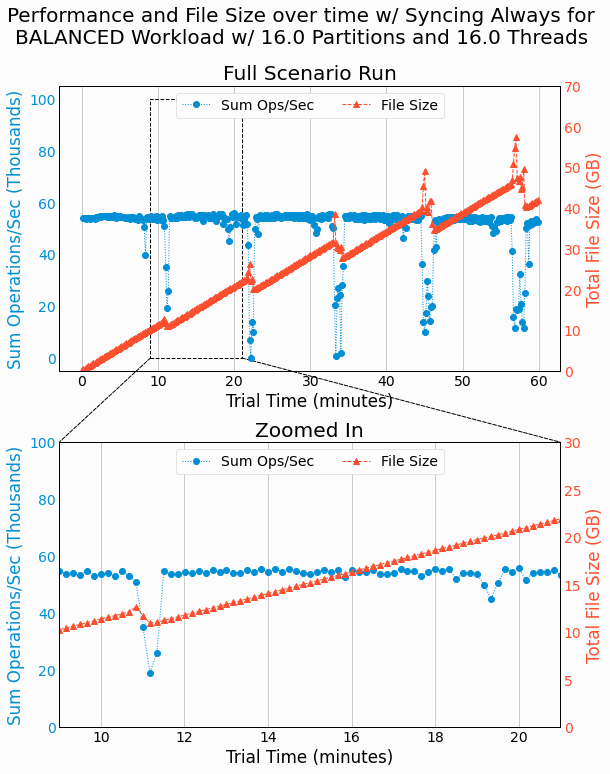
We now see that the periods of slow file growth is extended in duration as corresponds to the longer write
operations that block on syncing the WAL files. We can still see regions of time where deltas are written and
merged with the base as further degrades performance, but these regions of time are less significant on the overall
performance due to the large impact of
Always
syncing on degraded performance.
Discussion and Next Steps
We've added durability to our partitioned LSMTree key/value storage engine by developing WAL, but it comes at
the expense of performance. The performance penalty is modest, on the order of a 10% drop, when WAL syncing is
performed in a background thread at fixed frequency. In contrast, always syncing the WAL after recording a write
results in a massive performance penalty that range from roughly -40% for a
GET_HEAVY
workload with 16
partitions to a massive -90% for a
PUT_HEAVY
or
DELETE_HEAVY
workload with a single
partition.
It is interesting that syncing frequency doesn't noticeably impact performance. I had previously believed that a
write
call would block if a
fsync
call was already in progress for that file handle (
see these results from 2010
).
Our present results suggest that my understanding is incorrect and I unfortunately cannot find anything within
Linux documentation specifying the interaction between
write
and
sync
in different
threads.
The appropriate syncing strategy will depend on the acceptability of lost writes for a given application. For some applications, e.g., financial transactions, we simply cannot accept any data loss and we would require immediate syncing of WAL entries before performing any write operation. Conversely, other applications may be able to accept the risk of minor data loss in return for the enhanced performance of background syncing.
There are more advanced logging strategies that can mitigate some of the expense of WAL. For example, if our byte values corresponded to serialized documents (e.g., json documents) and a write operation only modified a single attribute, then the WAL only need record the change to that attribute. For example, say our key/value store is persisting comments on a social network with the following structure.
{
"8bn73x489732" : {
"comment": "I love this post! Allow me to explain each of the 72 things that I enjoyed...",
"time-posted": "2020-05-09T09:10:52",
"likes": 0
}
}
If someone were to like this comment and our application wants to a increment the
likes
counter,
then a document store may allow an update query of the following form.
UPDATE SET likes=likes + 1 WHERE key = "8bn73x489732";
The WAL need not record the entire new value for this key after performing the update. Instead, it simply needs to record enough information to perform this update in the event of a recovery from crash.
We'll explore and develop document storage with support for partial updates in our next project. This will
unlock additional benefits beyond WAL efficiency, including support for partial
GET
operations and
later table scans and aggregation operations performed on multiple entries of the key/value store. Check out
Document Storage Engine for Semi-Structured Data
to learn how to develop
this more advanced key/value store.