
Log-Structured Merge-Tree for Persistent Reads and Writes
We extend our read-only storage engine for key/value data to support random writes by developing a log-structured merge-tree in this project. We then run benchmarks to quantity its performance in a range of different workloads.
Introduction
In our last project, we introduced persistent storage using disk to develop a read-only storage engine for key/value data. In this project, we add support for random writes, which requires addressing some new challenges in working with disks. You'll learn about the Log-Structured Merge-Tree (LSMTree) data structure and see how it can help us address these challenges. Reusing our read-only key/value store components, we develop an LSMTree-based storage engine for random reads and writes. The new key/value store is benchmarked using high performance NVMe disk drives on EC2 instances and we find the need to run particularly long benchmarks so that we can test the performance on large enough datasets.
You can find the full code for this project within the DBFromZero Java repository on github to read, modify, and run yourself.
Challenges of Supporting Random Writes
We discussed some of the unique challenges in working with disks in our first project using disks. In this project, we encounter a new challenge, how can we modify data in a file? There are interfaces for rewriting a specific segment of a file through Java's RandomAccessFile and more generally using memory-mapped IO. These can be useful in some situations, and we'll explore such situations in future projects, but there's no way to insert data into a middle of a file nor delete a segment of the file.
As you may recall, we previously required our key/value entries to be stored in a sorted order to perform efficient lookups using an index. This worked well when we could generate our entire dataset up front and then only perform random reads. But how can we now support adding new keys or deleting an existing key? Even just changing the value of an existing key can prove problematic if the new value doesn't take up the exact same number of bytes on disk as the previous value.
Addressing These Challenges Using a Log-Structured Merge-Tree (LSMTree)
There are various approaches to supporting modification of data with disk persistence and in this project we explore the Log-Structured Merge-Tree (LSMTree). The core concept of an LSMTree consists of using multiple containers to store entries. These containers have different properties, chiefly storing in memory versus storing on disk, to best suite how each container is used.
A Read-Only Base Container on Disk and a Writable In-Memory Container
One type of container in an LSMTree consists of a read-only file that is sorted and indexed for efficient reads.
To support writes, an LSMTree also uses an in-memory container, generally a hashtable or search tree, that holds
recent writes for a small number of keys. Each write either consists of a
put
request to set the value
for a key or a
delete
request to remove the key and its value (if the key doesn't exist then a
delete
request has no effect). A
get
request for a key first checks this smaller,
in-memory container container for recent writes. If the key isn't found in this container, then the LSMTree
searches the larger, disk-based container. This larger, disk-based container is generally called the base to
signify that it contains older data than the in-memory container.
The LSMTree accumulates these put and delete requests in its smaller, memory-based container until the size of
these writes grows to some configured threshold. It then stores out all of these recent writes to disk. In the
simplest implementation, an LSMTree can sort these writes by key and then use merge sort to combine these updates
with the entries in the base. This results in a new file that combines the data from both containers and it is then
used as the new base. The file associated with the previous base is deleted. In combing, if a key is found in both
containers, then the combing algorithm prefers the value from the in-memory container as that corresponds to a more
recent
put
request for that key. Similarly, if a key residing in the base is found to have a delete
record in the in-memory container then the combined output doesn't contain the key.
Adding Deltas as a Third Type of Container
This simple approach could work, but it would requires the key/value store to become read-only while the combing
is performed and the new base container is generated. A more common approach involves adding a third type of
container called a delta. This file-based container is generated by writing all of the entries in the small,
in-memory container into a new sorted and indexed file. Since the in-memory container consists of a relatively
smaller number of the keys than the base container, these delta files can be written relatively quickly. Then, when
looking up a key for a
get
request, we search through the delta containers in reverse chronological
order (i.e., newest first) after checking the small, in-memory container and before checking the large, base
container.
Not only is it faster to write a delta than to perform a combing with the base, this approach also allows us to
avoid making the key/value store read-only to combine with the base. This is accomplished by using multiple small,
in-memory containers in the LSMTree. When the first container gets large enough for a delta, we create a new one
for subsequent writes, mark the original in-memory container as read-only, and run a background job to write the
original container to a delta. Once the delta has been generated, we can free up the memory of the associated
container. Until the delta has been fully generated, these in-memory, read-only containers have to be searched when
performing
get
requests. Similar to the deltas, the write-pending containers are searched in reverse
chronological order to get the most recent value or delete entry for a key. The overall search order in this
LSMTree goes:
- Search the newest in memory container (the one that allows writes)
- Search the read-only, in-memory, write-pending containers in reverse chronological order
- Search the delta files in reverse chronological order
- Search the base
To reiterate, an LSMtree allows us to create a read/write key/value store by leveraging multiple types of containers for our data; some in-memory and some on disk. Further, this approach uses read-only, disk-based containers of sorted and indexed data. We've already developed code for such containers in a previous project and we can now reuse that component in developing our LSMTree.
Background Merging of Deltas and Base into a New Base
In general, LSMTrees also include a component for merging deltas and the base to enhance read performance. This
consists of a background job that merge delta files with the base to create a new base. Without this, we'd generate
a large number of delta files over time and
get
requests would have to search through them until it
finds one that contains a value or delete request for a key. If we don't have a record for the key, then every file
has to be searched. Further, as keys are updated with new values or deleted, their previous entries are unnecessary
and can be removed to decrease disk usage and create smaller files for faster searching. As with searching in
performing
get
requests, the merging task also needs to prefer more recent deltas over the older
deltas when a key occurs in both and always prefer delta entries over those from the base.
The following diagram shows the various containers and operations associated with the LSMTree described here.

The key thing to remember is that the order of various containers matters when searching for a key or performing a merge. This is necessary to ensure we always have the most recent value for a given key (or delete entry if it was deleted). Note that in merging with deltas to create a new base, we can discard delete entries and just omit the key since these records are only needed to prevent us from searching later containers.
Developing Our LSMTree Storage Engine
In developing an LSMTree-based storage engine, we'll reuse the components we previously developed in the
project,
Disk-Based Storage Engine for Read-Only Key/Value Data,
notably,
KeyValueFileWriter,
IndexBuilder, and
RandomAccessKeyValueFileReader. Additionally, we re-use helpers from earlier projects, including
ByteArrayWrapper.
Helpers for Working with Files/Directories and Locking
We start by developing some helpers for working with files and directories. Specifically, we abstract all of these file system operations behind interfaces. This allows us to use in-memory stand-ins when developing unit tests so that the tests run faster.
Code for
ReadOnlyFileOperations,
FileOperations, and
FileDirectoryOperations.
public interface ReadOnlyFileOperations {
boolean exists();
long length();
InputStream createInputStream() throws IOException;
}
public interface FileOperations<T extends OutputStream> extends ReadOnlyFileOperations {
T createAppendOutputStream() throws IOException;
void sync(T outputStream) throws IOException;
void delete() throws IOException;
OverWriter<T> createOverWriter() throws IOException;
interface OverWriter<T extends OutputStream> {
T getOutputStream();
void commit() throws IOException;
void abort();
}
}
public interface FileDirectoryOperations<S extends OutputStream> {
boolean exists();
List<String> list() throws IOException;
void mkdirs() throws IOException;
void clear() throws IOException;
FileOperations<S> file(String name);
}
Additionally, a helper is developed that wraps a
ReadWriteLock. A
ReadWriteLock
combines two
Lock
instances, one for reads and on for writes. Multiple
threads can hold the read lock concurrently, but only one thread can hold the write lock. Further, the write lock
and read lock are mutually exclusive such that reads are blocked while writing is performed. It is important to
always release a
Lock
after acquiring it and the
ReadWriteLockHelper
removes some of the
try/finally
boiler plate code needed to ensure locks are released after use.
public class ReadWriteLockHelper {
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock(false);
public interface IOCallable<T> {
T call() throws IOException;
}
public interface IORunnable {
void run() throws IOException;
}
public <T> T callWithReadLock(IOCallable<T> callable) throws IOException {
readWriteLock.readLock().lock();
try {
return callable.call();
} finally {
readWriteLock.readLock().unlock();
}
}
public void runWithReadLock(IORunnable runnable) throws IOException {
readWriteLock.readLock().lock();
try {
runnable.run();
} finally {
readWriteLock.readLock().unlock();
}
}
public <T> T callWithWriteLock(IOCallable<T> callable) throws IOException {
readWriteLock.writeLock().lock();
try {
return callable.call();
} finally {
readWriteLock.writeLock().unlock();
}
}
public void runWithWriteLock(IORunnable runnable) throws IOException {
readWriteLock.writeLock().lock();
try {
runnable.run();
} finally {
readWriteLock.writeLock().unlock();
}
}
}
Managing Concurrent Operations on Our Files
We need to carefully coordinate the concurrent operations on the file-based containers that compose our LSMTree.
To that end, the class
BaseDeltaFiles
is developed to manage this coordination. It uses instance level
synchronization to ensure that adding deltas, deleting deltas, and committing a new base are all performed in
isolation. Additionally, it associates a
ReadWriteLockHelper
with each base or delta container to
ensure that this store isn't deleted in one thread while another thread is reading from it. Key methods for
BaseDeltaFiles
are included here and the full code can be found in the repo.
public class BaseDeltaFiles<T extends OutputStream> {
private final FileDirectoryOperations<T> directoryOperations;
private final FileOperations<T> baseOperations;
private final FileOperations<T> baseIndexOperations;
private final TreeMap<Integer, ReaderWrapper> orderedInUseDeltas = new TreeMap<>();
private ReaderWrapper baseWrapper;
private int nextDelta = 0;
...
// ordered oldest to newest
public synchronized List<Integer> getOrderedDeltasInUse() {
return new ArrayList<>(orderedInUseDeltas.keySet());
}
@Nullable public ByteArrayWrapper searchForKey(ByteArrayWrapper key) throws IOException {
Preconditions.checkState(hasInUseBase());
List<ReaderWrapper> orderedDeltas;
synchronized (this) {
orderedDeltas = new ArrayList<>(orderedInUseDeltas.values());
}
// prefer the newer deltas over older ones and finally the base
var deltaValue = recursivelySearchDeltasInReverse(orderedDeltas.iterator(), key);
if (deltaValue != null) {
return deltaValue;
}
return baseWrapper.lock.callWithReadLock(() -> baseWrapper.reader.get(key));
}
@Nullable private ByteArrayWrapper recursivelySearchDeltasInReverse(Iterator<ReaderWrapper> iterator,
ByteArrayWrapper key) throws IOException {
if (!iterator.hasNext()) {
return null;
}
var wrapper = iterator.next();
var result = recursivelySearchDeltasInReverse(iterator, key);
if (result != null) {
return result;
}
// note that it is possible the delta was deleted while we were searching other deltas or
// while we were waiting for the read lock.
// that is fine because now the delta is in the base and we always search the deltas first
// so if the key was in the delta then we'll find it when we search the base
return wrapper.lock.callWithReadLock(() -> wrapper.reader == null ? null : wrapper.reader.get(key));
}
// these three methods should only be called by the delta writer coordinator
void setBase() throws IOException {
LOGGER.info("Setting initial base");
Preconditions.checkState(!hasInUseBase());
// delay acquiring lock until we've read in the index
var reader = createRandomAccessReader(baseOperations, baseIndexOperations);
synchronized (this) {
baseWrapper = new ReaderWrapper(reader);
}
}
synchronized int allocateDelta() {
return nextDelta++;
}
synchronized void addDelta(Integer delta) throws IOException {
LOGGER.info("Adding delta " + delta);
Preconditions.checkState(hasInUseBase());
orderedInUseDeltas.put(delta, new ReaderWrapper(createRandomAccessReader(getDeltaOperations(delta), getDeltaIndexOperations(delta))));
}
// these three methods should only be called by the merger cron
RandomAccessKeyValueFileReader getBaseReaderForMerge() {
Preconditions.checkState(hasInUseBase());
return baseWrapper.reader;
}
void commitNewBase(FileOperations.OverWriter<T> baseOverWriter,
FileOperations.OverWriter<T> baseIndexOverWriter) throws IOException {
LOGGER.info("Committing new base");
Preconditions.checkState(hasInUseBase());
// this operation can take a non-trivial amount of time since we have to read the index
// ideally we could load the index from temp file or keep it in memory while writing, but
// I don't think that is a worthwhile optimization, although it will cause all other base
// operations to block
baseWrapper.lock.runWithWriteLock(() -> {
baseOverWriter.commit();
baseIndexOverWriter.commit();
baseWrapper.reader = createRandomAccessReader(baseOperations, baseIndexOperations);
});
}
public void deleteDelta(Integer delta) throws IOException {
LOGGER.info("Deleting delta " + delta);
ReaderWrapper wrapper;
synchronized (this) {
wrapper = orderedInUseDeltas.remove(delta);
}
Preconditions.checkArgument(wrapper != null, "No such delta " + delta + " in use");
wrapper.lock.runWithWriteLock(() -> {
wrapper.reader = null; // mark the reader as deleted incase a read lock is acquired after this
getDeltaOperations(delta).delete();
getDeltaIndexOperations(delta).delete();
});
}
...
private static class ReaderWrapper {
@Nullable private RandomAccessKeyValueFileReader reader;
private final ReadWriteLockHelper lock = new ReadWriteLockHelper();
private ReaderWrapper(@NotNull RandomAccessKeyValueFileReader reader) {
this.reader = Preconditions.checkNotNull(reader);
}
}
}
A Job For Sorting, Indexing, and Writing a Delta
Next, a component is developed for writing a delta container file from a collection of in-memory writes.
WriteSortedEntriesJob
takes a
Map
of recent writes, sort the entries by keys, and then
writes a key/value delta file with an index. The class extends
Runnable
so that it can be ran in
separate thread and special care is taken to abort the write if an
IOException
is encountered.
public class WriteSortedEntriesJob<T extends OutputStream> implements Runnable {
private final String name;
private final boolean isBase;
private final int delta;
private final int indexRate;
private final Map<ByteArrayWrapper, ByteArrayWrapper> writes;
private final FileOperations<T> fileOperations;
private final FileOperations<T> indexFileOperations;
private final DeltaWriterCoordinator<T> coordinator;
...
@Override public void run() {
FileOperations.OverWriter<T> overWriter = null, indexOverWriter = null;
try {
LOGGER.info(() -> "Sorting " + writes.size() + " writes for " + name);
var sortedEntries = new ArrayList<>(writes.entrySet());
sortedEntries.sort(Map.Entry.comparingByKey());
overWriter = fileOperations.createOverWriter();
indexOverWriter = indexFileOperations.createOverWriter();
try (var outputStream = new PositionTrackingStream(overWriter.getOutputStream(), IO_BUFFER_SIZE)) {
try (var indexWriter = new KeyValueFileWriter(
new BufferedOutputStream(indexOverWriter.getOutputStream(), IO_BUFFER_SIZE))) {
var indexBuilder = IndexBuilder.indexBuilder(indexWriter, indexRate);
try (var writer = new KeyValueFileWriter(outputStream)) {
for (var entry : sortedEntries) {
indexBuilder.accept(outputStream.getPosition(), entry.getKey());
writer.append(entry.getKey(), entry.getValue());
}
}
}
}
overWriter.commit();
indexOverWriter.commit();
coordinator.commitWrites(this);
} catch (Exception e) {
LOGGER.log(Level.SEVERE, e, () -> "error in writing sorted file for " + name);
if (overWriter != null) {
overWriter.abort();
}
if (indexOverWriter != null) {
indexOverWriter.abort();
}
coordinator.abortWrites(this);
}
}
}
Additionally, a
DeltaWriterCoordinator
class is developed for managing multiple concurrent
WriteSortedEntriesJob
instances. It limits the maximum number of concurrent writes jobs to a
configured limits and also handles the committing of deltas into the
BaseDeltaFiles. This includes
ensuring that we have an initial base before writing any deltas. Lastly, it provides the method
searchForKeyInWritesInProgress
to check if a key is contained in any in-progress writes as needed for
our LSMTree. As required, this method searches deltas in reverse chronological order so that more recent entries
for a key are preferred to later entries.
public class DeltaWriterCoordinator<T extends OutputStream> {
private static final Logger LOGGER = Dbf0Util.getLogger(DeltaWriterCoordinator.class);
private enum State {
UNINITIALIZED,
WRITING_BASE,
WRITE_DELTAS
}
private final BaseDeltaFiles<T> baseDeltaFiles;
private final int maxInFlightWriters;
private final int indexRate;
private final LinkedList<WriteSortedEntriesJob<T>> inFlightWriters = new LinkedList<>();
private final ScheduledExecutorService executor;
private int writersCreated = 0;
private boolean anyWriteAborted = false;
private State state = State.UNINITIALIZED;
...
boolean anyWritesAborted() {
return anyWriteAborted;
}
synchronized boolean hasMaxInFlightWriters() {
return inFlightWriters.size() == maxInFlightWriters;
}
synchronized void addWrites(Map<ByteArrayWrapper, ByteArrayWrapper> writes) {
Preconditions.checkState(!hasMaxInFlightWriters());
writes = Collections.unmodifiableMap(writes);
if (state == State.UNINITIALIZED) {
if (baseDeltaFiles.hasInUseBase()) {
state = State.WRITE_DELTAS;
} else {
LOGGER.info("Creating new base for writes");
Preconditions.checkState(!baseDeltaFiles.baseFileExists());
state = State.WRITING_BASE;
createWriteJob(true, -1, writes, baseDeltaFiles.getBaseOperations(),
baseDeltaFiles.getBaseIndexOperations());
return;
}
}
LOGGER.info("Creating new delta for writes");
var delta = baseDeltaFiles.allocateDelta();
createWriteJob(false, delta, writes, baseDeltaFiles.getDeltaOperations(delta),
baseDeltaFiles.getDeltaIndexOperations(delta));
}
@Nullable synchronized ByteArrayWrapper searchForKeyInWritesInProgress(ByteArrayWrapper key) {
Preconditions.checkState(executor != null, "not initialized");
// search the newest writes first
var iterator = inFlightWriters.descendingIterator();
while (iterator.hasNext()) {
var writer = iterator.next();
var value = writer.getWrites().get(key);
if (value != null) {
return value;
}
}
return null;
}
private synchronized void createWriteJob(boolean isBase, int delta,
Map<ByteArrayWrapper, ByteArrayWrapper> writes,
FileOperations<T> fileOperations,
FileOperations<T> indexFileOperations) {
var job = new WriteSortedEntriesJob<>("write" + writersCreated++,
isBase, delta, indexRate, writes, fileOperations, indexFileOperations, this);
inFlightWriters.add(job);
executor.execute(job);
}
synchronized void commitWrites(WriteSortedEntriesJob<T> writer) throws IOException {
if (anyWriteAborted) {
LOGGER.warning("Not committing " + writer.getName() + " since an earlier writer aborted");
abortWrites(writer);
return;
}
if (state == State.WRITING_BASE && !writer.isBase()) {
// we cannot write a delta before writing the base so wait
LOGGER.info(() -> "Writer " + writer.getName() + " finished before the initial base finished. " +
"Will re-attempt to commit this later");
executor.schedule(() -> reattemptCommitWrites(writer, 1), 1, TimeUnit.SECONDS);
return;
}
try {
if (state == State.WRITING_BASE) {
Preconditions.checkState(writer.isBase());
baseDeltaFiles.setBase();
state = State.WRITE_DELTAS;
} else {
Preconditions.checkState(state == State.WRITE_DELTAS);
baseDeltaFiles.addDelta(writer.getDelta());
}
var removed = inFlightWriters.remove(writer);
Preconditions.checkState(removed);
} catch (Exception e) {
LOGGER.log(Level.SEVERE, e, () -> "error in committing writes. aborting");
abortWrites(writer);
}
}
...
synchronized void abortWrites(WriteSortedEntriesJob<T> writer) {
anyWriteAborted = true;
LOGGER.warning("Aborting " + writer.getName());
var removed = inFlightWriters.remove(writer);
Preconditions.checkState(removed);
}
}
A Cron to Merge Deltas and the Base
Our LSMTree will include a background job for merging deltas and the base to create a new combined base. The
developed
BaseDeltaMergerCron
class uses a
ScheduledExecutorService
to check for new deltas at a configured frequency. It can merge multiple deltas with a base in one run and it has a
configurable parameter
maxDeltaReadPercentage
to limit the number of deltas merged at once. This
prevents any single merging run from taking too long.
public class BaseDeltaMergerCron<T extends OutputStream> {
...
private final BaseDeltaFiles<T> baseDeltaFiles;
private final double maxDeltaReadPercentage;
private final Duration checkForDeltasRate;
private final int baseIndexRate;
private final ScheduledExecutorService executor;
private boolean started = false;
private boolean shutdown = false;
private boolean hasError = false;
private ScheduledFuture<?> checkFuture;
...
public boolean hasErrors() {
return hasError;
}
public synchronized void start() {
Preconditions.checkState(!started);
checkFuture = executor.schedule(this::checkForDeltas, 0, TimeUnit.SECONDS);
started = true;
}
public synchronized void shutdown() {
if (!started || shutdown) {
return;
}
if (checkFuture != null) {
checkFuture.cancel(true);
}
shutdown = true;
}
private void checkForDeltas() {
if (shutdown || hasError) {
return;
}
try {
checkForDeltasInternal();
synchronized (this) {
if (!shutdown) {
checkFuture = executor.schedule(this::checkForDeltas, checkForDeltasRate.toMillis(), TimeUnit.MILLISECONDS);
}
}
} catch (Exception e) {
LOGGER.log(Level.SEVERE, e, () -> "error in " + getClass().getSimpleName() + ". shutting down");
hasError = true;
checkFuture = null;
shutdown();
}
}
private void checkForDeltasInternal() throws IOException {
var orderedDeltasInUse = baseDeltaFiles.getOrderedDeltasInUse();
if (orderedDeltasInUse.isEmpty()) {
LOGGER.finer(() -> "no deltas in use");
return;
}
LOGGER.fine(() -> "ordered deltas in use " + orderedDeltasInUse);
Preconditions.checkState(baseDeltaFiles.hasInUseBase());
var baseOperations = baseDeltaFiles.getBaseOperations();
var baseSize = baseOperations.length();
var maxDeltaSize = (long) ((double) baseSize * maxDeltaReadPercentage / (1 - maxDeltaReadPercentage));
LOGGER.fine(() -> "base size " + Dbf0Util.formatBytes(baseSize) +
" max delta size " + Dbf0Util.formatBytes(maxDeltaSize));
var orderedDeltaOpsForMerge = collectDeltaOpsForMerge(orderedDeltasInUse, maxDeltaSize);
mergeDeltasAndCommit(orderedDeltaOpsForMerge);
for (var deltaPair : orderedDeltaOpsForMerge) {
baseDeltaFiles.deleteDelta(deltaPair.getKey());
}
}
...
}
A key component used by our
BaseDeltaMergerCron
is the
ValueSelectorIterator. This
class handles selecting the newest record for a key when multiple records exist for the key. It accomplishes this
by decorating each key/value entry from a container store with an rank denoting the order of the container from
which it was read. Newer containers are associated with higher rank. It then uses the guava routine
Iterators.mergeSorted
to combine multiple iterators, each representing a sorted sequence of key/value
pairs from a container store, into a single sorted
Iterator. Lastly, it consumes
this merged-sorted iterator using a
PeekingIterator
to assist in grouping together all records for the
same key. While processing a group, it selects the value with the highest rank entry.
class ValueSelectorIterator implements Iterator<Pair<ByteArrayWrapper, ByteArrayWrapper>> {
private final PeekingIterator<KeyValueRank> sortedIterator;
ValueSelectorIterator(Iterator<KeyValueRank> sortedIterator) {
this.sortedIterator = Iterators.peekingIterator(sortedIterator);
}
@Override public boolean hasNext() {
return sortedIterator.hasNext();
}
@Override public Pair<ByteArrayWrapper, ByteArrayWrapper> next() {
var first = sortedIterator.next();
var key = first.key;
var highestRank = first.rank;
var highestRankValue = first.value;
while (sortedIterator.hasNext() && sortedIterator.peek().key.equals(key)) {
var entry = sortedIterator.next();
if (entry.rank > highestRank) {
highestRank = entry.rank;
highestRankValue = entry.value;
}
}
return Pair.of(key, highestRankValue);
}
static ValueSelectorIterator createSortedAndSelectedIterator(List<KeyValueFileReader> orderedReaders) {
var rankedIterators = StreamUtils.zipWithIndex(orderedReaders.stream()
.map(KeyValueFileIterator::new))
.map(indexedIterator ->
addRank(indexedIterator.getValue(), (int) indexedIterator.getIndex()))
.collect(Collectors.toList());
var mergeSortedIterator = Iterators.mergeSorted(rankedIterators,
Comparator.comparing(KeyValueRank::getKey));
return new ValueSelectorIterator(mergeSortedIterator);
}
static Iterator<KeyValueRank> addRank(Iterator<Pair<ByteArrayWrapper, ByteArrayWrapper>> iterator, int rank) {
return Iterators.transform(iterator, pair -> new KeyValueRank(pair.getKey(), pair.getValue(), rank));
}
static class KeyValueRank {
final ByteArrayWrapper key;
final ByteArrayWrapper value;
final int rank;
KeyValueRank(ByteArrayWrapper key, ByteArrayWrapper value, int rank) {
this.key = key;
this.value = value;
this.rank = rank;
}
ByteArrayWrapper getKey() {
return key;
}
}
}
Putting It All Together Into Our LSM Tree
Now we can combine our
DeltaWriterCoordinator,
DeltaWriterCoordinator, and
BaseDeltaMergerCron
to create our
LsmTree. This class implements the
ReadWriteStorage<K, V>
interface with the following methods.
public interface ReadWriteStorage<K, V> {
void put(@NotNull K key, @NotNull V value) throws IOException;
@Nullable V get(@NotNull K key) throws IOException;
boolean delete(@NotNull K key) throws IOException;
}
Our
LsmTree
uses a
ReadWriteLockHelper
to guard against concurrent modification of the
writes that it collects in memory within
pendingWrites. When looking up a key for a
get
request it searches the various containers that could contain the key in the appropriate order. Additionally, all
of the
LSMTree
API methods check if any error has occurred in its background tasks using the method
isUsable()
as errors correspond to data corruption.
public class LsmTree<T extends OutputStream>
implements CloseableReadWriteStorage<ByteArrayWrapper, ByteArrayWrapper> {
// randomly generated value. contains 16-bytes to make it near statistically impossible for any other
// byte array to every contain these identical values.
static final ByteArrayWrapper DELETE_VALUE = ByteArrayWrapper.of(
83, 76, 69, 7, 95, 21, 81, 27, 2, 104, 8, 100, 45, 109, 110, 1);
private final int pendingWritesDeltaThreshold;
private final BaseDeltaFiles<T> baseDeltaFiles;
private final DeltaWriterCoordinator<T> coordinator;
private final BaseDeltaMergerCron<T> mergerCron;
private final ExecutorService executorService;
private final ReadWriteLockHelper lock = new ReadWriteLockHelper();
private Map<ByteArrayWrapper, ByteArrayWrapper> pendingWrites = new HashMap<>();
...
public void initialize() throws IOException {
mergerCron.start();
}
@Override public void close() throws IOException {
mergerCron.shutdown();
executorService.shutdownNow();
}
public boolean isUsable() {
return !coordinator.anyWritesAborted() && !mergerCron.hasErrors();
}
@Override public void put(@NotNull ByteArrayWrapper key, @NotNull ByteArrayWrapper value) throws IOException {
Preconditions.checkState(isUsable());
var writesBlocked = lock.callWithWriteLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
pendingWrites.put(key, value);
return checkMergeThreshold();
});
if (writesBlocked) {
waitForWritesToUnblock();
}
}
@Nullable @Override public ByteArrayWrapper get(@NotNull ByteArrayWrapper key) throws IOException {
Preconditions.checkState(isUsable());
// search through the various containers that could contain the key in the appropriate order
var value = lock.callWithReadLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
return pendingWrites.get(key);
});
if (value != null) {
return checkForDeleteValue(value);
}
value = coordinator.searchForKeyInWritesInProgress(key);
if (value != null) {
return checkForDeleteValue(value);
}
if (!baseDeltaFiles.hasInUseBase()) {
return null;
}
value = baseDeltaFiles.searchForKey(key);
return value == null ? null : checkForDeleteValue(value);
}
@Override public boolean delete(@NotNull ByteArrayWrapper key) throws IOException {
Preconditions.checkState(isUsable());
var writesBlocked = lock.callWithWriteLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
pendingWrites.put(key, DELETE_VALUE);
return checkMergeThreshold();
});
if (writesBlocked) {
waitForWritesToUnblock();
}
return true;// doesn't actually return a useful value
}
// only to be called when holding the write lock
private boolean checkMergeThreshold() throws IOException {
if (pendingWrites.size() < pendingWritesDeltaThreshold) {
return false;
}
if (coordinator.hasMaxInFlightWriters()) {
return true;
}
coordinator.addWrites(pendingWrites);
pendingWrites = new HashMap<>();
return false;
}
...
}
Unit Testing Our LSMTree
In previously projects, I had us largely skip any testing for correctness. In doing so, I've been remiss in practicing my duties as a software engineer. After all, what is the point in doing all this work to develop and benchmark database components if the end result is buggy. See this blog posts for more about my new commitment to developing tests.
The class
ReadWriteStorageTester<K, V>
is developed as general purpose tester for any
ReadWriteStorage<K, V>
to run extensive sanity checks against the store. It performs a random
sequence of 'put', 'get', and 'delete' operations on a
ReadWriteStorage<K, V>
instance. It also
performs these operations on a companion
Map<K, V>
and compares the results of the tested
storage engine against the companion map, asserting for correctness. Here's an example of using the
ReadWriteStorageTester<K, V>
in testing.
@Test public void testSingleThreaded() throws IOException {
var tree = createLsmTree(1000);
var tester = ReadWriteStorageTester.builderForBytes(tree, RandomSeed.CAFE.random(), 16, 4096)
.debug(true)
.checkDeleteReturnValue(false)
.checkSize(false)
.build();
tester.testPutDeleteGet(10 * 1000, PutDeleteGet.BALANCED, KnownKeyRate.MID);
}
Test-cases also include multi-threaded operations to check for any bugs in concurrency.
Benchmarking
With our
LSMTree
developed and thoroughly tested, we now move on to benchmarking its performance in
a variety of different scenarios.
First, we consider the relatively frequency of
Put,
Delete, and
Get
requests. The following workloads are considered to explore scenarios that are heavy in each request type, as well
as a balanced mix.
| Operation Frequency (%) | |||
|---|---|---|---|
| Workload | Put | Delete | Get |
| PUT_HEAVY | 90 | 5 | 5 |
| GET_HEAVY | 10 | 5 | 85 |
| DELETE_HEAVY | 45 | 45 | 10 |
| BALANCED | 33 | 33 | 34 |
Additionally, the following parameters are varied to explore a variety of scenarios.
-
Key Find Rate
- The rate at which
DeleteandGetrequests use a key from a previousPutrequest, versus a randomly generated key- 10% : Low
- 50% : Mid
- 90% : High
-
Write Delta Threshold
- The number of keys to collect in memory before writing them as a delta
- 100,000 - Frequent deltas
- 1,000,000 - Infrequent deltas
-
Key Space Size
- The length of key byte-arrays is varied to control the number of possible
unique keys. Larger key spaces are expected to result in a larger dataset.
- 10 Million - Small
- 100 Million - Medium
- 1 Billion - Large
- Thread Count - The number of threads concurrently performing operations against our LSMTree storage engine. Values of 1 , 4 , 16 , and 64 are considered.
Note that thread count doesn't include threads used to write deltas or the thread used to run the background delta/based merger cron.
During the benchmarking run, we count the total number of
Put,
Delete, and
Get
requests to quantify performance. Each benchmarking trial begins with zero entries in the
key/value store and the data size grows over time. Hence, we run longer duration benchmarks than in previous
projects and chose to run each benchmark for one hour. In addition to counting the number of operations performed,
we also record the final size of all of the files used by LSMTree at the end of benchmarks.
AWS EC2 instances with high-performance NVMe drives are used provide a standard testing environment and to allow us to run multiple benchmark runs in parallel using multiple instances. Only one benchmark trial is ran at a time on each instance to prevent them from competing with each other for resources. We use the same instance type as previously used in benchmarking our read-only storage engine so that the results can be compared.
| Attribute | Value |
|---|---|
| Instance Type | i3.2xlarge |
| Provisioned Input/Output Ops/Second (IOPs) | 180,000 |
| vCPUs | 8 |
| RAM | 61 GiB |
| OS Image | Ubuntu 18.04 LTS - Bionic |
| Kernel | Linux version 4.15.0-1065-aws |
| JRE | OpenJDK 64-Bit Server VM version 11.0.6 |
The following benchmarking harness is developed to run benchmarking trials. Since it shares similarities to benchmarking code in previous projects, only selects details are included here for brevity.
public class Benchmark {
public static void main(String[] args) throws Exception {
var argsItr = Arrays.asList(args).iterator();
var directory = new File(argsItr.next());
var keySpaceSize = Integer.parseInt(argsItr.next());
var valueLength = Integer.parseInt(argsItr.next());
var putDeleteGet = PutDeleteGet.valueOf(argsItr.next());
var knownKeyRate = Double.parseDouble(argsItr.next());
var threadCount = Integer.parseInt(argsItr.next());
var duration = Duration.parse(argsItr.next());
var storage = createLsmTree(argsItr, directory);
var stats = new Stats();
var errors = new AtomicInteger(0);
var threads = IntStream.range(0, threadCount).mapToObj(i ->
new Thread(() -> runOperations(keySpaceSize, valueLength, putDeleteGet,
knownKeyRate, storage, stats, errors)))
.collect(Collectors.toList());
threads.forEach(Thread::start);
waitDuration(duration, stats, errors, directory);
threads.forEach(Thread::interrupt);
for (var thread : threads) {
thread.join();
}
System.out.println(stats.toJson());
}
private static LsmTree<FileOutputStream> createLsmTree(Iterator<String> argsItr, File directory)
throws IOException {
var pendingWritesMergeThreshold = Integer.parseInt(argsItr.next());
var indexRate = Integer.parseInt(argsItr.next());
var directoryOps = new FileDirectoryOperationsImpl(directory);
directoryOps.mkdirs();
directoryOps.clear();
var tree = LsmTree.builderForDirectory(directoryOps)
.withPendingWritesDeltaThreshold(pendingWritesMergeThreshold)
.withScheduledThreadPool(4)
.withIndexRate(indexRate)
.withMaxInFlightWriteJobs(20)
.withMaxDeltaReadPercentage(0.75)
.withMergeCronFrequency(Duration.ofSeconds(1))
.build();
tree.initialize();
return tree;
}
private static void runOperations(int keySpaceSize, int valueLength, PutDeleteGet putDeleteGet,
double knownKeyRate,
ReadWriteStorage<ByteArrayWrapper, ByteArrayWrapper> storage,
Stats stats, AtomicInteger errors) {
try {
var random = new Random();
var keyTracker = new KeyTracker(random);
Supplier<ByteArrayWrapper> getDelKeyGenerate = () -> {
var known = (!keyTracker.isEmpty()) && random.nextDouble() < knownKeyRate;
return known ? keyTracker.select() : randomKey(random, keySpaceSize);
};
while (!Thread.interrupted()) {
var operation = putDeleteGet.select(random);
switch (operation) {
case PUT:
var key = randomKey(random, keySpaceSize);
storage.put(key, ByteArrayWrapper.random(random, valueLength));
keyTracker.add(key);
stats.countPut.incrementAndGet();
break;
case GET:
var value = storage.get(getDelKeyGenerate.get());
stats.countGet.incrementAndGet();
if (value != null) {
stats.countFound.incrementAndGet();
}
break;
case DELETE:
var deleted = storage.delete(getDelKeyGenerate.get());
stats.countDelete.incrementAndGet();
if (deleted) {
stats.countDeleteFound.incrementAndGet();
}
break;
default:
throw new RuntimeException("Unsupported operation " + operation);
}
}
} catch (InterruptedExceptionWrapper e) {
LOGGER.log(Level.WARNING, e, () ->
"interruption in store operations. assuming end of benchmark and exiting normally");
} catch (Exception e) {
errors.incrementAndGet();
LOGGER.log(Level.SEVERE, e, () -> "failure in thread");
}
}
Due to resource constraints, only a single trial is performed for each benchmarked scenario and further we don't consider every possible parameter combination, but instead explore a selection of parameter combinations to provide a broad overview of the impact of each parameter. In total, 154 scenarios are benchmarked.
Analysis of Benchmarking Results
Highest and Lowest Performing Scenarios
We begin our analysis by looking at the top five performing scenarios as quantified by the sum operations per a
second, with the sum being over
put,
get, and
delete
operation counts.
| Top Performing Scenarios | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Benchmarking Scenario | Operations per a Second (Thousands) | Final Data Size (GB) | |||||||
| Workload | Key Find Rate (%) | Threads | Write Delta Threshold (100,000s) | Key Space Size (Millions) | Put | Delete | Get | Sum | |
| GET_HEAVY | 90 | 4 | 10 | 10 | 32.85 | 16.420 | 279.170 | 328.44 | 16.3 |
| DELETE_HEAVY | 90 | 4 | 10 | 10 | 143.41 | 143.410 | 31.870 | 318.69 | 21.9 |
| PUT_HEAVY | 50 | 4 | 10 | 10 | 183.30 | 10.185 | 10.185 | 203.67 | 23.8 |
| GET_HEAVY | 90 | 1 | 10 | 10 | 18.70 | 9.350 | 158.970 | 187.02 | 9.9 |
| BALANCED | 90 | 16 | 10 | 10 | 57.29 | 57.300 | 59.040 | 173.63 | 10.1 |
It is exciting to see that we can achieve performance as high 328,000 operations/second! Among these top performing scenarios we see a mix of workload, yet all five have the larger delta writing threshold of 1,000,000 and all five also consider the smallest key space size of only ten million possible unique keys. Four of the top five scenarios use the highest key find rate of 90% and we'll consider why that may be the case in the discussion section of this project. It is also interesting that the top three use a relatively small number of threads, with only 4, and the fourth highest performing scenario only uses a single thread for perform operations on our LSMTree.
Similarly, we also investigate the five lowest performing scenarios.
| Lowest Performing Scenarios | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Benchmarking Scenario | Operations per a Second (Thousands) | Final Data Size (GB) | |||||||
| Workload | Key Find Rate (%) | Threads | Write Delta Threshold (100,000s) | Key Space Size (Millions) | Put | Delete | Get | Sum | |
| GET_HEAVY | 10 | 1 | 1 | 1000 | 2.11 | 1.06 | 17.960 | 21.130 | 7.8 |
| PUT_HEAVY | 10 | 1 | 1 | 100 | 18.47 | 1.03 | 1.030 | 20.530 | 81.4 |
| DELETE_HEAVY | 10 | 1 | 1 | 1000 | 9.23 | 9.23 | 2.050 | 20.510 | 49.8 |
| BALANCED | 10 | 64 | 1 | 1000 | 6.63 | 6.63 | 6.830 | 20.090 | 32.5 |
| BALANCED | 10 | 1 | 1 | 100 | 5.78 | 5.78 | 5.955 | 17.515 | 22.8 |
Here we see performance dropping by roughly an order of magnitude relative to the highest performing scenarios. All five are found to occur with the lowest key find rate of 10% and also have more frequent deltas with a delta write threshold of 100,000. Four of these scenarios are single threaded and the one outlier uses the largest thread count of 64. Lastly, we see that all of these lower performing scenarios consider either the medium or larger key space size of either 100 million or a billion possible keys.
Impact of Key Space Size and Data Files Size
Seeing as key space size is found to be important, we next check how key space is correlated to the final size of the LSMTree data files at the end of each one hour benchmarking trial. The following figure groups scenarios together by key space size and show the distribution of data files size using a box plot. Each bar shows the interquartile range; i.e., 25th percentile to 75th percentile. Medians are denoted by horizontal lines and outliers are shown as single data points.
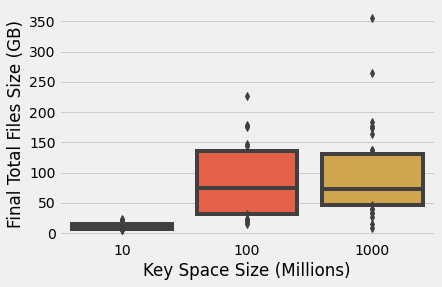
We immediately see that key space size and final sum file size is related. The smallest key space of 10 million possible keys results in a median data size of only 10 GB. Further, there is a relatively small spread of results for this smaller key space as suggests the majority of the benchmarks reach some maximum data size containing the mass majority of possible keys.
In contrast, the medium and larger key spaces result in median final data sizes of roughly 75GB. The similarity in the medians for these two different key spaces suggests that the data size is limited by the duration of the benchmarking trials and longer benchmarks would result in larger data sizes as more unique keys are added. Additionally, these two key spaces are each also found to have a wider distribution of data sizes and both also show significant outliers.
We next investigate how data file size is related to performance by generating a scatter plot of all trials with file size on the horizontal axis and sum operations/second shown on the vertical axis. Two different color coding schemes are used to differentiate trials. In the first axes, trial points are color coded by key space size. In the second, different workloads are denoted by marker color. Points are rendered partially transparent to better show where there is significant overlap.
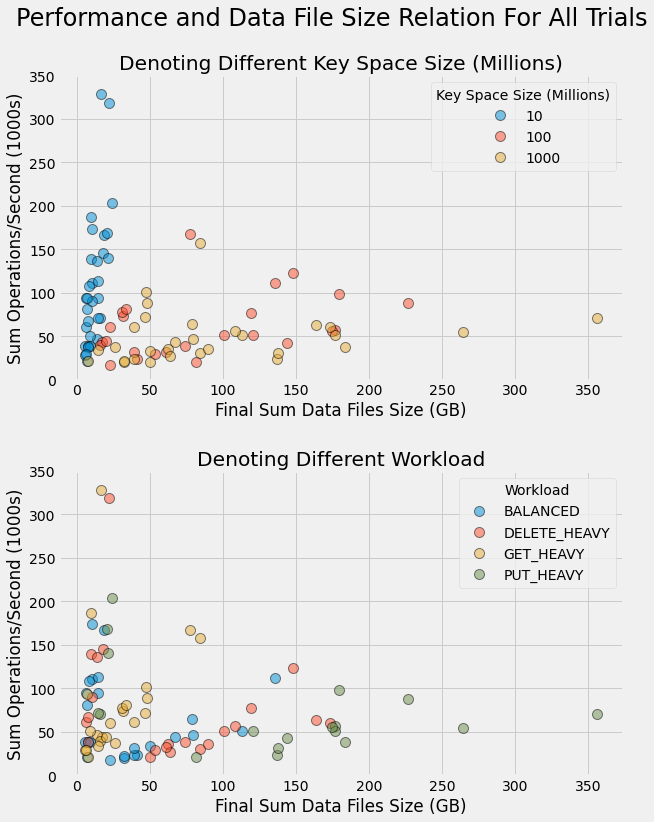
In the first axes we can clearly see how the smaller key space leads to both smaller final data file sizes and
higher performance. In looking at the second axes and cross referencing it with the first, we can see how there is
a mix of different workloads with varying performance for the smaller key space size. In contrast, we can see a
differentiation of the workloads for the larger key space sizes. As one may expect, the largest final data file
sizes are found with
PUT_HEAVY
workloads.
Effect of Each Individual Parameters on Performance
Lastly, we investigate the impact of each individual parameter on the total performance of our LSTree as quantified by the sum operations per a second. For each parameter, we group by different values of the parameter and then show the distribution of trials for each parameter value using a box plot.
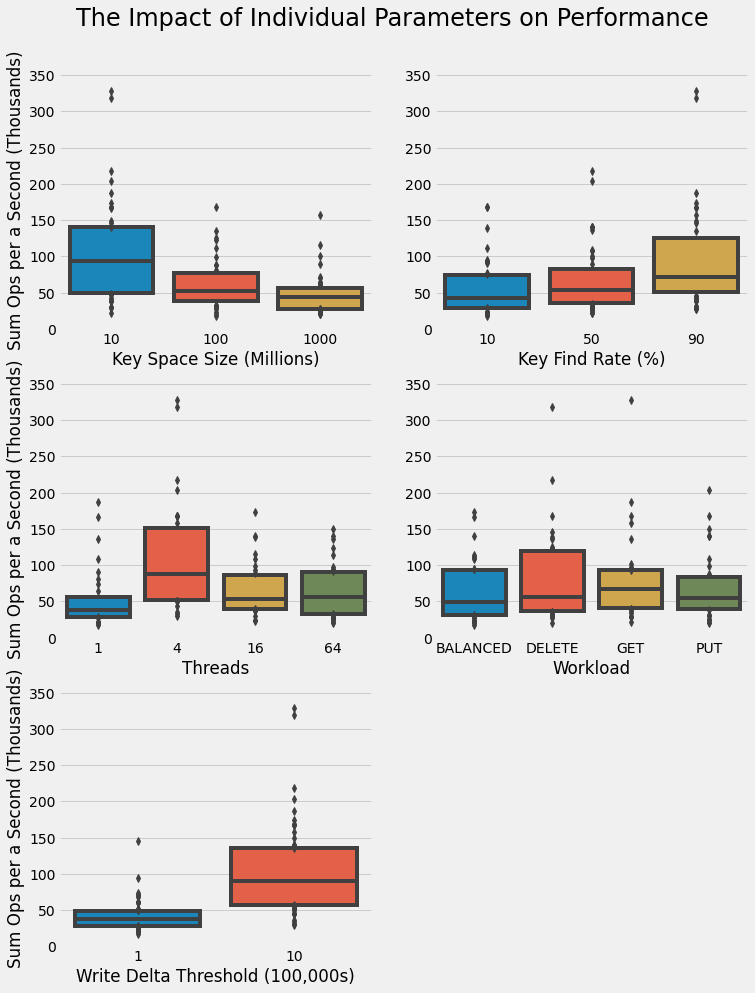
The key space size axes reiterated what we've already seen; higher performance is seen with the smaller key size as we know leads to smaller data size. We also once again see that higher key find rates and larger delta write thresholds result in higher overall performance. Interestingly, we find that four is the optimal number of threads performing concurrent operations on our LSMTree. This might suggest lock contention with a larger number of threads. Again, we see that there isn't substantial differentiation in the results for different types of workloads. All workloads show substantial outliers, as we know corresponds to the smaller key space size and thereby smaller data file size.
Discussion and Next Steps
In this project, we've added support for random writes in a persistent key/value store by using an LSMTree to address the challenges of adding and deleting entries in a disk-based data store. The technique that we've adopted is also used in several popular open source key/value stores, including Google's LevelDB and Facebook's fork of LevelDB, RocksDB. In general, LSMTrees are a common choice for supporting high volume random writes and reads in a key/value store.
In benchmarking our new storage engine, we find performance is heavily impacted by data file size as controlled
by the number of possible unique keys. We saw similar behavior when
benchmarking our read-only key/value store. It was hypothesized
that this could be due to the operating system's page cache, which holds recently accessed regions of files in
memory to accelerate reading. This is likely also at least partially explains the present results. We check this
using the
iotop
program to inspect IO operations when performing a benchmarking scenario with the
smaller key space size for a
BALANCED
workload.

Here we see significant disk writes, but disk read is an order of magnitude lower. Running the same command with a large key space significant disk reads.
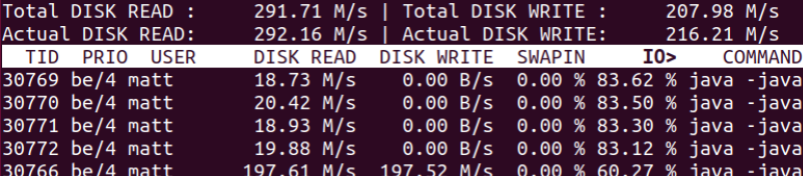
This shows the importance of using large data sizes when benchmarking the actual performance of using disks.
We observe higher performance when using higher key find rates, i.e., using a known key from a previous
put
request versus a randomly generated key for
get
and
delete
requests. We
can explain this by unknown keys requiring
get
requests to search all containers in our
LSMTree
before returning a
null
value indicating that the key is missing. In contrast,
searching for a known key can terminate as soon as the key is found, and at times it may be found in one of the
in-memory containers such that no IO operations need to be performed.
Interestingly, we find 4 threads to be the optimal number of threads performing concurrent operations on our
LSMTee to maximize sum operations/second. In contrast, in our
read-only key value store
we previously found 16 and 64 threads to lead
to higher performance than using just 4. The results for our LSMTree can likely be explained by lock contention for
the
ReadWriteLock
guarding the operations. This approach only allows a single thread to perform write
operations and other writers as well as readers must wait for the lock. We can overcome this bottleneck by
partitioning/sharding, i.e., splitting our data into multiple segments, and thereby allowing multiple concurrent
operations to be performed on different segments without coordination.
Check out Partitioned Storage Engine for Enhanced Concurrent Performance to learn how to apply partitioning to our LSMTree storage engine and thereby improve its performance.