
Disk-Based Storage Engine for Read-Only Key/Value Data
We develop a persistent storage engine for random reads and start exploring the challenges in working with disks. After developing the various components needed for our storage engine, we benchmark it using different types of disks across a range of different workloads.
Introduction
In our initial key/value store, we only support ephemeral storage with all keys and values stored in memory. In this project, we'll introduce persistent storage backed by disk. There are plenty of challenges and gotchas in working with disk drives and we'll explore several. Within this project, our storage engine will not support random writes, it will essentially be write-once and then read-only. This will simplify some challenges and future projects will develop support for random writes. Finally, we'll benchmark our storage engine using three types of disk drives:
- HDD : magnetic Hard Disk Drive
- SSD : Solid State Drive
- NVMe : high-performance Non-Volatile Memory Express drive
You can find the full code for this project within the DBFromZero Java repository on github to read, modify and run yourself.
Challenges of Working With Disks
As we start working disk drives, we're going to encounter some new problems. Many of these problems stem from the multiple layers of abstraction sitting between our program and 1s and 0s one the disk. The abstractions, in descending order from our program to the disk, include, but are not limited to...
Buffering in Library code
Many common library routines for working with files will perform buffering internally, which means that reads
and writes are performed in large chunks using memory to hold the results. For example, when reading from a
buffered file we may only ask for 1 byte, but the library choses to read 1024 bytes, return one to us, and hold the
remaining 1023 bytes in memory for subsequent read requests. Commonly used libraries including
fopen
in C and
FileReader
in Java both use
internal buffers.
The use of internal buffers generally accelerates input/output (IO) performance because it limits the number of times we need to ask the operating system to perform IO and further disks generally achieve higher throughput when working in larger blocks. Yet buffering can cause issues in certain applications. For example, if a program crashes while writing data then any data held in a buffer waiting to be written will be lost.
Operating System Page Cache
Because disks are substantially slower than RAM, modern operating systems (OSes) implement their own caching mechanism for reading and writing data in the form of the page cache. This OS system allows disk reads and writes to be handled using system memory. It's common for frequently used small files to be constantly be held in the page cache so that programs requesting data in these files can access it quickly. This is something we'll have to consider in benchmarking any of our projects that use disk, including this one, in that sufficiently small files can be used without ever touching the disk.
Disk Buffer
Lastly, almost all modern disk drives include their own embedded memory that is used to cache data for reads and write in the form of disk buffers. Yet again, we see memory being used as an intermediary to direct disk access to accelerate IO. The use of disk buffers can be particularly problematic when developing databases in that even though a disk may report data as written, the data may still only reside in this cache and should the system lose power the data will be lost.
There are plenty of other challenges in working with disk and therefore for our first project using disk drives we'll minimize the scope to simplify things initially.
Developing a Read-Only Disk-Based Storage Engine
In this project, we'll build off our past work with a key/value store and develop a storage engine for random reads from disk. Key/value data will be written in a single initial large batch and from there we'll only perform reads. Not having to support writes will simplify some things and future projects will address the challenges of supporting random writes in addition to reads.
Storage Format of Key/Values on Disk
We start by developing the format for storing our data on disk. As in our previous key/value store, our keys and
values will take the form of variable length byte arrays. The utility class
ByteArrayWrapper
is reused from previous work to simplify working with these bytes arrays.
Further, we extend the logic initially developed in
PrefixIo
for writing and reading byte arrays to
support arrays of arbitrary length by prefixing each byte array with its length.
public class PrefixIo {
static final byte END_OF_LENGTH = (byte) 0x1A;
static final byte ESCAPE = (byte) 0x1B;
public static void writeLength(OutputStream s, int length) throws IOException {
int remaining = length;
while (remaining > 0) {
byte b = (byte) (remaining & 0xFF);
if (b == END_OF_LENGTH || b == ESCAPE) {
s.write(ESCAPE);
}
s.write(remaining & 0xFF);
remaining = remaining >> 8;
}
s.write(END_OF_LENGTH);
}
public static int readLength(InputStream s) throws IOException {
int length = 0, index = 0;
while (true) {
int next = s.read();
if ((byte) next == END_OF_LENGTH) {
break;
}
if ((byte) next == ESCAPE) {
next = s.read();
}
if (next < 0) {
throw new EndOfStream("Unexpected end of input stream");
}
length += (next << (8 * index++));
}
return length;
}
public static void writeBytes(OutputStream s, ByteArrayWrapper w) throws IOException {
writeLength(s, w.length());
s.write(w.getArray());
}
public static ByteArrayWrapper readBytes(InputStream s) throws IOException {
int length = readLength(s);
var array = new byte[length];
Dbf0Util.readArrayFully(s, array);
return new ByteArrayWrapper(array);
}
}
These length prefixed arrays take the following format on disk.

You'll notice that we use a special
END_OF_LENGTH
byte to denote the end of the length prefix and
the start of the byte array. This introduces the challenge of what to do when the length itself includes this byte.
For that, the special
ESCAPE
byte value is used to allow us to read the next byte value ignoring
whether it has a special value. And of course, we also have to escape the
ESCAPE
byte when it occurs
in the length.
Using these utilities, we write each key/value pair as two sequential byte arrays.

Further, a database file simply consists of a series of key/value pairs written sequentially.

Writing and Reading Key/Value Data Files
Using these revised
PrefixIO
methods, it's straightforward to develop a class for writing files of
key/value pairs.
class KeyValueFileWriter implements Closeable {
private static final int DEFAULT_BUFFER_SIZE = 0x8000;
private transient OutputStream outputStream;
KeyValueFileWriter(OutputStream outputStream) {
Preconditions.checkNotNull(outputStream);
this.outputStream = outputStream instanceof BufferedOutputStream ? outputStream :
new BufferedOutputStream(outputStream, DEFAULT_BUFFER_SIZE);
}
KeyValueFileWriter(String path) throws IOException {
this(new FileOutputStream(path));
}
void append(ByteArrayWrapper key, ByteArrayWrapper value) throws IOException {
Preconditions.checkState(outputStream != null, "already closed");
PrefixIo.writeBytes(outputStream, key);
PrefixIo.writeBytes(outputStream, value);
}
@Override public void close() throws IOException {
if (outputStream != null) {
outputStream.close();
outputStream = null;
}
}
}
Note the use of an output buffer in the form of
BufferedOutputStream
to enhance IO performance
because we expect to be writing large amounts of data when using this class.
Next, we develop a class for reading a key/value file. This class allows keys and values to be read separately and further we can entirely skip reading a value if isn't of interest to us after reading the associated key. This functionality will be useful when developing code to search for an arbitrary key and read its value in that we can skip the values for other keys.
class KeyValueFileReader implements Closeable {
private transient InputStream inputStream;
private boolean haveReadKey = false;
KeyValueFileReader(InputStream inputStream) {
this.inputStream = inputStream;
}
KeyValueFileReader(String path) throws IOException {
// by default use a large buffer as it is assumed we'll be reading many entries
this(new BufferedInputStream(new FileInputStream(path), 0x8000));
}
@Nullable ByteArrayWrapper readKey() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(!haveReadKey);
ByteArrayWrapper key;
try {
key = PrefixIo.readBytes(inputStream);
} catch (EndOfStream ignored) {
return null;
}
haveReadKey = true;
return key;
}
ByteArrayWrapper readValue() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(haveReadKey);
var value = PrefixIo.readBytes(inputStream);
haveReadKey = false;
return value;
}
void skipValue() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(haveReadKey);
int length = PrefixIo.readLength(inputStream);
skipBytes(length);
haveReadKey = false;
}
@Nullable Pair<ByteArrayWrapper, ByteArrayWrapper> readKeyValue() throws IOException {
var key = readKey();
if (key == null) {
return null;
}
return Pair.of(key, readValue());
}
void skipBytes(long bytes) throws IOException {
long remainingToSkip = bytes;
while (remainingToSkip > 0) {
long skipped = inputStream.skip(remainingToSkip);
if (skipped == 0) {
throw new RuntimeException("Failed to skip " + bytes + " only skipped " + (bytes - remainingToSkip));
}
remainingToSkip -= skipped;
}
}
@Override public void close() throws IOException {
if (inputStream != null) {
inputStream.close();
inputStream = null;
}
}
}
Additionally, the utilities classes of
KeyValueFileIterator
and
KeyOnlyFileIterator
are developed using the
KeyValueFileReader
to simplify subsequent work when iterating through files.
For brevity the code is not included here.
Naive Key Lookup
Now that we've developed components for writing and reading key/value files, we can start to consider how we'll support looking up the value for a given key for use in a key/value store. A naive approach would essentially scan through the file, starting from the beginning, and continuing until we either find the key or reach the end of the file.
class NaiveRandomAccessKeyValueFileReader {
private final String path;
NaiveRandomAccessKeyValueFileReader(String path) { this.path = path; }
@Nullable ByteArrayWrapper get(ByteArrayWrapper key) throws IOException {
try (var reader = new KeyValueFileReader(path)) {
while (true) {
var entryKey = reader.readKey();
if (entryKey == null) {
return null;
}
if (entryKey.equals(key)) {
return reader.readValue();
} else {
reader.skipValue();
}
}
}
}
}
This could be incredibly slow for all but the smallest key/value data files and would not be appropriate for any key/value storage engine. Instead, we'll need a smarter way to find specific keys within our data files.
Sorting by Key for Indexed Lookup
To support reading arbitrary keys, we'll use a common approach of sorting and indexing our data by key. Sorting gives our data a defined order and with sorted data we can create an index consisting of a small fraction of keys and their absolute offset position within the key/value data file. When searching for a key, we can look up the greatest indexed key that is less than or equal to the target key and begin our search at that position in the file. Further, while scanning through the file searching for a specific key, we can terminate our search as soon as we find a key greater than the target key since the sorted order implies this would only occur if the target key isn't in the file.
Assuming we have a sorted key/value file with an index, we can develop reader for random access of arbitrary keys as follows.
RandomAccessKeyValueFileReader code
class RandomAccessKeyValueFileReader {
private final String path;
private final TreeMap<ByteArrayWrapper, Long> index;
RandomAccessKeyValueFileReader(String path, TreeMap<ByteArrayWrapper, Long> index) {
this.path = path;
this.index = index;
}
static TreeMap<ByteArrayWrapper, Long> readIndex(String path) throws IOException {
var iterator = new KeyValueFileIterator(new KeyValueFileReader(path));
var index = new TreeMap<ByteArrayWrapper, Long>();
Dbf0Util.iteratorStream(iterator).forEach(
entry -> index.put(entry.getKey(), ByteBuffer.wrap(entry.getValue().getArray()).getLong()));
return index;
}
@Nullable ByteArrayWrapper get(ByteArrayWrapper key) throws IOException {
// specifically don't use buffered IO cause we hopefully won't have to read much
// and we also get to use KeyValueFileReader.skipValue to avoid large segments of data
// might be worth benchmarking the effect of buffered IO?
try (var reader = new KeyValueFileReader(new FileInputStream(path))) {
return getForReader(key, reader);
}
}
@Nullable ByteArrayWrapper getForReader(ByteArrayWrapper key, KeyValueFileReader reader) throws IOException {
reader.skipBytes(computeSearchStartIndex(key));
return scanForKey(key, reader);
}
long computeSearchStartIndex(ByteArrayWrapper key) {
return Optional.ofNullable(index.floorEntry(key)).map(Map.Entry::getValue).orElse(0L);
}
@Nullable ByteArrayWrapper scanForKey(ByteArrayWrapper key, KeyValueFileReader reader) throws IOException {
while (true) {
var entryKey = reader.readKey();
if (entryKey == null) {
return null;
}
int cmp = entryKey.compareTo(key);
if (cmp == 0) {
return reader.readValue();
} else if (cmp < 0) {
reader.skipValue();
} else {
return null;
}
}
}
}
Note the use of Java's
TreeMap
from the standard library. This data structure stores its entries in
sorted order so that we can efficiently find the greatest indexed key that is less than or equal to the target key
using
.floorEntry(key).
This a reasonable approach to supporting random reads in large key/file files. Now we need to figure out how to
generate large, sorted key/value files and build an index. First, we define a simple interface for an
IndexBuilder
that receives a sequence of sorted keys and their offset in the key/value file. It
selects keys at a configurable frequency of
indexRate
for inclusion in the index and writes these
index keys and their offset position into an index file using a separate
KeyValueFileWriter
with the
values being offset positions.
interface IndexBuilder {
Logger LOGGER = Dbf0Util.getLogger(IndexBuilder.class);
void accept(long position, ByteArrayWrapper key) throws IOException;
static IndexBuilder indexBuilder(KeyValueFileWriter indexStorage, int indexRate) {
return new IndexBuilderImpl(indexStorage, indexRate);
}
static IndexBuilder multiIndexBuilder(Iterable<IndexBuilder> indexBuilders) {
return new MultiIndexBuilder(indexBuilders);
}
class IndexBuilderImpl implements IndexBuilder {
private final KeyValueFileWriter indexStorage;
private final int indexRate;
private int keyCount;
IndexBuilderImpl(KeyValueFileWriter indexStorage, int indexRate) {
this.indexStorage = Preconditions.checkNotNull(indexStorage);
Preconditions.checkArgument(indexRate > 0);
this.indexRate = indexRate;
this.keyCount = 0;
}
@Override public void accept(long position, ByteArrayWrapper key) throws IOException {
if (keyCount % indexRate == 0) {
LOGGER.fine(() -> "writing index at " + keyCount);
indexStorage.store(key, ByteArrayWrapper.of(ByteBuffer.allocate(8).putLong(position).array()));
}
keyCount++;
}
}
...
}
Generating Large, Sorted Key/Value Files
Now we address the challenge of creating large key/value files with sorted keys. We take a divide an concur approach by first generating a large number of smaller sorted files where each of these files is small enough to allow all keys to be held in memory for sorting before writing.
public class WriteSortedKeyValueFiles {
private static final Logger LOGGER = Dbf0Util.getLogger(WriteSortedKeyValueFiles.class);
static final int KEY_LENGTH = 16;
public static void main(String[] args) {
Dbf0Util.enableConsoleLogging(Level.FINE);
Preconditions.checkArgument(args.length == 4);
var directory = args[0];
var fileCount = Integer.parseInt(args[1]);
var valueLength = Integer.parseInt(args[2]);
var entriesCount = Math.round(Float.parseFloat(args[3]));
Dbf0Util.requireEmptyDirectory(directory);
IntStream.range(0, fileCount).boxed().parallel().forEach(IoConsumer.wrap(index ->
writeFile(directory + "/" + index, valueLength, entriesCount)
));
}
private static void writeFile(String path, int valueLength, int entriesCount) throws IOException {
var random = new Random();
LOGGER.info("Generating sorted keys for" + path);
var sortedKeys = IntStream.range(0, entriesCount)
.mapToObj(ignored -> ByteArrayWrapper.random(random, KEY_LENGTH))
.sorted();
try (var storage = new KeyValueFileWriter(path)) {
StreamUtils.zipWithIndex(sortedKeys).forEach(IoConsumer.wrap(indexed -> {
if (indexed.getIndex() % 10000 == 0) {
LOGGER.fine(() -> "Writing entry " + indexed.getIndex() + " of " + path);
}
storage.store(indexed.getValue(), ByteArrayWrapper.random(random, valueLength));
}));
}
}
}
For subsequent benchmarking, the keys and values are generated at random. Key size is fixed at 16 bytes, the
size of a
Universally unique identifier,
which should ensure that no two randomly generated keys ever have the same value. Also note the usage of
Stream.parallel()
to generate different files concurrently and accelerate the creation of the large
number of files.
Now we need an approach to combine all of the small sorted files into one large key/value data file and we
accomplish this using
merge sort. Specifically, the guava
routine
Iterators.mergeSorted
can combine an arbitrary number of sorted iterators into a single sorted
iterator. The input iterators are evaluated lazily as needed when consuming the combined iterator. We avoid holding
either the full inputs or the full output in memory and instead write the final output file while reading in all of
the sorted input files. This is an example of
external
sorting
whereby we sort a volume of data larger than can be held in memory.
public class MergeSortFiles {
private static final Logger LOGGER = Dbf0Util.getLogger(MergeSortFiles.class);
public static void main(String[] args) throws Exception {
Preconditions.checkArgument(args.length >= 3);
Dbf0Util.enableConsoleLogging(Level.FINE);
var sortedFilesDirectory = args[0];
var sortedFilesCount = Integer.parseInt(args[1]);
var outputFilePath = args[2];
var indexSpecs = Arrays.stream(args).skip(3).map(MergeSortFiles::parseIndexSpec)
.collect(Collectors.toList());
LOGGER.info("Reading " + sortedFilesCount + " sorted files from " + sortedFilesDirectory);
LOGGER.info(" Writing merged output to " + outputFilePath);
LOGGER.info("Writing " + indexSpecs.size() + " indices");
indexSpecs.forEach(spec -> LOGGER.info(" Index rate " + spec.getRight() + " in " + spec.getLeft()));
var iterators = IntStream.range(0, sortedFilesCount).boxed().map(IoFunction.wrap(index ->
new KeyValueFileIterator(new KeyValueFileReader(sortedFilesDirectory + "/" + index))))
.collect(Collectors.toList());
var sortedIterator = Iterators.mergeSorted(iterators, Map.Entry.comparingByKey());
var indexBuilder = IndexBuilder.multiIndexBuilder(
indexSpecs.stream().map(MergeSortFiles::createIndexBuilder).collect(Collectors.toList()));
try (var outputStream = new PositionTrackingStream(outputFilePath)) {
try (var storage = new KeyValueFileWriter(outputStream)) {
ByteArrayWrapper lastKey = null;
int i = 0;
while (sortedIterator.hasNext()) {
var entry = sortedIterator.next();
if (i % 10000 == 0) {
LOGGER.fine("Writing merged " + i);
}
i++;
if (lastKey != null && lastKey.equals(entry.getKey())) {
LOGGER.warning("Skipping duplicate key " + lastKey);
continue;
}
lastKey = entry.getKey();
indexBuilder.accept(outputStream.getPosition(), entry.getKey());
storage.store(entry.getKey(), entry.getValue());
}
}
}
}
...
}
Note that this code also supports building multiple indexes for the key/value data file that it generates. This will allow us to experiment with different indexing frequencies.
Using these developed components, we can now generate large, sorted key/value data files with indexes for efficient random look up of arbitrary keys.
Benchmarking
We next develop a benchmarking harness to quantify the performance of our
RandomAccessKeyValueFileReader
in different scenarios.
public class Benchmark {
public static void main(String[] args) throws Exception {
Preconditions.checkArgument(args.length == 7);
Dbf0Util.enableConsoleLogging(Level.INFO);
var dataPath = args[0];
var indexPath = args[1];
var knownKeysDataPath = args[2];
var keySetSize = Integer.parseInt(args[3]);
var knownKeyGetFrac = Float.parseFloat(args[4]);
var readThreads = Integer.parseInt(args[5]);
var duration = Duration.parse(args[6]);
var store = new RandomAccessKeyValueFileReader(dataPath, RandomAccessKeyValueFileReader.readIndex(indexPath));
var random = new Random();
var allKnownKeys = Dbf0Util.iteratorStream(new KeyOnlyFileIterator(new KeyValueFileReader(knownKeysDataPath)))
.collect(Collectors.toList());
Collections.shuffle(allKnownKeys, random);
var knownKeys = allKnownKeys.subList(0, keySetSize);
var unknownKeys = IntStream.range(0, keySetSize).mapToObj(i ->
ByteArrayWrapper.random(random, WriteSortedKeyValueFiles.KEY_LENGTH))
.collect(Collectors.toList());
var countGet = new AtomicInteger(0);
var countFound = new AtomicInteger(0);
var threads = IntStream.range(0, readThreads).mapToObj(i -> new Thread(IoRunnable.wrap(() -> {
var threadRandom = new Random();
while (!Thread.interrupted()) {
var keys = threadRandom.nextFloat() < knownKeyGetFrac ? knownKeys : unknownKeys;
var key = keys.get(threadRandom.nextInt(keys.size()));
boolean found = store.get(key) != null;
countGet.incrementAndGet();
if (found) {
countFound.incrementAndGet();
}
}
}))).collect(Collectors.toList());
threads.forEach(Thread::start);
Thread.sleep(duration.toMillis());
threads.forEach(Thread::interrupt);
for (var thread : threads) {
thread.join();
}
var stats = ImmutableMap.of("get", countGet.get(), "found", countFound.get());
System.out.println(new Gson().toJson(stats));
}
}
(Note, the benchmarking code shown here has been simplified for presentation. Checkout the repository for full code.)
In benchmarking, we consider three types of disk drives, NVMe, SSD, and HDD. The following AWS EC2 instances and EBS volumes are used to test different drives.
| Type | Instance Type | vCPUs | RAM (GiB) | EBS Volume Type | Provisioned IOPs (Thousands) |
|---|---|---|---|---|---|
| NVMe | i3.2xlarge | 8 | 61 | n/a | 180 |
| SSD | c5n.2xlarge | 8 | 21 | gp2 | 3 |
| HDD | c5n.2xlarge | 8 | 21 | standard | 0.04 - 0.2 |
Note the drastically different input/output operations per a second (IOPs) promised by AWS for each instance type. Also note that the NVMe instance doesn't use an EBS volume, but instead has a dedicated device.
All EC2 instances are configured as follows:
- OS Image : Ubuntu 18.04 LTS - Bionic
- Kernel : Linux version 4.15.0-1065-aws
- JRE : OpenJDK 64-Bit Server VM version 11.0.6
Additionally, we explore different scenarios in benchmarking by varying the following parameters.
-
data size
- total size of the data file
- 10 GB - small
- 50 GB - medium
- 250 GB - large
-
index frequency
- the frequency at which keys in the data are included in the index
- 10: dense index
- 100: moderate
- 1000: sparse
- read threads : values of 1, 4, 16, and 64 are considered
-
value length
- size of individual values
- 256 bytes: small
- 4096 bytes: large
-
key find fraction
- the fraction of key key lookups for a known key vs. a randomly generated
key not in the data
- 0.1: infrequently found
- 0.5: balanced
- 0.9: frequently found
Benchmarking is performed using a simple Python script that iterates through all defined parameter combinations
in a randomized order, runs the Java
Benchmark
harness, and records the results for subsequent
analysis. All benchmarking trials are ran for 10 seconds and 10 trials are ran for each parameter combination to
allow us to measure the variation of the results.
Analysis of Benchmarking Results
For each benchmarking run, we compute the reads per a second and then aggregated across different trials for the same parameter combination to give the median operations per a second as well as the 25th and 75th percentiles for quantifying variance for each scenario.
High-level Analysis of All Parameters
We start with a high-level analysis of the impact of each individual parameter. To this end, box plots are computed for each parameter value to show the distribution of scenario median performance for all other parameter combinations. This visualization technique shows the distribution of observations with a box encompassing the 25% to 75% range and the median shown by a horizontal bar. Outliers are shown as individual points. (Note, these are distribution of the median performance for each parameter combination.)
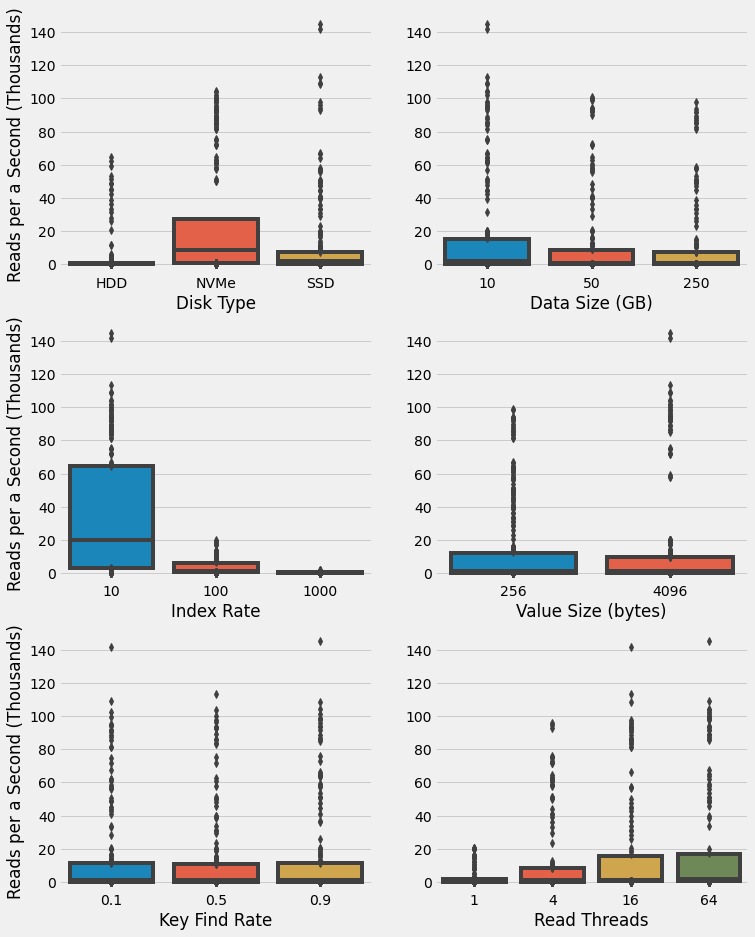
There are several interesting observations from these high-level results:
- As one might expect, the HHD give the lowest performance of all drives.
- The NVMe shows a higher median performance than the SSD, yet unexpectedly the SSD has outliers that outperform the NVMe.
- Performance decreases with larger data size, yet there are lots of outliers that warrant investigation.
- Index rate has a massive impact on performance with indexing ever 10 entries associated with all of the higher performing cases.
- Value size appears to have a modest impact on performance, yet again there are lots of outliers to explore.
- Key find rate doesn't have much of an effect overall, yet there are outliers for 0.1 and 0.9 with substantially higher performance than 0.5.
- As expected, increasing threads increases overall performance, although there appears to be negligible difference between 16 and 64.
Next, we investigate the outliers by selecting the top 10 performing scenarios as quantified by median performance across the ten trials.
| Disk Type | Data Size (GB) | Index Rate | Value Size (bytes) | Key Find Rate | Read Threads | Reads per a Second (Thousands) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| min | 25% | 50% | 75% | max | ||||||
| SSD | 10 | 10 | 4096 | 0.9 | 64 | 6.1 | 100.1 | 144.9 | 148.9 | 150.2 |
| SSD | 10 | 10 | 4096 | 0.1 | 16 | 69.7 | 116.8 | 141.8 | 144.6 | 146.3 |
| SSD | 10 | 10 | 4096 | 0.5 | 16 | 77.4 | 106.2 | 113.2 | 128.4 | 144.5 |
| SSD | 10 | 10 | 4096 | 0.1 | 64 | 9.2 | 53.2 | 109.1 | 136.2 | 155.6 |
| SSD | 10 | 10 | 4096 | 0.9 | 16 | 54.0 | 92.2 | 108.5 | 134.4 | 146.4 |
| NVMe | 10 | 10 | 4096 | 0.9 | 64 | 97.0 | 101.3 | 104.5 | 107.7 | 109.6 |
| NVMe | 10 | 10 | 4096 | 0.5 | 64 | 98.1 | 100.3 | 103.7 | 105.8 | 107.0 |
| NVMe | 10 | 10 | 4096 | 0.1 | 64 | 96.0 | 98.9 | 102.1 | 103.3 | 104.5 |
| NVMe | 50 | 10 | 4096 | 0.9 | 64 | 94.2 | 97.8 | 101.1 | 101.9 | 105.0 |
| NVMe | 50 | 10 | 4096 | 0.5 | 64 | 91.9 | 98.1 | 100.3 | 100.8 | 101.4 |
We see that all of these top performing scenarios have an index rate of 10 and a value size of 4,096 bytes. Further, the top eight all have the smallest data size of 10 GB. Interestingly, the top five all correspond to using an SSD with the highest performance achieved at 144,900 reads per a second. The highest performing scenario with an NVMe only achieves 104,500 reads per a second, roughly 50% lower than the highest SSD case. There doesn't appear to be any obvious pattern for key find rate, with all three values mixed into the top scenarios, although the top two performing scenarios with around 140,000 reads/sec have key finds rates of 0.9 and 0.1, while the third highest performing is only 113,000 and has the balanced find rate of 0.5.
As will be considered further in the discussion section of this project, these outliers with data size of only 10 GB may be related to the operating system page cache holding the data in memory and therefore not being limited on risk read latency and throughput. Hence, the results for larger data size will be more interesting in this project and we therefore eliminate the 10 GB data size within subsequent analysis.
Analysis of Disk Type and Indexing Rate
With this high-level understanding, we can now focus on the impact of disk type and index rate on read performance. For each disk type, data size, and indexing rate combination, we determine the read thread count that gives the highest performance as shown in the following figure for constant find rate of 0.5 and value size of 4,096 bytes. Bar width shows the median performance across the ten trials and the interquartile range is shown with error bars. Disk type is highlight by the bar color and different indexing frequencies are denoted with different overlay patterns.
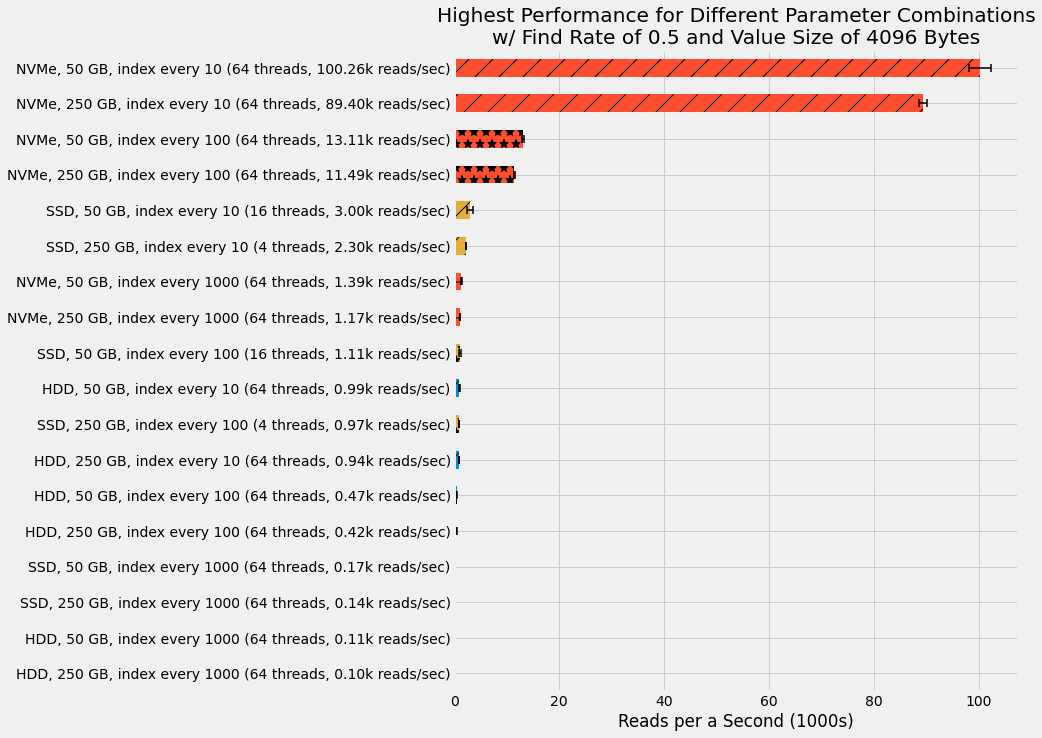
Here we see the NVMe massively outperform the SSD with 30 times higher performance for the 50 GB data size with indexing every 10 records. Further, we see only a roughly 10% drop in performance when increasing data size from 50 GB to 250 GB for the NVMe with indexing every 10 records. Even when using a sparser index with only 100 records, the NVMe still outshines the SSD with the denser index of every 10 records.
For these larger data sizes, the SSD barely shows up on the plot at only roughly 3,000 reads per a second. This is a far cry from the 100,000 to 140,000 performance seen for the SSD with the smaller data size of only 10 GB. And therefore we can assume the 10 GB results are not representative of the SSD performance.
Lastly, the HDD results are almost invisible with top performance not even breaking 1,000 reads per a second. These results truly highlights the importance of disk type when using persistent storage in a database.
Discussion and Next Steps
This completes our first steps into persistent storages for databases. While our current storage engine is limited in that it can only support random reads, such databases can be useful in actual production systems. For example, my past employer LiveRamp developed and maintained Hank, a predominately read only key/value store with updates supported by rewriting the underlying data in large batches.
In benchmarking our storage engine developed in this project, we discovered surprisingly high performance when using an SSD with the small dataset of 10 GB. The performance in this scenario even outperformed the NVMe. Yet the performance with an SSD drops considerably when increasing the data size to 50 GB with a drop off from over 140,000 reads/sec to just 3,000. This suggests we've encountered one of the gotchas associated with working with disk drives. In this case, I hypothesize that the OS page cache is holding a substantial portion of the underlying data in memory and therefore we're not actually testing the SSD performance. Conflicting evidence for this hypothesis comes from the results for the HDD using the same EC2 instance type and OS, yet barely surpassing 60,000 reads/sec. Hence we may assume that the SSD does provide some value here, although it involves a complex interplay between the OS and the disk drive.
Moving beyond the small 10 GB data size, we find the NVMe greatly outclasses the SSD with up to a factor of 30 times higher performance. This is expected and can be attributed to more than just the underlying disk hardware. For the NVMe, we use a dedicated device associated with the EC2 instance whereas for the SSD and HDD we access the drive as an EBS volume. AWS provides limited IOPs for EBS volumes by default and paying for higher provisioned IOPs quickly becomes cost inefficient when EC2 instances with dedicated NVMe devices are available.
For our next database, we'll extend this work to develop support for random writes with disk-backed persistence. This will introduce additional challenges of working with disks. Check out Log-Structured Merge-Tree for Persistent Reads and Writes to learn about these challenges and see how they can be addressed using an LSMTree.