
Adding Durability Using Write-Ahead Logging
Our most recent project addresses data durability. I.e., can we preserve data if the process or host crashes. The previously developed partitioned, log-structured merge-tree key/value store would lose data in such an event since it collects writes in memory for batch persisting to disk.
We introduce durability by
developing Write-Ahead Logging (WAL), which
consists of recording all
PUT
or
DELETE
operations to a log file before actually
performing them on the database.

In the event of a crash, the database can reads these logs in recovery and perform any operation that wasn't persisted to disk in the main data storage.
The development section of the project demonstrates how to develop WAL for our current storage engine. Further, testing verifies that our LSMTree can recover from a crash using the WAL.
public class LsmTreeTest {
...
@Test
public void testRecoverFromCrashUsingLogs() throws IOException {
var logDirectory = new MemoryFileDirectoryOperations();
var createLsmTree = (Function<MemoryFileDirectoryOperations, ReadWriteStorageWithBackgroundTasks<ByteArrayWrapper, ByteArrayWrapper>>)
(dataDirectory) ->
LsmTree.builderForTesting(dataDirectory)
.withPendingWritesDeltaThreshold(1000)
.withWriteAheadLog(new WriteAheadLog<>(logDirectory, ImmediateLogSynchronizer.factory()))
.withScheduledThreadPool(2)
.withIndexRate(10)
.withMaxInFlightWriteJobs(10)
.withMaxDeltaReadPercentage(0.5)
.withMergeCronFrequency(Duration.ofMillis(250))
.buildWithBackgroundTaks();
var flakingTree = createLsmTree.apply(new MemoryFileDirectoryOperations("flaking",
Map.of("base", Either.left(new FlakyLengthMemoryFileDirectoryOperations(1000)))));
flakingTree.initialize();
var map = new HashMap<ByteArrayWrapper, ByteArrayWrapper>();
var random = RandomSeed.CAFE.random();
assertThatThrownBy(() -> {
for (int i = 0; i < 100 * 1000; i++) {
var key = ByteArrayWrapper.random(random, 16);
var value = ByteArrayWrapper.random(random, 100);
flakingTree.put(key, value);
map.put(key, value);
}
}).isInstanceOf(IllegalStateException.class);
flakingTree.close();
LOGGER.info("Wrote " + map.size() + " entries before failing");
assertThat(map).isNotEmpty();
var readingTree = createLsmTree.apply(new MemoryFileDirectoryOperations());
readingTree.initialize();
for (var entry : map.entrySet()) {
assertThat(readingTree.get(entry.getKey())).isEqualTo(entry.getValue());
}
readingTree.close();
}
...
}
A key part of WAL implementation, is ensuring that data is flushed from in-memory buffers in the operating system and disk such that is durably persisted. This is accomplished by making sync system calls. Syncing data can be expensive and therefore some data storage engines will not perform a sync operating on every write to the WAL. Instead, syncing is performed at a fixed interval and the interval can be configured to choose the appropriate balance between data durability and performance.
In the present project, we develop both immediate syncing for WAL writes as well as syncing at a configurable frequency. Benchmarking is performed to quantify the impact of each syncing strategy. We find massive performance penalties for always syncing and moderate penalties for syncing at a configured frequency.
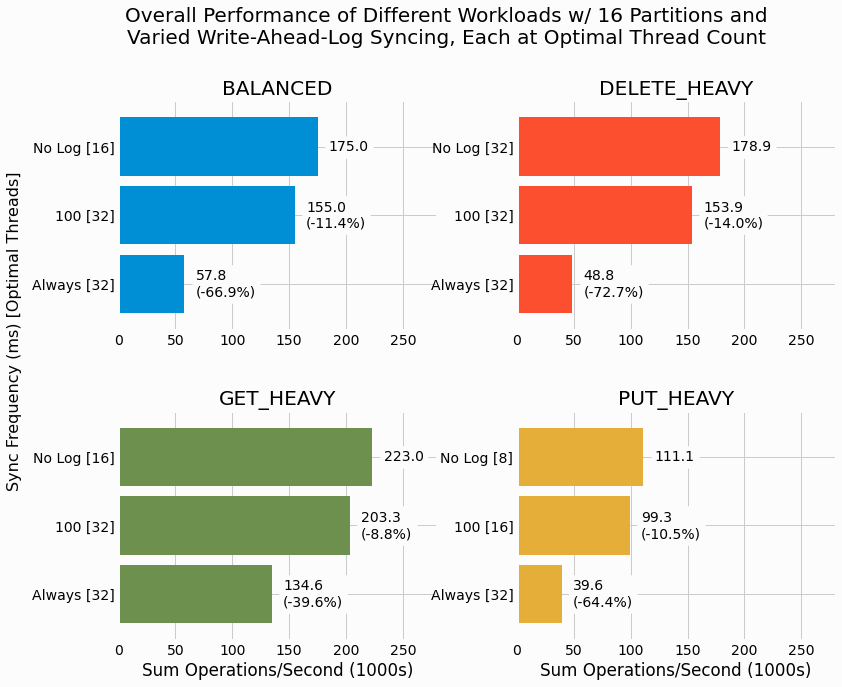
Rather surprisingly, the syncing frequency has a minor impact on performance and we discuss why that may be the case.
Its quite exciting to see our key/value storage engine maturing with the addition of WAL for data durability. Our next project will further the sophistication of our storage engine by extending it to store documents. For example, social network comments of the following form.
{
"8bn73x489732" : {
"comment": "I love this post! Allow me to explain each of the 72 things that I enjoyed...",
"time-posted": "2020-05-09T09:10:52",
"likes": 0
}
}
I'm actively developing this project and have began some preliminary benchmarks by loading 146 million Reddit comments with a total size of 174 GB. The project is progressing smoothly so check back soon to learn about managing documents in a key/value store.