
Multivalue LSMTree Storage Engine
To store secondary indexes, we extend our partitioned, log-structured merge-tree key/value store to support multiple values for each key. The new storage engine is benchmarked using 147 million Reddit comments to quantify performance in building secondary index stores and also latency for fetching all primary keys for randomly selected secondary keys.
Introduction
We recently added document storage to our partitioned, log-structured merge-tree (LSMTree) key/value store. This allows for the development of more sophisticated features, including secondary indexes where the data store is additionally indexed by attributes beyond the primary key. Secondary indexes differ from primary indexes in that a secondary key is not necessarily unique and multiple records can be associated with a single secondary key. Therefore we'll need a way to associate multiple values with a single key in order to support secondary indexes.
In this project we develop a key/value store that can associate multiple values with a single key. The
multivalue key/value store is developed by generalizing our previously created single value LSMTree. An arbitrarily
large number of values can be associated with a single key as they are read from disk in a streaming fashion. After
developing and test the new multivalue LSMTree, we benchmark its performance using Reddit comment data.
Specifically, we build stores appropriate for secondary indexes consisting of each secondary key associated with
the comment
id
for all comments that have that secondary key value. Within this project, we consider
secondary indexes for
author
and
subreddit
attributes.
You can find the full code for this project within the DBFromZero Java repository on GitHub to read, modify, and run yourself.
Developing a Multivalued LSMTree
Development begins with generalizing our key/value writer and reader components into base classes. Using these base classes, we develop concrete classes specifically for single value and multivalue key/value storage. Next, the LSMTree components are generalized to be agnostic to the underlying storage. Our previous single value LSMTree is refactored to use these components. Lastly, we develop a new multivalue LSMTree using the multivalue key/value storage and the generalized LSMTree components.
Multivalue Key/Value Storage
Our previous single value files consisted of contiguous series of key/value pairs where each pair has the key and value serialized adjacent to each other as shown in the following figure.

We adapt this format to store multiple values. The values are stored in a contiguous series with the count stored as a variable length integer prefixing the values.

Using the newly developed
BaseKeyValueFileWriter
class the following class is developed for writing key/multivalue
files.
public class KeyMultiValueFileWriter<K, V> extends BaseKeyValueFileWriter<K, V> {
private int valuesToBeWritten = 0;
public KeyMultiValueFileWriter(Serializer<K> keySerializer, Serializer<V> valueSerializer,
OutputStream outputStream) {
super(keySerializer, valueSerializer, outputStream);
}
public void startKey(K key, int valueCount) throws IOException {
Preconditions.checkArgument(valueCount > 0, "bad valueCount %s", valueCount);
Preconditions.checkState(outputStream != null, "already closed");
Preconditions.checkState(valuesToBeWritten == 0,
"still waiting on %s values from last key", valuesToBeWritten);
keySerializer.serialize(outputStream, key);
IOUtil.writeVariableLengthUnsignedInt(outputStream, valueCount);
valuesToBeWritten = valueCount;
}
public void writeValue(V value) throws IOException {
Preconditions.checkState(valuesToBeWritten > 0, "attempt to write too many values for key");
valueSerializer.serialize(outputStream, value);
valuesToBeWritten--;
}
public void writeKeysAndValues(K key, int valueCount, IOIterator<? extends V> valueIterator)
throws IOException {
startKey(key, valueCount);
while (valueIterator.hasNext()) {
writeValue(valueIterator.next());
}
Preconditions.checkState(valuesToBeWritten == 0);
}
public void writeKeysAndValues(K key, Collection<? extends V> values) throws IOException {
writeKeysAndValues(key, values.size(), IOIterator.of(values.iterator()));
}
}
Similarly, a reading class is developed using the new base class
BaseKeyValueFileReader.
public class KeyMultiValueFileReader<K, V> extends BaseKeyValueFileReader<K, V> {
private int valuesCount = 0;
private int valuesRemaining = 0;
private IOIterator<V> valueIterator = null;
public KeyMultiValueFileReader(Deserializer<K> keyDeserializer,
Deserializer<V> valueDeserializer,
InputStream inputStream) {
super(keyDeserializer, valueDeserializer, inputStream);
}
@Nullable public K readKey() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(valuesRemaining == 0, "there are still values remaining");
K key;
try {
key = keyDeserializer.deserialize(inputStream);
} catch (EndOfStream ignored) {
valuesCount = valuesRemaining = 0;
return null;
}
valuesCount = valuesRemaining = IOUtil.readVariableLengthUnsignedInt(inputStream);
return key;
}
public int getValuesCount() {
return valuesCount;
}
public int getValuesRemaining() {
return valuesRemaining;
}
public V readValue() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(valuesRemaining > 0);
V value = valueDeserializer.deserialize(inputStream);
valuesRemaining--;
return value;
}
public void skipValue() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(valuesRemaining > 0);
valueDeserializer.skipDeserialize(inputStream);
valuesRemaining--;
}
public void skipRemainingValues() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
for (; valuesRemaining > 0; valuesRemaining--) {
valueDeserializer.skipDeserialize(inputStream);
}
}
public IOIterator<V> valueIterator() {
Preconditions.checkState(inputStream != null, "already closed");
if (valueIterator == null) {
valueIterator = new IOIterator<>() {
@Override public boolean hasNext() {
return valuesRemaining > 0;
}
@Override public V next() throws IOException {
if (valuesRemaining == 0) {
throw new NoSuchElementException();
}
return readValue();
}
@Override public void skip() throws IOException {
skipValue();
}
@Override public void close() throws IOException {
KeyMultiValueFileReader.this.close();
}
};
}
return valueIterator;
}
@Override public void close() throws IOException {
super.close();
valuesCount = valuesRemaining = 0;
valueIterator = null;
}
}
It is noteworthy that this class allows us to iterate over all of the values for a given key without having to read all of the values into memory. This will allow us to support an arbitrarily large number of values associated with a single key.
Lastly, we develop
RandomAccessKeyMultiValueFileReader
to efficiently locate and read the values
for a specific key using a sparse index.
RandomAccessKeyMultiValueFileReader code
public class RandomAccessKeyMultiValueFileReader<K, V> extends
BaseRandomAccessKeyValueFileReader<K, V, KeyMultiValueFileReader<K, V>> {
public RandomAccessKeyMultiValueFileReader(TreeMap<K, Long> index,
Comparator<K> keyComparator,
IOSupplier<KeyMultiValueFileReader<K, V>> readerSupplier) {
super(index, keyComparator, readerSupplier);
}
protected boolean scanForKey(K key, KeyMultiValueFileReader<K, V> reader) throws IOException {
while (true) {
var entryKey = reader.readKey();
if (entryKey == null) {
return false;
}
int cmp = keyComparator.compare(entryKey, key);
if (cmp == 0) {
return true;
} else if (cmp < 0) {
reader.skipRemainingValues();
} else {
return false;
}
}
}
@Nullable public MultiValueResult<V> get(K key) throws IOException {
MultiValueResult<V> result = null;
var reader = readerSupplier.get();
try {
reader.skipBytes(computeSearchStartIndex(key));
if (scanForKey(key, reader)) {
result = new MultiValueResultImp<>(reader);
}
} finally {
if (result == null) {
reader.close();
}
}
return result;
}
...
}
Generalizing LSMTree Components
Next, we refactor out common functionality of our original
LSMTree
that can be reused by the
multivalue version. Minor modifications are needed to
BaseDeltaFiles
for managing the base and delta files associated with an LSMTree. The code isn't
shown here for brevity.
To write sorted and indexed files, a generic
WriteJobCoordinator
is developed for managing background jobs that writes these files. This
includes generalizing
WriteJob. Lastly, a general purpose component is created for merging base and delta files in
BaseDeltaMergerCron. As these components are quite similar to those originally developed for the
single value LSMTree the code isn't included here and you can follow the links to the GitHub repo to see the
source.
The
WriteJobCoordinator
uses a newly developed
FixedSizeBackgroundJobCoordinator
class for managing arbitrary background jobs with a fixed limit
on the maximum number of background jobs. This class can be reused in future projects and it simplifies the
development of
WriteJobCoordinator.
FixedSizeBackgroundJobCoordinator code
public class FixedSizeBackgroundJobCoordinator<X extends Runnable> {
private final ExecutorService executor;
private final int maxInFlightJobs;
private final LinkedList<X> inFlightJobs = new LinkedList<>();
public FixedSizeBackgroundJobCoordinator(ExecutorService executor, int maxInFlightJobs) {
Preconditions.checkArgument(maxInFlightJobs > 0);
this.executor = executor;
this.maxInFlightJobs = maxInFlightJobs;
}
public synchronized boolean hasMaxInFlightJobs() {
return inFlightJobs.size() == maxInFlightJobs;
}
public synchronized boolean hasInFlightJobs() {
return !inFlightJobs.isEmpty();
}
public synchronized List<X> getCurrentInFlightJobs() {
return new ArrayList<>(inFlightJobs);
}
public synchronized void execute(X job) {
Preconditions.checkState(!hasMaxInFlightJobs());
executeInternal(job);
}
private void executeInternal(X job) {
inFlightJobs.add(job);
executor.execute(() -> run(job));
}
public synchronized void awaitNextJobCompletion() throws InterruptedException {
if (!inFlightJobs.isEmpty()) {
wait();
}
}
public void waitUntilExecute(X job) throws InterruptedException {
while (true) {
synchronized (this) {
if (!hasMaxInFlightJobs()) {
executeInternal(job);
break;
}
wait();
}
}
}
private void run(X job) {
try {
job.run();
} finally {
synchronized (this) {
var removed = inFlightJobs.remove(job);
Preconditions.checkState(removed);
notify();
}
}
}
}
Developing MultiValueLsmTree
A key difference between a multiple value LSMTree and a single value one is that relevant data for a key can be
stored in multiple containers, including both in-memory containers and on-disk containers for the multivalue
variant. All these containers must be considered when performing a
GET
operation for a given key. In
contrast, for a single value LSMTree we search through the containers in appropriate order and stop as soon as we
find a value or a delete entry for the key of interest.
We begin our development of a multivalue LSMTree by first creating a class to hold a group of puts and deletes in memory.
class PutAndDeletes<K, V> {
private final HashMultimap<K, V> puts;
private final HashMultimap<K, V> deletes;
PutAndDeletes(int expectedSize) {
expectedSize = Math.max(expectedSize, 32);
puts = HashMultimap.create(expectedSize >> 2, 4);
deletes = HashMultimap.create(expectedSize >> 4, 2);
}
int size() {
return puts.size() + deletes.size();
}
void put(K key, V value) {
puts.put(key, value);
deletes.remove(key, value);
}
void delete(K key, V value) {
deletes.put(key, value);
puts.remove(key, value);
}
List<ValueWrapper<V>> getValues(K key) {
var ps = puts.get(key);
var ds = deletes.get(key);
var pn = ps.size();
var dn = ds.size();
if (pn == 0 && dn == 0) {
return List.of();
}
var list = new ArrayList<ValueWrapper<V>>(pn + dn);
if (pn > 0) {
for (V p : ps) {
list.add(new ValueWrapper<>(false, p));
}
}
if (dn > 0) {
for (V d : ds) {
list.add(new ValueWrapper<>(true, d));
}
}
return list;
}
Multimap<K, ValueWrapper<V>> getCombined() {
Multimap<K, ValueWrapper<V>> combined = HashMultimap.create(
puts.asMap().size() + deletes.asMap().size(), 4);
add(combined, puts, false);
add(combined, deletes, true);
return combined;
}
private void add(Multimap<K, ValueWrapper<V>> combined, HashMultimap<K, V> map, boolean isDelete) {
map.forEach((k, v) -> combined.put(k, new ValueWrapper<>(isDelete, v)));
}
}
Note the use of guava's
HashMultimap
for associating multiple values with a single key. The
lightweight class
ValueWrapper
is introduced to differentiate between
PUT
and
DELETE
entries when writing and reading multivalue key/value files.
Next a component is developed for persisted a group of writes to disk. Similar to the single value LSMTree,
these writes are sorted by key for efficient lookup of an arbitrary key using a sparse index in
RandomAccessKeyMultiValueFileReader. Additionally, all values for a given key are stored in a sorted
order. This facilitates removing duplicates when reading from multiple containers in a
GET
operation.
The sorted order also allows us to bring together
PUT
and
DELETE
entries for a given
value and choose the most recent to determine whether or not the value is presently associated with the given
key.
SortAndWriteKeyMultiValues code
public class SortAndWriteKeyMultiValues<K, V> implements WriteJob.SortAndWriter<PutAndDeletes<K, V>> {
private static final Logger LOGGER = Dbf0Util.getLogger(SortAndWriteKeyMultiValues.class);
private final LsmTreeConfiguration<K, ValueWrapper<V>> configuration;
private final Comparator<V> valueComparator;
public SortAndWriteKeyMultiValues(LsmTreeConfiguration<K, ValueWrapper<V>> configuration,
Comparator<V> valueComparator) {
this.configuration = configuration;
this.valueComparator = valueComparator;
}
@Override
public void sortAndWrite(PositionTrackingStream outputStream, BufferedOutputStream indexStream,
PutAndDeletes<K, V> writes, boolean isBase) throws IOException {
LOGGER.info(() -> "Sorting " + writes.size() + " writes");
var entries = writes.getCombined().asMap().entrySet().stream()
.sorted(Map.Entry.comparingByKey(configuration.getKeyComparator()))
.collect(Collectors.toList());
long keyCount = 0, valueCount = 0;
var wrapperComparator = ValueWrapper.comparator(valueComparator);
var keySerializer = configuration.getKeySerialization().getSerializer();
try (var indexWriter = new KeyValueFileWriter<>(keySerializer, UnsignedLongSerializer.getInstance(),
indexStream)) {
var indexBuilder = IndexBuilder.indexBuilder(indexWriter, configuration.getIndexRate());
try (var writer = new KeyMultiValueFileWriter<>(keySerializer,
configuration.getValueSerialization().getSerializer(), outputStream)) {
for (var keySet : entries) {
var key = keySet.getKey();
indexBuilder.accept(outputStream.getPosition(), key);
var values = isBase ?
keySet.getValue().stream().filter(Predicate.not(ValueWrapper::isDelete))
.collect(Collectors.toList()) :
new ArrayList<>(keySet.getValue());
if (!values.isEmpty()) {
values.sort(wrapperComparator);
writer.writeKeysAndValues(key, values);
keyCount++;
valueCount += values.size();
}
}
}
}
LOGGER.fine("Wrote " + keyCount + " keys and " + valueCount + " values");
}
}
We also need a component for merging together bases and delta files, which is developed in
MultiValueLsmTreeMerger. Similar to
GET
operations, the merger leverages the sorted
order of values for removing duplicates and harmonizing
PUT
and
DELETE
operations for the
same values. The core logic for grouping entries and selecting present values is performed in
MultiValueSelectorIterator. For brevity, the code for these two classes isn't included here and
you can visit the linked GitHub pages to see the full code.
Using these components, we develop our
MultiValueLsmTree
using the base class
BaseLsmTree. The base class provides such common functionality as initializing the base/delta files
on open and shutting down internal components on close. We first look at the code for handling
PUT
and
DELETE
operations.
public class MultiValueLsmTree<T extends OutputStream, K, V> ... {
...
@Override public void put(@NotNull K key, @NotNull V value) throws IOException {
internalPut(key, value, false);
}
@Override public void delete(@NotNull K key, @NotNull V value) throws IOException {
internalPut(key, value, true);
}
private void internalPut(@NotNull K key, @NotNull V value, boolean isDelete) throws IOException {
Preconditions.checkState(isUsable());
var writesBlocked = lock.callWithWriteLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
if (isDelete) {
pendingWrites.getWrites().delete(key, value);
} else {
pendingWrites.getWrites().put(key, value);
}
return checkMergeThreshold();
});
if (writesBlocked) {
waitForWritesToUnblock();
}
}
@Override protected MultiValuePendingWrites<K, V> createNewPendingWrites() {
return new MultiValuePendingWrites<>(
new PutAndDeletes<>(configuration.getPendingWritesDeltaThreshold()));
}
@Override protected void sendWritesToCoordinator() {
coordinator.addWrites(pendingWrites);
}
}
You can see that we simply add puts and deletes to the
PutAndDeletes
collection stored in
pendingWrites. After each write operation, we check if the sufficient writes have been accumulate in
memory for writing a new delta file. This is accomplished using the parent class method
checkMergeThreshold(). We simplify override two abstract methods in this concrete class to leverage
this functionality.
Next, we look at the code for handling
GET
operations, which is a bit more complicated because it
has to consider both in-memory and on-disk containers.
public class MultiValueLsmTree<T extends OutputStream, K, V> ... {
...
@NotNull public Result<V> get(@NotNull K key) throws IOException {
Preconditions.checkState(isUsable());
// ordered newest to oldest
var orderedResults = localGetList.get();
orderedResults.clear();
// check current pending writes
addSortedInMemoryValues(orderedResults,
lock.callWithReadLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
return pendingWrites.getWrites().getValues(key);
}));
// check jobs that are actively being written to disk
var jobs = coordinator.getCurrentInFlightJobs();
for (int i = jobs.size() - 1; i >= 0; i--) {
addSortedInMemoryValues(orderedResults,
jobs.get(i).getPendingWrites().getWrites().getValues(key));
}
MultiValueResult<ValueWrapper<V>> baseResults = null;
if (baseDeltaFiles.hasInUseBase()) {
// check delta files
var orderedDeltas = baseDeltaFiles.getOrderedDeltaReaders();
for (int i = orderedDeltas.size() - 1; i >= 0; i--) {
var deltaWrapper = orderedDeltas.get(i);
var deltaResult = deltaWrapper.getLock().callWithReadLock(() ->
deltaWrapper.getReader() == null ? null : deltaWrapper.getReader().get(key));
if (deltaResult != null) {
orderedResults.add(deltaResult);
}
}
// check base file
var baseWrapper = baseDeltaFiles.getBaseWrapper();
baseResults = baseWrapper.getLock().callWithReadLock(() ->
Preconditions.checkNotNull(baseWrapper.getReader()).get(key));
if (baseResults != null) {
orderedResults.add(baseResults);
}
}
if (orderedResults.isEmpty()) {
return MultiValueReadWriteStorage.emptyResult();
} else if (orderedResults.size() == 1) {
return baseResults != null ? new ResultFromBase<>(baseResults) :
new ResultRemovingDeletesSingleSource<>(orderedResults.get(0));
} else {
return new ResultRemovingDeletesMultipleSource<>(orderedResults, valueComparator);
}
}
private void addSortedInMemoryValues(List<MultiValueResult<ValueWrapper<V>>> orderedResults,
List<ValueWrapper<V>> inMemory) {
if (!inMemory.isEmpty()) {
if (inMemory.size() > 1) {
inMemory.sort(valueWrapperComparator);
}
orderedResults.add(new InMemoryMultiValueResult<>(inMemory));
}
}
}
You can see how we go through the various containers in the appropriate order, collecting values for the given key from that container. Add the end, we return a result that combines together the results from the various containers. Optimizations exist for the case where there is only a single container.
The returned
Result
interface comes from the interface
MultiValueReadWriteStorage, which as defined as follows.
MultiValueReadWriteStorage code
public interface MultiValueReadWriteStorage<K, V> extends BaseReadWriteStorage<K, V> {
void put(@NotNull K key, @NotNull V value) throws IOException;
@NotNull Result<V> get(@NotNull K key) throws IOException;
void delete(@NotNull K key, @NotNull V value) throws IOException;
int UNKNOWN_SIZE = -1;
interface Result<V> extends Closeable {
IOIterator<V> iterator();
default int knownSize() { return UNKNOWN_SIZE; }
default int maxSize() { return UNKNOWN_SIZE; }
default List<V> realizeRemainingValues() throws IOException {
var size = knownSize();
if (size == UNKNOWN_SIZE) {
size = maxSize();
if (size == UNKNOWN_SIZE) {
size = 16;
}
}
var list = new ArrayList<V>(size);
var iterator = iterator();
while (iterator.hasNext()) {
list.add(iterator.next());
}
return list;
}
}
static <V> Result<V> emptyResult() { return (Result<V>) EMPTY_RESULT; }
...
}
Concrete implementations of
Result
for our
MultiValueLsmTree
include.
Lastly, we develop a
HashPartitionedMultiValueReadWriteStorage, which allows us create a partitioned
LSMTree
data store. We again generalize the behavior of hash partitioning into a generic
BaseHashPartitionedReadWriteStorage
for use in both the single value and multivalue use cases.
Unit Testing
Unit tests are developed for various newly developed components and you can find their code at the following links.
Additionally, tests are created for the newly developed
MultiValueLsmTree
and these tests perform a
sequence of
PUT,
DELETE, and
GET
requests while verifying that the store
returns the appropriate results. High-level parts of these test are shown in the following code block.
public class MultiValueLsmTreeTest {
...
@Test public void testPutGetDelete() throws IOException {
var lsmTree = createLsmTree(1000);
var tree = lsmTree.getRight();
var key = ByteArrayWrapper.of(1);
var value = ByteArrayWrapper.of(2);
tree.put(key, value);
var res = tree.get(key);
assertThat(res).isNotNull();
var iterator = res.iterator();
assertThat(iterator.hasNext()).isTrue();
assertThat(iterator.next()).isEqualTo(value);
assertThat(iterator.hasNext()).isFalse();
tree.delete(key, value);
res = tree.get(key);
assertThat(res.maxSize()).isEqualTo(1);
iterator = res.iterator();
assertThat(iterator.hasNext()).isFalse();
tree.close();
}
@Test public void testSingleThreaded() throws IOException {
var lsmTree = createLsmTree(1000);
var operations = lsmTree.getLeft();
var tree = lsmTree.getRight();
var count = new AtomicInteger(0);
var tester = MultiValueReadWriteStorageTester.builderForBytes(tree, RandomSeed.CAFE.random(), 4, 6)
.debug(false)
.iterationCallback((ignored) -> {
if (count.incrementAndGet() % 1000 == 0) {
LOGGER.info("iteration " + count.get() + " size " + Dbf0Util.formatBytes(getDirectorySize(operations)));
}
}).build();
tester.testPutDeleteGet(10 * 1000, PutDeleteGet.BALANCED, KnownKeyRate.MID);
tree.close();
}
@Test public void testMultiThread() throws Exception {
var create = createLsmTree(5 * 1000);
var operations = create.getLeft();
var tree = create.getRight();
var errors = new AtomicInteger(0);
var threads = Streams.concat(
Stream.of(
createThread(tree, PutDeleteGet.PUT_HEAVY, KnownKeyRate.LOW, true, errors, operations),
createThread(tree, PutDeleteGet.DELETE_HEAVY, KnownKeyRate.HIGH, false, errors, operations)),
IntStream.range(0, 8).mapToObj(i ->
createThread(tree, PutDeleteGet.GET_HEAVY, KnownKeyRate.HIGH, false, errors, operations)
)).collect(Collectors.toList());
threads.forEach(Thread::start);
for (var thread : threads) {
thread.join();
}
assertThat(errors.get()).isZero();
tree.close();
}
@Test public void testLoadExisting() throws IOException {
var directoryOperations = new MemoryFileDirectoryOperations();
var createLsmTree = (Supplier<MultiValueReadWriteStorage<ByteArrayWrapper, ByteArrayWrapper>>) () ->
MultiValueLsmTree.builderForBytes(
CONFIGURATION.toBuilder().withPendingWritesDeltaThreshold(1000000).build(),
directoryOperations)
.withScheduledThreadPool(2)
.buildWithBackgroundTasks();
var initialTree = createLsmTree.get();
initialTree.initialize();
var map = new HashMap<ByteArrayWrapper, ByteArrayWrapper>();
var random = RandomSeed.CAFE.random();
for (int i = 0; i < 1500; i++) {
var key = ByteArrayWrapper.random(random, 8);
var value = ByteArrayWrapper.random(random, 10);
map.put(key, value);
initialTree.put(key, value);
}
initialTree.close();
var readingTree = createLsmTree.get();
readingTree.initialize();
for (var entry : map.entrySet()) {
assertThat(readingTree.get(entry.getKey()))
.describedAs("key=" + entry.getKey())
.isNotNull()
.extracting(IOFunction.wrap(MultiValueReadWriteStorage.Result::realizeRemainingValues))
.asList()
.hasSize(1)
.first()
.isEqualTo(entry.getValue());
}
readingTree.close();
}
private Thread createThread(MultiValueReadWriteStorage<ByteArrayWrapper, ByteArrayWrapper> tree,
PutDeleteGet putDeleteGet, KnownKeyRate knownKeyRate,
boolean callback, AtomicInteger errors, MemoryFileDirectoryOperations operations) {
var builder = MultiValueReadWriteStorageTester.builderForBytes(tree, new Random(), 16, 4096)
.debug(false);
if (callback) {
var count = new AtomicInteger(0);
builder.iterationCallback((ignored) -> {
assertThat(errors.get()).isZero();
if (count.incrementAndGet() % 1000 == 0) {
LOGGER.info("iteration " + count.get() + " size " + Dbf0Util.formatBytes(getDirectorySize(operations)));
}
});
} else {
builder.iterationCallback((ignored) -> assertThat(errors.get()).isZero());
}
var tester = builder.build();
var name = putDeleteGet.name() + " " + knownKeyRate.name();
return new Thread(() -> {
try {
tester.testPutDeleteGet(10 * 1000, putDeleteGet, knownKeyRate);
LOGGER.info("thread finished " + name);
} catch (Exception e) {
LOGGER.log(Level.SEVERE, "error in " + name + " thread", e);
errors.incrementAndGet();
}
});
}
...
}
Benchmarking
We now develop some benchmarks for our newly developed
MultiValueLsmTree
to quantify the
performance of this new store. As we primarily intend to use this store for secondary index of documents, we
construct benchmarks that capture the behavior of such secondary indexes. The dataset of 147 million Reddit
comments is reused from our
document store benchmarking. Keys are
chosen as attributes that would be useful in a secondary index for this dataset and the following two attributes
are considered.
-
author- The username of the person who wrote the comment -
subreddit- The name of subreddit (i.e., the community) that contains the comment
The comment
id
is used as the value such that one of these stores could serve as a secondary index
for mapping the attribute key to all comments for that attribute.
Benchmarking aims to quantify two aspects of working with secondary indexes: time to build the underlying
multivalue store and performance of fetching all values for a given key. These metrics will help us understand how
the
MultiValueLsmTree
could impact the overall performance of a data store with secondary indexes.
Benchmarking Building a MultiValueLsmTree for Use as a Secondary Index
First, a benchmarking harness is developed for quantifying the time of building a
MultiValueLsmTree
for a specific key attribute, either
author
or
subreddit. We also consider the impact of
store configurations such as partition count, index rate, and degree of multi-threaded concurrency in loading data.
High-level methods of this benchmarking harness are shown in the following code block.
BenchmarkLoadMultiValueDocuments code
public class BenchmarkLoadMultiValueDocuments {
public static void main(String[] args) throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINE, true);
var argsItr = Arrays.asList(args).iterator();
var readFile = new File(argsItr.next());
var directory = new File(argsItr.next());
var idKey = argsItr.next();
var valueKey = argsItr.next();
var pendingWritesMergeThreshold = Integer.parseInt(argsItr.next());
var indexRate = Integer.parseInt(argsItr.next());
var partitions = Integer.parseInt(argsItr.next());
var writingThreadsCount = Integer.parseInt(argsItr.next());
Preconditions.checkState(!argsItr.hasNext());
var base = new FileDirectoryOperationsImpl(directory);
base.mkdirs();
base.clear();
var error = new AtomicBoolean(false);
var readDone = new AtomicBoolean(false);
var writes = new AtomicLong(0);
long startTime;
var executor = Executors.newScheduledThreadPool(
Math.max(2, Runtime.getRuntime().availableProcessors() - writingThreadsCount - 2));
try (var store = createNewStoreWithBackgroundTasks(pendingWritesMergeThreshold, indexRate, partitions, base, executor)) {
store.initialize();
startTime = System.nanoTime();
var reportFuture = executor.scheduleWithFixedDelay(() -> report(error, writes, directory, startTime),
1, 1, TimeUnit.SECONDS);
var queue = new LinkedBlockingQueue<DMap>(1000);
try (var readThread = new ParallelThreads(error, List.of(new Thread(() -> read(error, queue, readFile))))) {
readThread.start();
try (var writeThreads = ParallelThreads.create(error, writingThreadsCount,
i -> new Thread(() -> write(error, readDone, writes, idKey, valueKey, queue, store),
"write-" + i))) {
writeThreads.start();
readThread.awaitCompletion();
readDone.set(true);
if (error.get()) {
readThread.abort();
writeThreads.abort();
} else {
writeThreads.awaitCompletion();
}
}
}
reportFuture.cancel(false);
}
report(error, writes, directory, startTime);
System.exit(error.get() ? 1 : 0);
}
public static void report(AtomicBoolean errors, AtomicLong writes,
File directory, long startTime) {
if (errors.get()) {
return;
}
var time = System.nanoTime();
var size = fileSize(directory);
var writesValue = writes.get();
var stats = ImmutableMap.<String, Object>builder()
.put("time", time)
.put("writes", writesValue)
.put("size", size)
.build();
System.out.println(new Gson().toJson(stats));
LOGGER.info(String.format("%s writes=%.3e size=%s",
Duration.ofNanos(time - startTime),
(double) writesValue,
Dbf0Util.formatBytes(size)));
}
private static void read(AtomicBoolean error, BlockingQueue<DMap> queue, File file) {
var deserializer = DElementDeserializer.defaultCharsetInstance();
try (var stream = new BufferedInputStream(new FileInputStream(file), 0x8000)) {
while (!error.get()) {
DElement element;
try {
element = deserializer.deserialize(stream);
} catch (EndOfStream ignored) {
break;
}
queue.put((DMap) element);
}
} catch (InterruptedException ignored) {
} catch (Exception e) {
error.set(true);
LOGGER.log(Level.SEVERE, e, () -> "Error in reading");
}
}
private static void write(AtomicBoolean error, AtomicBoolean readDone, AtomicLong writes,
String idKey, String valueKey,
BlockingQueue<DMap> queue,
MultiValueReadWriteStorage<DElement, DElement> store) {
var dIdKey = DString.of(idKey);
var dValueKey = valueKey.isEmpty() ? null : DString.of(valueKey);
try {
while (!error.get()) {
var element = queue.poll(100, TimeUnit.MILLISECONDS);
if (element == null) {
if (readDone.get()) {
break;
}
continue;
}
var id = element.getEntries().get(dIdKey);
Preconditions.checkState(id != null, "no such id %s in %s", dIdKey, element);
var value = dValueKey == null ? element : Preconditions.checkNotNull(element.getEntries().get(dValueKey),
"no such value %s in %s", dValueKey, element);
store.put(id, value);
writes.incrementAndGet();
}
} catch (InterruptedException ignored) {
} catch (Exception e) {
error.set(true);
LOGGER.log(Level.SEVERE, e, () -> "Error in writing");
}
}
...
}
Since these multivalue data stores only require a small number of attributes from each of the comments, we first
parse and filter the attributes of the full JSON dataset using the program
ParseAndPruneDocuments. This ensures that benchmarking isn't limited on the performance of
reading and parsing the JSON data. Additionally, the resulting metrics are more useful for determining the
incremental impact of adding secondary index building to a document data store since building the document store
will already entail reading and parsing this data. The resulting parsed and pruned file is roughly 7 GB, which is
substantially smaller than the original JSON data which is 186 GB.
Similar to document store benchmarking, we run an additional step to merge deltas into the base for each store
before using it in subsequent benchmarking using the program
MergedPartitionedMultiValueLsmTreeDeltas. Lastly, the program
multivalue.GetKeys
is used to extract all keys for use in subsequent
GET
key
benchmarking.
Benchmarking GET All Values for a Key
Next, we develop a benchmarking harness for quantifying the performance of fetching all values for each key when
randomly selecting keys. Each benchmarking trial is ran for five minutes and we count the number of
GET
operations performed. We also count the total number of values retrieved during each trial across
all
GET
operations. Results are reported every 30 seconds so that we can check if there is any time
dependence of performance.
Additionally, we quantify the latency of each
GET
request using the Java runtime's nanosecond
resolution clock. It wouldn't be possible to report every single observation latency as tens to hundreds of
millions of
GET
operations are performed in each benchmarking trial. Instead, we approximate the
distribution of latencies using a
t-digest data structure. This is an interesting probabilistic data structure that allows for a space and time
efficient approximation of a distribution. We'll explore the details of this data structure in a future project.
For now, it suffices to know that we can approximate the
GET
latency distribution using this
algorithm.
As we expect latency to vary based upon the number of values for a given key, we collect multiple
t-digest
instances, each for a different range of value counts. Ranges are chosen on a base-10
logarithmic scale as analysis of the distribution of values per a key showed some keys with over a million values.
(
Details in the analysis section of this project
)
Merging can be performed on t-digest data structures and this allows us to calculate the distribution across all
value count bins to quantify the overall distribution of latency. Such merging is also used to average together
results from different 30 second reported intervals to determine the latency distributions across the entire
benchmarking trial.
High-level components of the
GET
benchmarking harness are shown in the following code block and you
can find the full code at the linked GitHub page.
BenchmarkGetMultiValueDocuments code
public class BenchmarkGetMultiValueDocuments {
private static final Logger LOGGER = Dbf0Util.getLogger(BenchmarkGetMultiValueDocuments.class);
public static final List<Integer> BIN_EDGES = IntStream.range(0, 7)
.map(i -> (int) Math.pow(10.0, i)).boxed()
.collect(Collectors.toList());
public static void main(String[] args) throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINE, true);
var argsItr = Arrays.asList(args).iterator();
var root = new File(argsItr.next());
var keysPath = new File(argsItr.next());
var getThreads = Integer.parseInt(argsItr.next());
var duration = Duration.parse(argsItr.next());
var reportFrequency = Duration.parse(argsItr.next());
Preconditions.checkState(!argsItr.hasNext());
Preconditions.checkState(root.isDirectory());
Preconditions.checkState(keysPath.isFile());
var keys = loadKeys(keysPath);
var executor = Executors.newScheduledThreadPool(
Math.max(2, Runtime.getRuntime().availableProcessors() - getThreads - 1));
try (var store = open(root, executor)) {
store.initialize();
var error = new AtomicBoolean(false);
var done = new AtomicBoolean(false);
var getKeys = new AtomicLong(0);
var getValues = new AtomicLong(0);
var binnedDurationQuantiles = new AtomicReference<>(new BinnedDurationQuantiles(BIN_EDGES));
long startTime;
try (var threads = ParallelThreads.create(error, getThreads, i -> new Thread(() ->
getThread(error, done, getKeys, getValues, binnedDurationQuantiles, keys, store)))) {
startTime = System.nanoTime();
var doneFuture = executor.schedule(() -> done.set(true), duration.toMillis(), TimeUnit.MILLISECONDS);
var reportFuture = executor.scheduleWithFixedDelay(() ->
report(error, getKeys, getValues, root, startTime, binnedDurationQuantiles),
0, reportFrequency.toMillis(), TimeUnit.MILLISECONDS);
threads.start();
threads.awaitCompletion();
if (!doneFuture.isDone()) doneFuture.cancel(false);
reportFuture.cancel(false);
if (error.get()) threads.abort();
}
report(error, getKeys, getValues, root, startTime, binnedDurationQuantiles);
}
}
private static void report(AtomicBoolean error, AtomicLong atomicGetsKeys, AtomicLong atomicGetsValues,
File directory, long startTime,
AtomicReference<BinnedDurationQuantiles> binnedDurationQuantiles) {
if (error.get()) {
return;
}
var b = binnedDurationQuantiles.getAndSet(new BinnedDurationQuantiles(BIN_EDGES));
var time = System.nanoTime();
var size = fileSize(directory);
var getKeys = atomicGetsKeys.get();
var getValues = atomicGetsValues.get();
var stats = ImmutableMap.<String, Object>builder()
.put("time", time)
.put("getKeys", getKeys)
.put("getValues", getValues)
.put("size", size)
.put("stats", b.jsonStats())
.build();
System.out.println(new Gson().toJson(stats));
LOGGER.info(String.format("%s getKeys=%.3e getValues=%.3e size=%s",
Duration.ofNanos(time - startTime),
(double) getKeys, (double) getValues,
Dbf0Util.formatBytes(size)));
}
private static void getThread(AtomicBoolean error, AtomicBoolean done,
AtomicLong atomicGetsKeys, AtomicLong atomicGetsValues,
AtomicReference<BinnedDurationQuantiles> binnedDurationQuantiles, List<DString> keys,
MultiValueReadWriteStorage<DElement, DElement> store) {
try {
var random = new Random();
while (!error.get() && !done.get()) {
var key = keys.get(random.nextInt(keys.size()));
int count = 0;
long start = System.nanoTime();
try (var value = store.get(key)) {
if (value.maxSize() == 0) {
throw new RuntimeException("No value for " + key);
}
var iterator = value.iterator();
while (iterator.hasNext()) {
iterator.next();
count++;
}
}
long durationNs = System.nanoTime() - start;
atomicGetsKeys.getAndIncrement();
atomicGetsValues.getAndAdd(count);
double durationMs = (double) durationNs / 1e6;
binnedDurationQuantiles.get().record(count, durationMs);
}
} catch (Exception e) {
LOGGER.log(Level.SEVERE, "Error in get", e);
error.set(true);
}
}
private static class BinnedDurationQuantiles {
private final TreeMap<Integer, Bin> bins = new TreeMap<>();
public BinnedDurationQuantiles(Iterable<Integer> binEdges) {
binEdges.forEach(i -> bins.put(i, new Bin()));
}
public void record(int count, double duration) {
var bin = bins.floorEntry(count);
if (bin == null) {
throw new IllegalArgumentException("Bad count " + count);
}
bin.getValue().record(duration);
}
public JsonArray jsonStats() {
var entries = new JsonArray(bins.size());
for (var bin : bins.entrySet()) {
var entry = bin.getValue().jsonStats();
if (entry != null) {
entry.addProperty("floor", bin.getKey());
entries.add(entry);
}
}
return entries;
}
}
private static class Bin {
private final TDigest tDigest = TDigest.createDigest(100);
private synchronized void record(double duration) {
tDigest.add(duration);
}
@Nullable private JsonObject jsonStats() {
var size = tDigest.size();
if (size == 0) {
return null;
}
var entry = new JsonObject();
entry.addProperty("count", size);
byte[] bytes;
synchronized (this) {
bytes = new byte[tDigest.smallByteSize()];
tDigest.asSmallBytes(ByteBuffer.wrap(bytes));
}
var base64 = Base64.getEncoder().encodeToString(bytes);
entry.addProperty("tDigest", base64);
return entry;
}
}
...
}
We use the same EC2 instance types as described in document store benchmarking for present benchmarking.
Analysis of Benchmarking Results
Computing Distributions of Values per a Key
We begin our analysis by first computing the distribution of values (i.e., comments) per a key for each of the
two keys considered;
author
and
subreddit. These statistics will inform subsequent
analysis of benchmarking performance. The following two tables show the top five keys for each key type as
quantified by number of values per a key.
| author | Count |
|---|---|
| [deleted] | 13,984,910 |
| AutoModerator | 2,059,516 |
| KeepingDankMemesDank | 206,701 |
| Edgar_The_Pug_Bot | 194,661 |
| transcribot | 87,577 |
| subreddit | Count |
|---|---|
| AskReddit | 7,764,782 |
| memes | 2,011,934 |
| teenagers | 1,977,753 |
| politics | 1,962,575 |
| dankmemes | 1,683,921 |
We can see that some key values are associated with millions of comments. Of particular interested in the
[deleted]
author value, which corresponds to comments that were removed by the user or moderators.
Next, we compute the distribution of values-per-a-key for each of these two key types.
| Key | Key Count | Mean | Min | 25% | 50% | 75% | 90% | 95% | 99% | 99.9% | 99.99% | Max |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| subreddit | 151,005 | 972.5 | 1 | 1 | 5 | 34 | 331 | 1,385 | 14,575 | 128,401 | 701,832 | 7,764,782 |
| author | 7,044,848 | 20.8 | 1 | 1 | 4 | 12 | 39 | 77 | 246 | 747 | 1,802 | 13,984,910 |
For both key types, the median is quite small relative the maximum values with median values-per-a-key of 4 and 5. Both distribution show long tails with a small number of keys associated with hundreds of thousands or even millions of keys. As a result, the mean values-per-a-key is significantly larger than the median. We also see that there are far more unique authors than subreddits with 7 million unique authors and 150 thousand unique subreddits. The cumulative distributions are plotted in the following figure to better visualize how the two distributions differ.
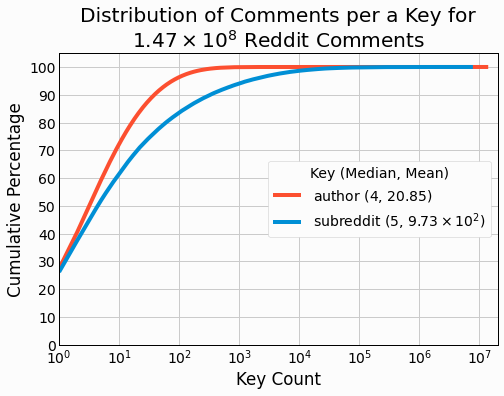
We see that most authors are associated with a smaller number of comments than subreddits, yet the special
author value of
[deleted]
results in the
author
distribution having a larger maximum
value. It will be interesting to see how the different distributions and key counts will impact the performance in
benchmarking.
Analysis of Index Building
We calculate the total time for index building of each trial and from this determine the rate of key/value entry
PUT
operations. For each key type, index rate, and partition count, we determine the number of
concurrent writing threads that maximizes index building rate. These results are summarized in the following bar
plots with different partition counts highlighted by bar color.
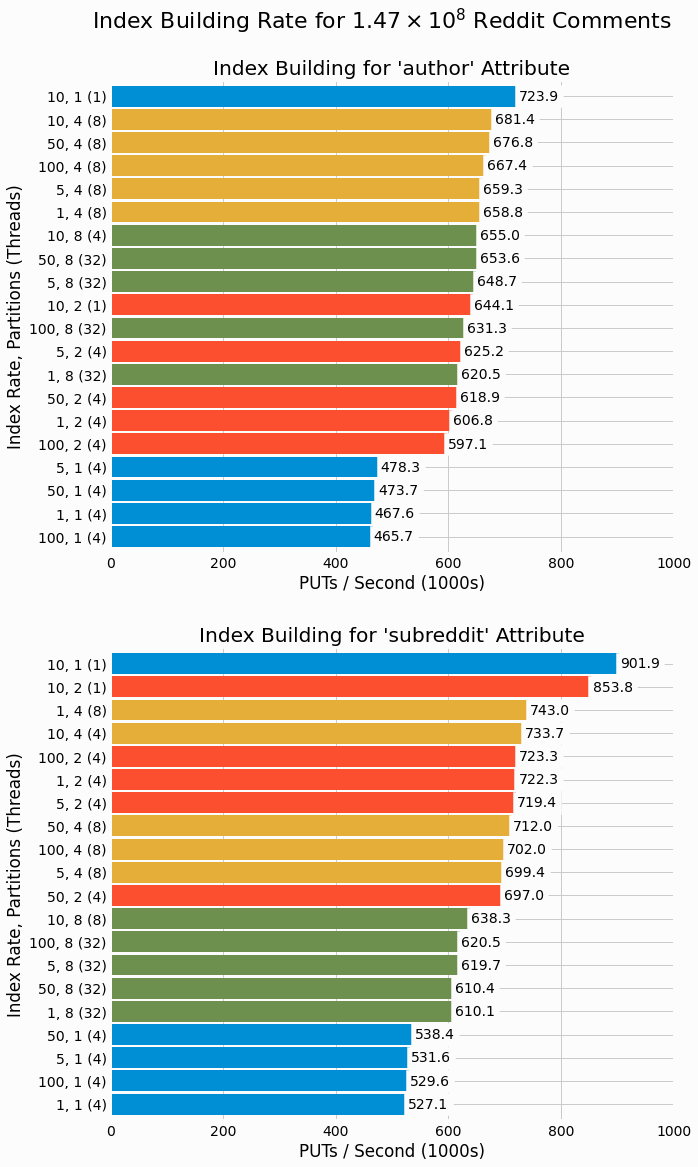
These results are quite interesting in that both key types achieve maximal performance with moderate index
building rate of 10 and just a single partition and single concurrent writing thread. For
author, the
next highest performing trials all have 4 partitions and use 8 threads. Where as for
subreddit, we
see a mix of 2 partitions and 4 partitions among the next highest performing cases. All other single partition
cases rank in at the bottom of
PUT
performance for both key types. We'll consider why this is the case
in the discussion section of the project.
Next, we analyze the time dependence of index building performance to see how this varies over time. The following figure shows results for both key types with index rate of 10. Results are shown for different partition counts, each at their optimal thread count. Individual data points are shown as partially transparent circles and cubic splines show a smoothing of the results as plotted lines.
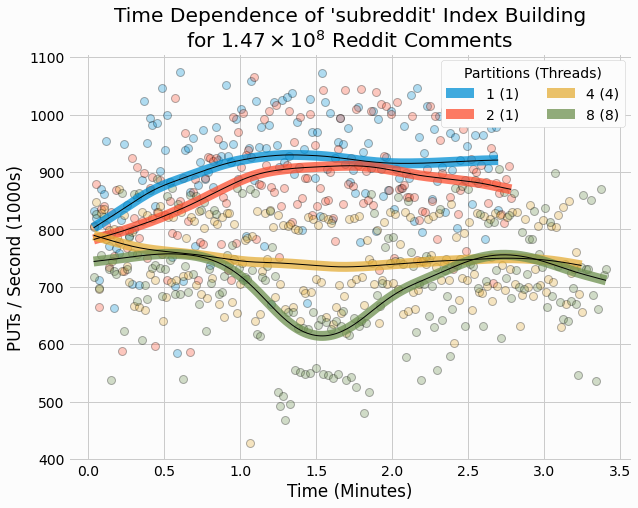
In general, there isn't a common pattern in time dependence. For partition count 1 and 2, there is a moderate increase in performance over the first minute. In contrast, partition count 4 shows a moderate decrease in the same time period. Lastly, partition count 8 shows shows a dip at intermediate times. Overall, the changes with time are small to moderate and its possible the observed variations would change if we repeated the trials.
We also analyze the time dependence of store sizes for these same trials.
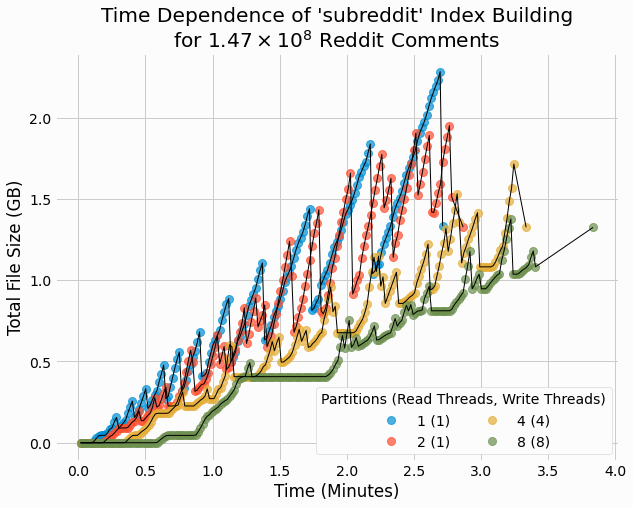
These results are similar to the earlier results for size of partitioned store over time, with size generally increasing and occasional large sudden drops. Such drops were previously attributed to the end of delta/base merging, after which the old delta and base files are deleted. Note that all of the final sizes are on the order of 1.4 GB, which is significantly smaller than the parsed a pruned data size of 7 GB. This can be explained by key de-duplication in that each key is stored multiple times in the input data, but only once in the multivalue key/value store.
Across all trials there is moderate variation in store size, even with different index rates. For
subreddit
all stores are within a few MBs of 1.32 GB.
author
stores are slighly larger,
with most being around 1.42 GB. The store with index rate of 1, i.e., including every key in the index file, is
slightly larger at 1.53 GB. The larger store size for
author
relative to
subreddit
is due
to the larger number of unique authors (7 million) than subreddits (150 thousand).
Analysis of GET Values for a Key, Rates
We next analyze the perform of fetching all values for a key through
GET
operations. We again
compute the overall performance, this time quantified by
GET
keys/second. The following figure shows
how performance varies with concurrent reading threads for different partition counts, all with an index rate of
10.
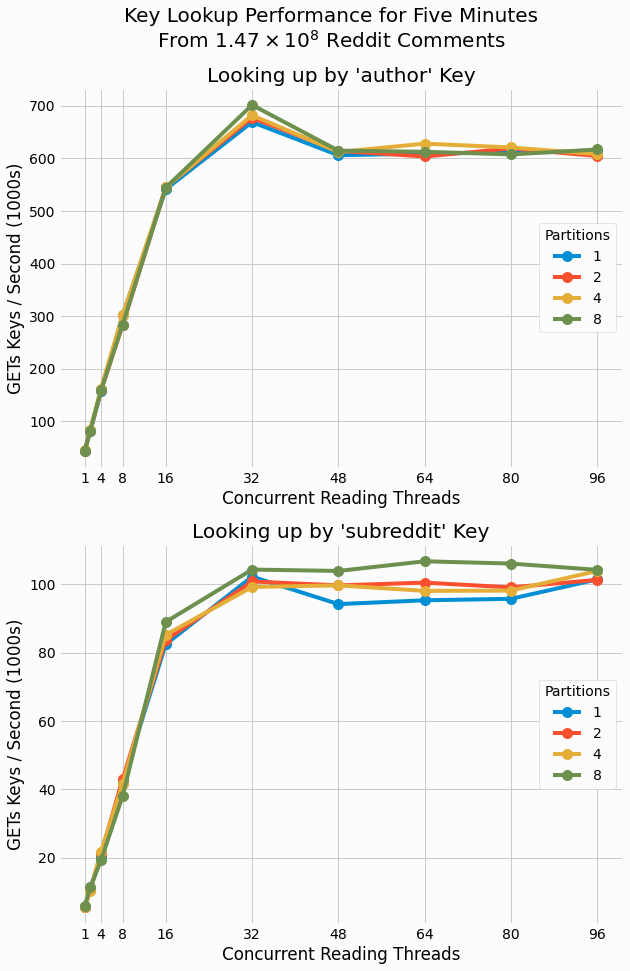
Partition count is found to have a minor impact on overall performance. This is consistent with what we saw
earlier in
GET
performance
benchmarking of a document
store. The earlier results were explained as lack of lock contention in these read-only trials. A maximum
GET
rate of roughly 70k/second were observed in these earlier result fetching full documents and it
interesting that the multivalue stores outperform these past results for both key types despite having to read all
values for a key.
We also see a large difference between key
GET
rates for the two scenarios with
author
results maxing out around 700k/second whereas
subreddit
maxes out at roughly 100k/second. This can
likely be explained by the mean
subreddit
key being associated with 973 comments whereas for
author
a mean value is just 21 comments.
We now investigate how index rate impacts performance. The following figure shows the scaling of performance with thread count with different index rates using a single partition.
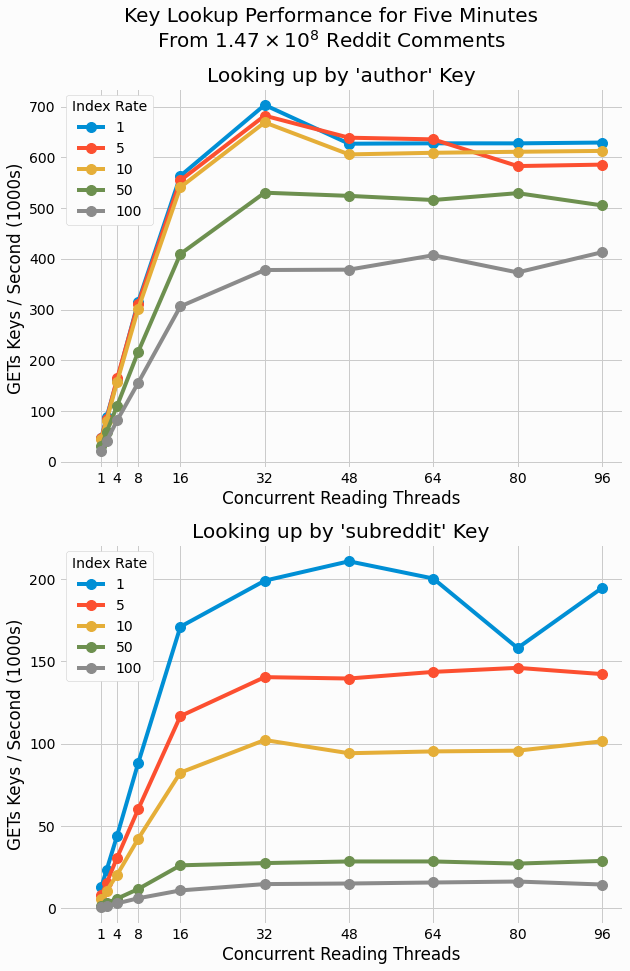
For both key types, more frequent indexing results in superior performance, although for
author
small improvements are seen beyond indexing every 10 keys. In contrast,
subreddit
continues to
substantially improve with more frequent indexing with indexing every single key resulting in significantly higher
performance. These results can also be attribute to
subreddit
keys being associated too many more
comments than
author
keys.
We also analyze the performance in terms of values read per a second as shown in the following figure.
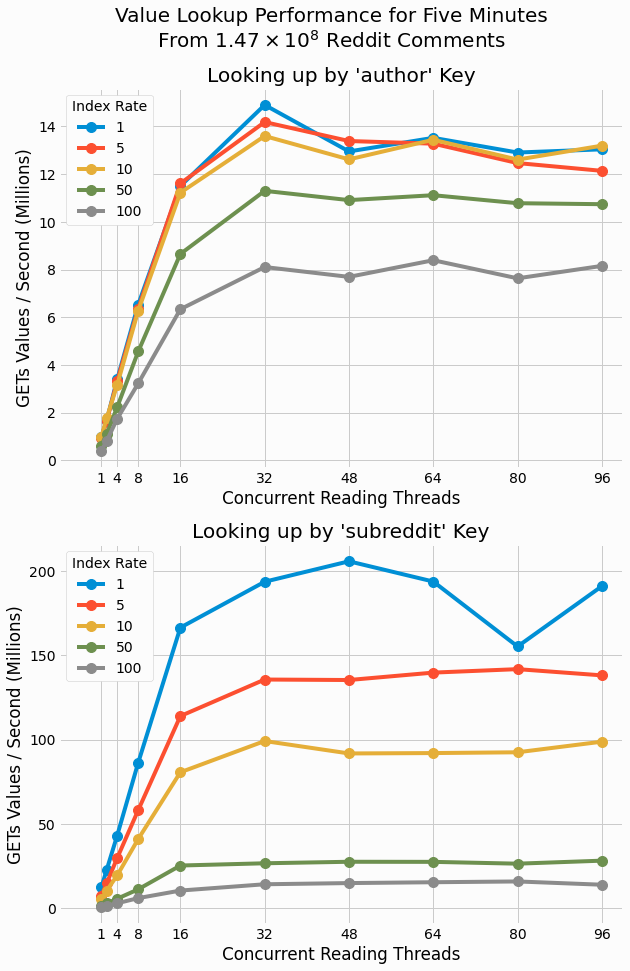
Interestingly, we can now see
subreddit
outperforming
author
with comment id value
GET
rates as high as 200 million/second whereas
author
maxes out at 14 million/second.
Again, the different in average values per a key explains the difference in that for
subreddit
many
more values can be fetched with a single key lookup. It is noteworthy that these value fetch rates are in the tens
of millions to hundreds of millions which shows that we can fetch the comment ids for a secondary key at orders of
magnitude higher performance than we can fetch the comment document associated with a comment id. Hence, we can
expect that secondary index lookups will not be the bottleneck once we start using these multivalue stores as
secondary indexes.
Analysis of GET Values for a Key, Latency
Lastly, we analyze the distribution of latencies for fetching all values associated with a key. There is quite a bit of data to analyze since we have a latency distribution for each of the binned ranges of value counts, for each 30 second reporting time interval, for each trial. To get some high-level insights into latency, distribution are averaged across different bins and time intervals to give an average time distribution for each trial.
The following figure shows how the latency distribution scales with thread count for different index rates with a single partition store. Median latency is shown as circles and individual data points are connected by plotting lines to guide the eye. Additionally, the interquartile range for each trial is shown with error bars. Lastly, outliers for the 90%-th, 99.9%-th, and 100%-th (maximum) percentiles are shown as markers as labeled on the plot. Latency is shown on a log scale since latency value span multiple orders of magnitude.
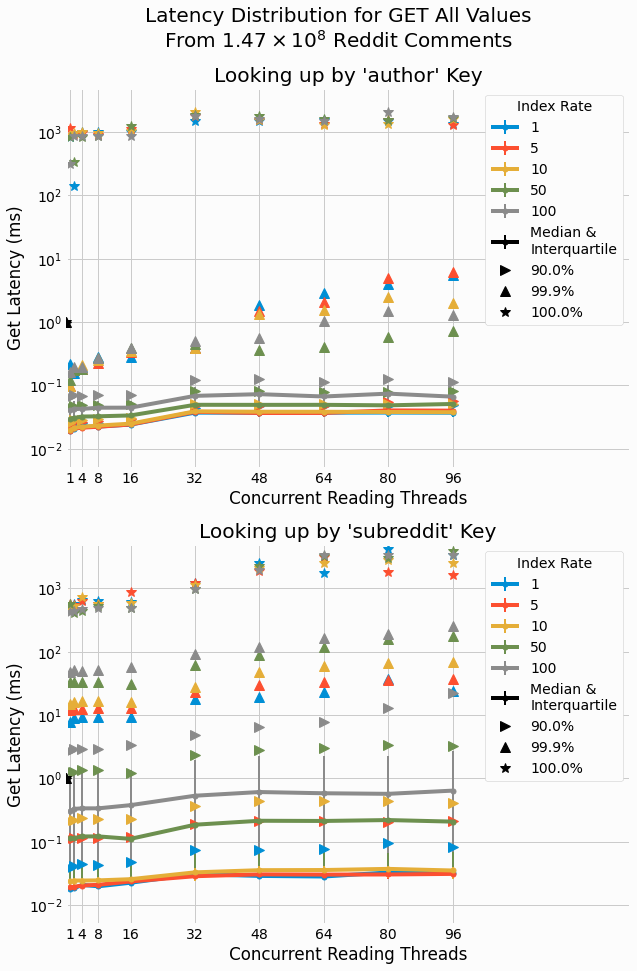
We see that latency scales from roughly 14 microseconds up to 1.1 second showing a span of almost five orders of
magnitude. The large range of latency values can also be attributed to the large spread in values-per-a-key, with
many keys only having a single value where as others have millions. Increasing index frequency (i.e., decreasing
index rate) is found to significantly lower latency, which relates to what we saw earlier for the impact of index
rate on overall performance as quantified by
GET
operations per a second. A moderate (on a log scale)
increase in latency is seen when increasing thread count as could be explained by IO and compute contention among
reading threads.
A similar analysis is performed for constant index rate and different partition count to determine if partitioning impacts latency. It does not and results are not included for brevity. This is consistent with the results for overall performance where we already saw near identical results for different partition counts.
Next, we look into how
GET
latency is related to the number of values associated with a key. For
each trial, distributions from different reporting time interval for the same value count bin are combined together
to give a time-averaged latency distribution. The cumulative distribution are plotted in the following figure for
both key types for trials with 1 partition, index rate of 10, and 32 threads. Different value count bins are
denoted by different plotting color as labeled on the figure. Additionally, the legend entry for each distribution
includes the number of
GET
observations in the bin as well as the median latency for the distribution.
The averaged distribution over all bins is also shown with a dashed black line. Note the log scale x-axis showing
latency.
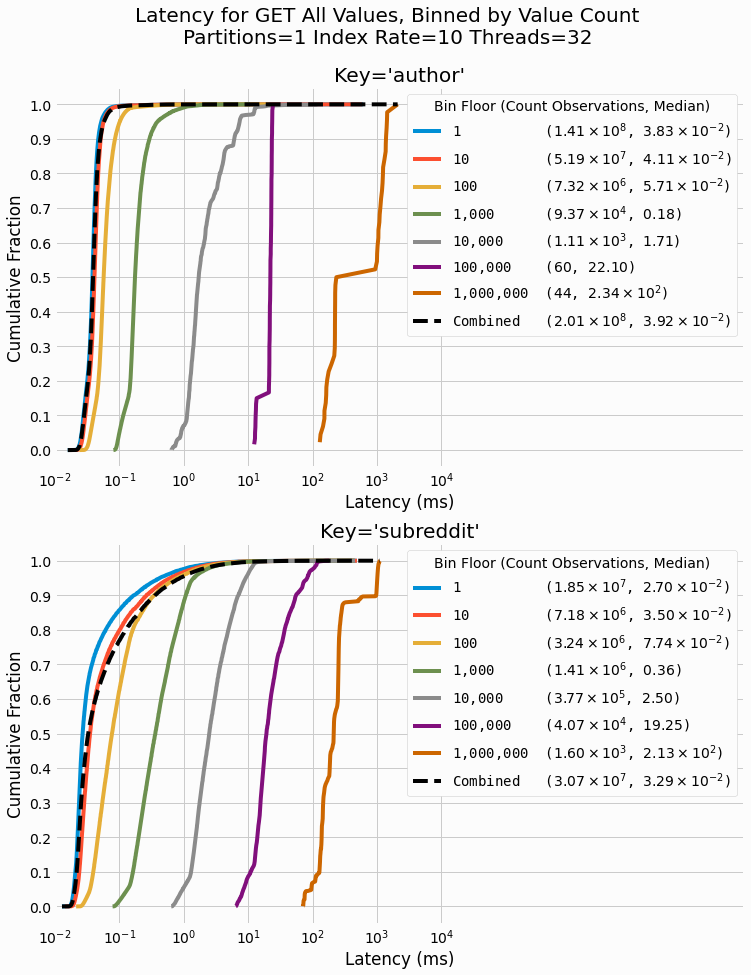
We can clearly see how the large range of latency is due to the large range of values-per-a-key. The lowest
bins, containing results for keys with between 1 and 9 values, shows medians latency on the order of 27 to 38
microseconds. The largest bins, for keys with more than a million values, has medians on the order of 0.2 seconds.
A clear progression of the distributions shifting to the right (i.e., higher latency) with higher value-count bins
is seen in these results. The averaged latency distributions across all bins are found to be dominated by the
performance of lower value count keys (less than 100) since these keys are so numerous. For
author
key, the average results, bin 1-9, and bin 10-99 are all near coinciding on this log scale latency.
Lastly, we check if there is any time dependency of latency. For individual trials, quantiles of the
distributions are plotted over time and in general no variance with time is observed. The following figure shows
results for
author
key with a 1 partition, index rate of 10, and 32 threads.
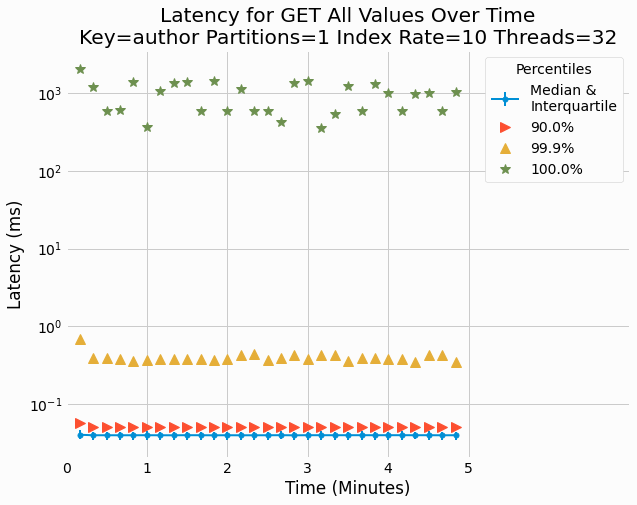
Results for other trials are also investigated and no time-dependence is found in any of those checked.
Consistency of latencies over time is consistent with what we observe for
GET
rate time
dependence.
Discussion and Next Steps
The development of multivalue storage unlocks the development of secondary indexes in our next project since individual secondary keys can now be associated with multiple primary keys. It is convenient that we developed our multivalue storage by simply generalizing our single value LSMTree and creating another LSMTree implementation that supports multiple values. Many other components from past projects are also used in the new multivalue LSMTree, including the generic serialization protocols allowing for storage of different key and value types using different serialization protocol implementations.
In benchmarking and analyzing the performance of multivalue key store, we find many results that are similar to
those of
the single value LSMTree. Chiefly that
read-only performance isn't impacted by partitioning since there is no lock contention among
GET
operations in different threads. We also find minor, if any, time-dependence in performance of store construction
and
GET
performance, which is also consistent with single value LSMtree results.
One interesting observation consists of the highest performance of store building occurring for single partition stores with index rate of 10 and a single thread. This is seen for both key types. In contrast, all other single partition count results, with either higher or lower index rates, under perform relative to higher partition count stores. These results don't make much sense and may be artifacts of order in which benchmarking trials were performed.
All trials were performed sequentially on a single machine and single partition stores trials were performed first. Its possible that these trials benefited from the host machine starting with a low initial load and lack of any pending disk writes that need to written from the OS page cache to the disk drive. I'm not convinced that this theory totally explains the results since we'd expect other single partition results to get some benefit from being ran before larger partition counts. Overall, these results might simply be artifacts of the small datasets considered and only running a single trial for each scenario.
Its noteworthy that the lowest index building rates exceed 400k
PUT
per a seconds, which is
substantially higher than the highest document store
PUT
rate of 155k observed in our
previous document store benchmarking. Therefore index building
substantially outperforms general document store building and we shouldn't expect the addition of secondary indexes
to a document store to substantially slow store construction. We'll quantify that in our future secondary index
project.
The latency in fetching all value for a given key is found to span almost five orders of magnitude; from roughly 14 microseconds up to 1.1 seconds. In analyzing the latency distributions binned by value for count for the fetched key, we find that the large range of values results from the large range of values per a key. Many keys only have a single value but at the extreme some keys have millions of values.
We'll be using our newly developed multivalue LSMTree in our next project to create secondary indexes for a document store. The ability to add secondary indexes to a data store is an important feature for many applications and it will quite exciting to implement this for our prototype database. I'm currently developing our secondary indexing project so check back soon to learn how we develop secondary indexes and benchmark their performance.