
Document Storage Engine for Semi-Structured Data
We extend our partitioned, log-structured merge-tree key/value store to store documents of semi-structured objects (e.g., JSON). The new storage engine is benchmarked using 147 million Reddit comments (185 GB) to quantifies performance loading documents, getting stored documents, and updating them.
Introduction
Our previously developed partitioned, log-structured merge-tree (LSMTree) key/value store only supports byte array keys and values. This limits the functionality that the storage engine can provide for an application. To support additional functionality such as secondary indexes and partial gets and updates, the storage engine needs to understand the content of keys and values. Extending the storage engine to work with documents consisting of semi-structured objects will allow us to develop secondary indexes and partial operations in future projects.
In this project, you'll learn how to represent and serialize documents for use in a storage engine. Further, we
also benchmark the performance of our new storage engine using a large dataset consisting of 147 million Reddit
comments. We quantify the performance of loading these comments and investigate how multi-threading and
partitioning can enhance performance. Additionally, we quantify performance for simple
GET
operations
as well as updates in which entries are modified through
GET
and subsequent
PUT
operations.
You can find the full code for this project within the DBFromZero Java repository on GitHub to read, modify, and run yourself.
Storing Documents (i.e., Semi-Structured Data)
In the context of this project, document refers to semi-structured data using a data model similar to JSON. Unlike a relational database, there is no global schema and instead each key or value can flexibly take any structure within the allowed types. Document stores are a type of key/value store that allows for these semi-structured key and/or values. Such database commonly provide features beyond key/value stores such as secondary indexes using attributes of the value.
To provide a concrete example, we'll consider Reddit comment data provided by pushshift.io. Each comment is encoded in JSON format as shown in the following example.
{
"all_awardings": [],
"associated_award": null,
"author": "frankylovee",
"author_created_utc": 1440098192,
"author_flair_background_color": null,
"author_flair_css_class": null,
"author_flair_richtext": [],
"author_flair_template_id": null,
"author_flair_text": null,
"author_flair_text_color": null,
"author_flair_type": "text",
"author_fullname": "t2_ppvut",
"author_patreon_flair": false,
"awarders": [],
"body": "I try not to feed my cat when she screams at me, but she literally will not stop until I do.\n\nEdit: cat tax https://imgur.com/gallery/v70Fh85",
"can_gild": true,
"can_mod_post": false,
"collapsed": false,
"collapsed_reason": null,
"controversiality": 0,
"created_utc": 1564617600,
"distinguished": null,
"edited": 1564710503,
"gilded": 0,
"gildings": {},
"id": "evn2i5p",
"is_submitter": false,
"link_id": "t3_ckej3g",
"locked": false,
"no_follow": true,
"parent_id": "t3_ckej3g",
"permalink": "/r/AnimalsBeingJerks/comments/ckej3g/dont_encourage_the_screaming_kitten/evn2i5p/",
"quarantined": false,
"removal_reason": null,
"retrieved_on": 1573370605,
"score": 109,
"send_replies": true,
"steward_reports": [],
"stickied": false,
"subreddit": "AnimalsBeingJerks",
"subreddit_id": "t5_2wfjv",
"subreddit_name_prefixed": "r/AnimalsBeingJerks",
"subreddit_type": "public",
"total_awards_received": 0
}
You can see that the comment takes the form of a JSON object with values of various types, including composite values that are either objects or arrays.
Developing Document Storage
There are a series of steps to extend our partitioned (LSMTree) key/value store to support semi-structured keys and values. We first develop a data model for documents. Next our storage engine is generalized to use generic serialization protocols. Lastly, we develop an efficient serialization protocol for our newly developed document data model.
Defining Document Elements
As a starting point, we develop our data model for semi-structured data. A class is developed for each type of
data supported in this model. All of these classes extend a common abstract class
DElement, which
provides some minimal basic functionality and also provides a base type that any element can be cast to.
public abstract class DElement implements Comparable<DElement> {
@NotNull public abstract DElementType getType();
protected abstract int compareToSameType(DElement o);
@Override public int compareTo(@NotNull DElement o) {
if (this == o) {
return 0;
}
var thisType = getType();
var thatType = o.getType();
if (thisType != thatType) {
return Integer.compare(thisType.getTypeCode(), thatType.getTypeCode());
}
return compareToSameType(o);
}
...
}
DElement
provides base functionality for defining the ordering between
DEelement
instances of different types using the
DElementType
enum. Comparison of instances of the same type is delegated to the derived classes. Additionally, each derived
class also provides functionality for
equals,
hashCode, and
toString.
For example, here is how we model integer values in our data model.
public final class DInt extends DElement {
private final long value;
public DInt(long value) {
this.value = value;
}
public long getValue() {
return value;
}
@Override public @NotNull DElementType getType() {
return DElementType.INT;
}
@Override protected int compareToSameType(DElement o) {
return Long.compare(value, ((DInt) o).value);
}
@Override public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
DInt dInt = (DInt) o;
return value == dInt.value;
}
@Override public int hashCode() {
return (int) (value ^ (value >>> 32));
}
@Override public String toString() {
return "DInt{" + value + "}";
}
}
The following data type classes are developed.
The last two,
DArray
and
DMap, are container types that hold other
DElement
instances.
Converting Between Documents and JSON
To support creating document from JSON, a
gson
TypeAdapter
is created.
gson
is an excellent open source library for working with JSON in
Java, developed by Google. A
TypeAdapter
class allows an application to define how a custom type can
be converted to and from JSON and the following code shows how this accomplished for
DElement
types.
public class DElementTypeAdapter extends TypeAdapter<DElement> {
...
@Override public DElement read(JsonReader in) throws IOException {
switch (in.peek()) {
case STRING:
return new DString(in.nextString());
case NUMBER:
var number = in.nextString();
return DECIMAL_COMPONENTS_PATTERN.matcher(number).find() ?
DDecimal.of(new BigDecimal(number)) : DInt.of(Long.parseLong(number));
case BOOLEAN:
return DBool.of(in.nextBoolean());
case NULL:
in.nextNull();
return DNull.getInstance();
case BEGIN_ARRAY:
ImmutableList.Builder<DElement> elements = ImmutableList.builder();
in.beginArray();
while (in.hasNext()) {
elements.add(read(in));
}
in.endArray();
return DArray.of(elements.build());
case BEGIN_OBJECT:
ImmutableMap.Builder<DElement, DElement> entries = ImmutableMap.builder();
in.beginObject();
while (in.hasNext()) {
entries.put(new DString(in.nextName()), read(in));
}
in.endObject();
return DMap.of(entries.build());
case END_DOCUMENT:
case NAME:
case END_OBJECT:
case END_ARRAY:
default:
throw new IllegalArgumentException();
}
}
@Override public void write(JsonWriter out, DElement value) throws IOException {
if (value == null) {
out.nullValue();
return;
}
var type = value.getType();
switch (type) {
case NULL:
out.nullValue();
break;
case BOOL:
out.value(((DBool) value).isTrue());
break;
case INT:
out.value(((DInt) value).getValue());
break;
case DECIMAL:
out.value(((DDecimal) value).getValue());
break;
case STRING:
out.value(((DString) value).getValue());
break;
case ARRAY:
out.beginArray();
for (var element : ((DArray) value).getElements()) {
write(out, element);
}
out.endArray();
break;
case MAP:
out.beginObject();
for (var entry : ((DMap) value).getEntries().entrySet()) {
var key = entry.getKey();
if (!(key instanceof DString)) {
throw new IllegalArgumentException("Cannot convert document key " + key + " to a json object name");
}
out.name(((DString) key).getValue());
write(out, entry.getValue());
}
out.endObject();
break;
default:
throw new RuntimeException("Unhandled type " + type);
}
}
}
Defining Generic Serialization
We now tackle the challenge of storing documents by extending our existing storage engine initially designed for
byte arrays. Rather than just developing new functionality specifically for document storage, we instead generalize
the storage engine by introducing generic interfaces for serialization and deserialization. Implementations of
these interfaces can then be developed to support any data type of interest. The generic interfaces
Serializer<T>
and
Deserializer<T>
for generic type
T
are defined
as follows.
public interface Serializer<T> {
int SIZE_UNKNOWN = -1;
void serialize(OutputStream s, T x) throws IOException;
/**
* Returns the best estimate serialized size of element {@code x} in bytes
* or {@code SIZE_UNKNOWN} if an estimation isn't possible. Errors on the side
* of overestimating when there is uncertainty.
*/
default int estimateSerializedSize(T x) {
return SIZE_UNKNOWN;
}
@NotNull default ByteArrayWrapper serializeToBytes(T x) throws IOException {
var estimatedSize = estimateSerializedSize(x);
var stream = new ByteArrayOutputStream(estimatedSize == SIZE_UNKNOWN ? 1024 : estimatedSize);
serialize(stream, x);
return ByteArrayWrapper.of(stream.toByteArray());
}
default boolean isByteArrayEquivalent() {
return false;
}
}
public interface Deserializer<T> {
@NotNull T deserialize(InputStream s) throws IOException;
@NotNull default T deserialize(ByteArrayWrapper w) throws IOException {
return deserialize(new ByteArrayInputStream(w.getArray()));
}
default void skipDeserialize(InputStream s) throws IOException {
deserialize(s);
}
}
To support our previous use case of byte array keys and values, the following serialization and deserialization classes are developed.
public class ByteArraySerializer implements Serializer<ByteArrayWrapper> {
...
@Override public void serialize(OutputStream s, ByteArrayWrapper x) throws IOException {
var a = x.getArray();
IOUtil.writeVariableLengthUnsignedInt(s, x.length());
s.write(a);
}
@Override public int estimateSerializedSize(ByteArrayWrapper x) {
var a = x.getArray();
return IOUtil.sizeUnsignedLong(a.length) + a.length;
}
}
public class ByteArrayDeserializer implements Deserializer<ByteArrayWrapper> {
...
@NotNull @Override public ByteArrayWrapper deserialize(InputStream s) throws IOException {
int size = IOUtil.readVariableLengthUnsignedInt(s);
var bytes = new byte[size];
IOUtil.readArrayFully(s, bytes);
return ByteArrayWrapper.of(bytes);
}
@Override public void skipDeserialize(InputStream s) throws IOException {
IOUtil.skip(s, IOUtil.readVariableLengthUnsignedInt(s));
}
}
Additionally, a
SizePrefixedSerializer
is developed for wrapping another
Serializer. It writes each serialized entry as a size-prefixed
block of bytes, which allows for efficiently skipping an entire value when scanning through a key/value file in
searching for a specific key. Further, the structure of serialized entries is analogous to the
ByteArraySerializer
and this allows entries to be read and written as byte arrays. This functionality
is useful when we don't care about the details of values as occurs in our
LSMTree
delta/base file
merging.
SizePrefixedSerializer.isByteArrayEquivalent()
returns true to indicate this
functionality.
Document Serialization
We next develop serialization and deserialization classes for our newly created document data model. We could
simply encode these values as JSON strings and use our
DElementTypeAdapter
to convert between JSON
strings and our data model. While such an approach would be simple, we can develop a more efficient serialization
protocol that will be use less space on disk and also require less computation in serialization and
deserialization.
Our protocol is based around a prefix encoding whereby each element uses a single byte to specify its type in
the serialized format. The enum
DElementSerializationType
defines a unique serialization code for each data type in our data
model. Additionally, different types are defined for positive and negative integers as simplifies the
serialization. A generic routine is developed for serializing unsigned integers and negative integers are
serialized as their absolute value with sign determined by serialization code.
For space efficiency, we pack additional information into the prefix byte when possible. Specifically, only the four lower bits of the first byte are used to specify the data type as is sufficient for the number of types in the current model. The upper four bits are reserved for element data for certain types. For example, small integer values are encoded within these four bits. For integer larger than 14, all data bits in the first byte are set to 1 as denotes that the integer value is serialized using additional bytes beyond the prefix byte. A variable-length integer encoding is used for these larger integers.
Strings, arrays, and maps also use this same strategy for encoding their length with small lengths encoded
entirely in the 4-bit data segment of the prefix byte. Strings encode their value as bytes using a specified
Charset
and write the number of bytes before writing the bytes. Arrays record their number of entries
before encoding individual entries in a contiguous range of bytes. Maps are similarly encoded as a series of
alternating key/value elements.
The following diagram depicts the serialization scheme and shows several serialization examples.

Using this serialization scheme, the following serializer is developed for our document data model.
public class DElementSerializer implements Serializer<DElement> {
static final int LOWER_4BITS_SET = 0xF;
private final Charset charset;
private final float estimatedBytesPerChar;
...
private DElementSerializer(Charset charset) {
this.charset = charset;
var encoder = charset.newEncoder();
this.estimatedBytesPerChar = Math.max(encoder.averageBytesPerChar(),
0.8F * encoder.maxBytesPerChar());
}
@Override public void serialize(OutputStream s, DElement x) throws IOException {
serializeInternal(s, Preconditions.checkNotNull(x));
}
@Override public int estimateSerializedSize(DElement x) {
return sizeInternal(x);
}
private void serializeInternal(OutputStream s, DElement x) throws IOException {
var type = x.getType();
switch (type) {
case NULL:
s.write(DElementSerializationType.NULL.getSerializationCode());
break;
case BOOL:
s.write((((DBool) x).isTrue() ? DElementSerializationType.TRUE :
DElementSerializationType.FALSE)
.getSerializationCode());
break;
case INT:
serializeInt(s, (DInt) x);
break;
case DECIMAL:
serializeDecimal(s, (DDecimal) x);
break;
case STRING:
serializeString(s, (DString) x);
break;
case ARRAY:
serializeArray(s, (DArray) x);
break;
case MAP:
serializeMap(s, (DMap) x);
break;
default:
throw new RuntimeException(Strings.lenientFormat("Unhandled type %s for %s", type, x));
}
}
private void serializeInt(OutputStream s, DInt x) throws IOException {
var value = x.getValue();
if (value >= 0) {
serializeUnsignedLong(s, DElementSerializationType.POS_INT, value);
} else {
serializeUnsignedLong(s, DElementSerializationType.NEG_INT, -value);
}
}
private void serializeDecimal(OutputStream s, DDecimal x) throws IOException {
var bytes = x.getValue().toString().getBytes(charset);
serializeUnsignedLong(s, DElementSerializationType.DECIMAL, bytes.length);
s.write(bytes);
}
private void serializeString(OutputStream s, DString x) throws IOException {
var bytes = x.getValue().getBytes(charset);
serializeUnsignedLong(s, DElementSerializationType.STRING, bytes.length);
s.write(bytes);
}
private void serializeArray(OutputStream s, DArray x) throws IOException {
var elements = x.getElements();
var size = elements.size();
serializeUnsignedLong(s, DElementSerializationType.ARRAY, size);
for (int i = 0; i < size; i++) {
serializeInternal(s, elements.get(i));
}
}
private void serializeMap(OutputStream s, DMap x) throws IOException {
var entries = x.getEntries();
serializeUnsignedLong(s, DElementSerializationType.MAP, entries.size());
for (var entry : entries.entrySet()) {
serializeInternal(s, entry.getKey());
serializeInternal(s, entry.getValue());
}
}
private void serializeUnsignedLong(OutputStream s, DElementSerializationType type, long l)
throws IOException {
int lower4 = ((int) l) & LOWER_4BITS_SET;
long left = l >>> 4;
if (left == 0 && lower4 != LOWER_4BITS_SET) {
s.write(type.getSerializationCode() | (lower4 << 4));
} else {
s.write(type.getSerializationCode() | (LOWER_4BITS_SET << 4));
IOUtil.writeVariableLengthUnsignedLong(s, l);
}
}
private int sizeInternal(DElement x) {
var type = x.getType();
switch (type) {
case NULL:
case BOOL:
return 1;
case INT:
return sizeInt((DInt) x);
case DECIMAL:
return 10; // avoid the cost of formatting a decimal and just return this constant
case STRING:
return sizeString((DString) x);
case ARRAY:
return sizeArray((DArray) x);
case MAP:
return sizeMap((DMap) x);
default:
throw new RuntimeException(Strings.lenientFormat("Unhandled type %s for %s", type, x));
}
}
private int sizeInt(DInt x) {
return typeAndLengthSize(Math.abs(x.getValue()));
}
private int sizeString(DString x) {
var l = x.getValue().length();
return typeAndLengthSize(l) + (int) Math.ceil(estimatedBytesPerChar * l);
}
private int sizeArray(DArray x) {
var elements = x.getElements();
var size = elements.size();
var total = typeAndLengthSize(size);
for (int i = 0; i < size; i++) {
total += sizeInternal(elements.get(i));
}
return total;
}
private int sizeMap(DMap x) {
var entries = x.getEntries();
var total = typeAndLengthSize(entries.size());
for (var entry : entries.entrySet()) {
total += sizeInternal(entry.getKey());
total += sizeInternal(entry.getValue());
}
return total;
}
private int typeAndLengthSize(long l) {
return 1 + (l < LOWER_4BITS_SET ? 0 : IOUtil.sizeUnsignedLong(l));
}
}
A deserializer is then developed that reverses this encoding scheme to read documents.
public class DElementDeserializer implements Deserializer<DElement> {
...
private final Charset charset;
@NotNull @Override public DElement deserialize(InputStream s) throws IOException {
return deserializeInternal(s);
}
@Override public void skipDeserialize(InputStream s) throws IOException {
skipInternal(s);
}
private DElement deserializeInternal(InputStream s) throws IOException {
int codeAndExtra = s.read();
if (codeAndExtra < 0) {
throw new EndOfStream();
}
int code = codeAndExtra & LOWER_4BITS_SET;
var type = DElementSerializationType.fromCode(code);
if (type == null) {
throw new RuntimeException("Unknown serialization code " + code);
}
switch (type) {
case NULL:
return DNull.getInstance();
case TRUE:
return DBool.getTrue();
case FALSE:
return DBool.getFalse();
case POS_INT:
return DInt.of(deserializeUnsignedLong(s, codeAndExtra));
case NEG_INT:
return DInt.of(-deserializeUnsignedLong(s, codeAndExtra));
case DECIMAL:
return DDecimal.of(new BigDecimal(deserializeString(s, codeAndExtra)));
case STRING:
return DString.of(deserializeString(s, codeAndExtra));
case ARRAY:
return deserializeArray(s, codeAndExtra);
case MAP:
return deserializeMap(s, codeAndExtra);
default:
throw new RuntimeException("Unhandled type " + type);
}
}
private String deserializeString(InputStream s, int codeAndExtra) throws IOException {
int length = deserializeUnsignedInt(s, codeAndExtra);
var bytes = new byte[length];
IOUtil.readArrayFully(s, bytes);
return new String(bytes, charset);
}
private DArray deserializeArray(InputStream s, int codeAndExtra) throws IOException {
int length = deserializeUnsignedInt(s, codeAndExtra);
var elements = new DElement[length];
for (int i = 0; i < length; i++) {
elements[i] = deserializeInternal(s);
}
return DArray.of(elements);
}
private DMap deserializeMap(InputStream s, int codeAndExtra) throws IOException {
int length = deserializeUnsignedInt(s, codeAndExtra);
var builder = ImmutableMap.<DElement, DElement>builderWithExpectedSize(length);
while (length-- > 0) {
var key = deserializeInternal(s);
var value = deserializeInternal(s);
builder.put(key, value);
}
return DMap.of(builder.build());
}
private long deserializeUnsignedLong(InputStream s, int codeAndExtra) throws IOException {
long value = codeAndExtra >>> 4;
if (value != LOWER_4BITS_SET) {
return value;
}
return IOUtil.readVariableLengthUnsignedLong(s);
}
private int deserializeUnsignedInt(InputStream s, int codeAndExtra) throws IOException {
return Dbf0Util.safeLongToInt(deserializeUnsignedLong(s, codeAndExtra));
}
private void skipInternal(InputStream s) throws IOException {
int codeAndExtra = s.read();
if (codeAndExtra < 0) {
throw new EndOfStream();
}
int code = codeAndExtra & LOWER_4BITS_SET;
var type = DElementSerializationType.fromCode(code);
if (type == null) {
throw new RuntimeException("Unknown serialization code " + code);
}
switch (type) {
case NULL:
case TRUE:
case FALSE:
break;
case POS_INT:
case NEG_INT:
deserializeUnsignedLong(s, codeAndExtra);
break;
case DECIMAL:
case STRING:
IOUtil.skip(s, deserializeUnsignedLong(s, codeAndExtra));
break;
case ARRAY:
skipN(s, deserializeUnsignedInt(s, codeAndExtra));
break;
case MAP:
skipN(s, 2 * deserializeUnsignedInt(s, codeAndExtra));
break;
default:
throw new RuntimeException("Unhandled type " + type);
}
}
private void skipN(InputStream s, int n) throws IOException {
while (n-- > 0) {
skipInternal(s);
}
}
}
Generalizing Storage Engine Components Using Generic Serialization
We now revise the components of our storage engine to use the generic serialization interfaces. For brevity, code is only shown for select classes and only code relevant to the new interfaces are included here. You can follow the links to the full classes in GitHub for details.
Minor modifications are required for the classes that write and read key/value files.
public class KeyValueFileWriter<K, V> implements Closeable {
private final Serializer<K> keySerializer;
private final Serializer<V> valueSerializer;
private transient OutputStream outputStream;
...
public void append(K key, V value) throws IOException {
Preconditions.checkState(outputStream != null, "already closed");
keySerializer.serialize(outputStream, key);
valueSerializer.serialize(outputStream, value);
}
}
public class KeyValueFileReader<K, V> implements Closeable {
private final Deserializer<K> keyDeserializer;
private final Deserializer<V> valueDeserializer;
private transient InputStream inputStream;
private boolean haveReadKey = false;
...
@Nullable public K readKey() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(!haveReadKey);
K key;
try {
key = keyDeserializer.deserialize(inputStream);
} catch (EndOfStream ignored) {
return null;
}
haveReadKey = true;
return key;
}
public V readValue() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(haveReadKey);
V value = valueDeserializer.deserialize(inputStream);
haveReadKey = false;
return value;
}
public void skipValue() throws IOException {
Preconditions.checkState(inputStream != null, "already closed");
Preconditions.checkState(haveReadKey);
valueDeserializer.skipDeserialize(inputStream);
haveReadKey = false;
}
}
Additionally, the indexed, random-access reader is generalized using the generic interfaces.
RandomAccessKeyValueFileReader code
public class RandomAccessKeyValueFileReader<K, V> {
private final TreeMap<K, Long> index;
private final Comparator<K> keyComparator;
private final IoSupplier<KeyValueFileReader<K, V>> readerSupplier;
...
@VisibleForTesting
@Nullable
V getForReader(K key, KeyValueFileReader<K, V> reader) throws IOException {
reader.skipBytes(computeSearchStartIndex(key));
return scanForKey(key, reader);
}
@VisibleForTesting
long computeSearchStartIndex(K key) {
return Optional.ofNullable(index.floorEntry(key)).map(Map.Entry::getValue).orElse(0L);
}
@VisibleForTesting
@Nullable
V scanForKey(K key, KeyValueFileReader<K, V> reader) throws IOException {
while (true) {
var entryKey = reader.readKey();
if (entryKey == null) {
return null;
}
int cmp = keyComparator.compare(entryKey, key);
if (cmp == 0) {
return reader.readValue();
} else if (cmp < 0) {
reader.skipValue();
} else {
return null;
}
}
}
@Nullable
public V get(K key) throws IOException {
try (var reader = readerSupplier.get()) {
return getForReader(key, reader);
}
}
}
Generalizing LSMTree for Arbitrary Key and Value Types
Our final challenge consists of extending our
LSMTee
to use these generic components. Numerous
internal components of the
LSMTree
are generalized and for brevity those changes are not included
here. Only relevant changes for the
LSMTree
class itself are shown and you can visit the GitHub repo
to see all of the changes needed to support generic keys and values.
public class LsmTree<T extends OutputStream, K, V> implements CloseableReadWriteStorage<K, V> {
...
private final SerializationPair<K> keySerialization;
private final SerializationPair<V> valueSerialization;
private final V deleteValue;
private final BaseDeltaFiles<T, K, V> baseDeltaFiles;
private final DeltaWriterCoordinator<T, K, V> coordinator;
private final BaseDeltaMergerCron<T, K, V> mergerCron;
@Override public void put(@NotNull K key, @NotNull V value) throws IOException {
Preconditions.checkState(isUsable());
var writesBlocked = lock.callWithWriteLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
if (pendingWrites.logWriter != null) {
pendingWrites.logWriter.logPut(keySerialization.getSerializer().serializeToBytes(key),
valueSerialization.getSerializer().serializeToBytes(value));
}
pendingWrites.writes.put(key, value);
return checkMergeThreshold();
});
if (writesBlocked) {
waitForWritesToUnblock();
}
}
@Nullable @Override public V get(@NotNull K key) throws IOException {
Preconditions.checkState(isUsable());
// search through the various containers that could contain the key in the appropriate order
var value = lock.callWithReadLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
return pendingWrites.writes.get(key);
});
if (value != null) {
return checkForDeleteValue(value);
}
value = coordinator.searchForKeyInWritesInProgress(key);
if (value != null) {
return checkForDeleteValue(value);
}
if (!baseDeltaFiles.hasInUseBase()) {
return null;
}
value = baseDeltaFiles.searchForKey(key);
return value == null ? null : checkForDeleteValue(value);
}
@Override public boolean delete(@NotNull K key) throws IOException {
Preconditions.checkState(isUsable());
var writesBlocked = lock.callWithWriteLock(() -> {
Preconditions.checkState(pendingWrites != null, "is closed");
if (pendingWrites.logWriter != null) {
pendingWrites.logWriter.logDelete(keySerialization.getSerializer().serializeToBytes(key));
}
pendingWrites.writes.put(key, deleteValue);
return checkMergeThreshold();
});
if (writesBlocked) {
waitForWritesToUnblock();
}
return true;
}
...
}
This completes the development of our new document storage engine.
Unit Testing
Before we begin the exciting work of trying out our new storage engine on a large dataset, we first develop some unit tests for correctness.
Testing Document Serialization
We first develop tests for the correctness of serialization and deserialization by performing these operations in a round trip fashion for a range of different types and values. Each test ensures that the resulting value is equal to the original value. The following code block shows some of these round trip test cases and you can follow the link to see all of the test cases.
DElementSerializationTest code
public class DElementSerializationTest {
private static final Logger LOGGER = Dbf0Util.getLogger(DElementSerializationTest.class);
private final DElementSerializer serializer = DElementSerializer.defaultCharsetInstance();
private final DElementDeserializer deserializer = DElementDeserializer.defaultCharsetInstance();
private void testRoundTrip(DElement original) throws IOException {
testRoundTrip(original, null);
}
private void testRoundTrip(DElement original, @Nullable Integer expectedSize) throws IOException {
var bytes = serializer.serializeToBytes(original);
LOGGER.finer(() -> String.format("%s serializes to %s", original, bytes));
if (expectedSize != null) {
assertThat(bytes.getArray()).hasSize(expectedSize);
}
var stream = new ByteArrayInputStream(bytes.getArray());
var result = deserializer.deserialize(stream);
assertThat(result).isEqualTo(original);
assertThat(stream.available()).isEqualTo(0);
stream.reset();
deserializer.skipDeserialize(stream);
assertThat(stream.available()).isEqualTo(0);
}
@Test public void testNull() throws IOException {
testRoundTrip(DNull.getInstance(), 1);
}
@Test public void testTrue() throws IOException {
testRoundTrip(DBool.getTrue(), 1);
}
@Test public void testFalse() throws IOException {
testRoundTrip(DBool.getFalse(), 1);
}
@Test public void testIntZero() throws IOException {
testRoundTrip(DInt.of(0L), 1);
}
@Test public void testIntSmall() throws IOException {
testRoundTrip(DInt.of(3L), 1);
}
@Test public void testIntMid() throws IOException {
testRoundTrip(DInt.of(547L));
}
@Test public void testIntLarge() throws IOException {
testRoundTrip(DInt.of(35695382269897L));
}
@Test public void testStringEmpty() throws IOException {
testRoundTrip(DString.of(""), 1);
}
@Test public void testStringSingle() throws IOException {
testRoundTrip(DString.of("a"), 2);
}
@Test public void testStringMid() throws IOException {
testRoundTrip(DString.of("hI5liFv5Nh2HvPJH"));
}
@Test public void testDecimalZero() throws IOException {
testRoundTrip(DDecimal.of(new BigDecimal(0L)));
}
@Test public void testDecimalPositive() throws IOException {
testRoundTrip(DDecimal.of(new BigDecimal("99.34901097702962")));
}
@Test public void testArrayEmpty() throws IOException {
testRoundTrip(DArray.of(), 1);
}
@Test public void testArraySingle() throws IOException {
testRoundTrip(DArray.of(DInt.of(1)), 2);
}
@Test public void testMapEmpty() throws IOException {
testRoundTrip(DMap.of(), 1);
}
@Test public void testMapSingle() throws IOException {
testRoundTrip(DMap.of(DInt.of(1), DInt.of(2)), 3);
}
...
}
Testing LSMTree Document Storage
We also develop a unit test to verify that our revised LSMTree can correctly store document-based keys and
values. We reuse our
ReadWriteStorageTester
with key and value suppliers that provide random
DString
instances.
public class LsmTreeTest {
@Test public void testDocumentStoreSingleThreaded() throws IOException {
var operations = new MemoryFileDirectoryOperations();
var tree = LsmTree.<MemoryFileOperations.MemoryOutputStream>builderForDocuments()
.withBaseDeltaFiles(operations)
.withPendingWritesDeltaThreshold(100)
.withScheduledThreadPool(2)
.withIndexRate(10)
.withMaxInFlightWriteJobs(10)
.withMaxDeltaReadPercentage(0.5)
.withMergeCronFrequency(Duration.ofMillis(100))
.build();
tree.initialize();
var random = RandomSeed.CAFE.random();
var count = new AtomicInteger(0);
var tester = ReadWriteStorageTester
.builder(tree)
.knownKeySupplier(() -> randomDString(random, 4))
.unknownKeySupplier(() -> randomDString(random, 5))
.valueSupplier(() -> randomDString(random, random.nextInt(2000)))
.random(random)
.debug(false)
.checkDeleteReturnValue(false)
.checkSize(false).iterationCallback((ignored) -> {
if (count.incrementAndGet() % 1000 == 0) {
LOGGER.info("iteration " + count.get() + " size " +
Dbf0Util.formatBytes(getDirectorySize(operations)));
}
}).build();
tester.testPutDeleteGet(20 * 1000, PutDeleteGet.BALANCED, KnownKeyRate.MID);
}
...
}
Benchmarking
With our document store developed and tested, we can now benchmark its performance. To this end, we use a dataset of 147 million Reddit comments for the month of August 2019 provided by pushshift.io. The raw, uncompressed data consists of 185.8 GB of JSON entries.
Benchmarking harnesses are developed for three different scenarios to quantify the performance of the new storage engine:
- Time to load the full dataset
-
Sustained rate of
GETrequests -
Sustained rate of updates, each update consisting of a
GETand subsequentPUTrequest
In each benchmarking scenario, we vary parameters such as number of partitions and the level of multi-threaded concurrency across different trials to explore how these parameters affect performance.
As in previous projects, benchmarking is performed using EC2 instances on AWS to provide a standard environment.
Whereas we previously used
i3.2xlarge
storage-optimized instances, we now elect to use
c5d.9xlarge
instances. These instances still have high performance NVMe drives as local storage. The
c5
class provides a better ratio of compute-to-storage with the selected instances having 36 vCPUs,
whereas the previously used
i3
class only had 8. Preliminary benchmarking found that the serialization
and deserialization operations of the document store could easily saturate all 8 vCPUs without stressing IO
performance. The higher core count
c5
instances allow for scaling out to higher concurrency levels
before becoming compute-limited. Details of the instances and configuration are as follows.
| Attribute | Value |
|---|---|
| Instance Type | c5d.9xlarge |
| Instance Storage | 900 GB NVMe SSD |
| Provisioned Input/Output Ops/Second (IOPs) | 170,000 |
| vCPUs | 36 |
| RAM | 72 GiB |
| OS Image | Ubuntu 18.04 LTS - Bionic |
| Kernel | Linux version 4.15.0-1065-aws |
| JRE | OpenJDK 64-Bit Server VM version 11.0.6 |
Benchmarking Loading 147 Million Reddit Comments
We first develop a simple program for loading the JSON entries from a single large file into our data store. It
is anticipated that bottlenecks could be developed in either reading entries from disk or in parsing the entries
for inserting into our document store. Since the backing
LSMTree
batches writes together for
persisting in large batches, individual writes are quite cheap.
Multi-threaded concurrency is developed for each of the two identified bottlenecks. There is a group of reading
threads that read from JSON data file, each starting from a different positions to allow for parallel input IO. A
queue containing file lines is populated by the reading threads. A separate group of writing threads pulls
individual lines, parses the JSON line to a
DMap
instance, and inserts individual comments into the
document store using the
id
attribute of each comment as the key. The number of reading and writing
threads can be independently varied to try out different combinations. Additionally, we use a partitioned LSMTree
as the backing store and vary the number of partitions in benchmarking trials.
The loading program runs until all entries have been inserted into the document store. Throughout loading, the program tracks the number of total entries written and the total size of all files within the document store. These metrics are reported at an interval of roughly one second and each report includes the current nanosecond-scale resolution system time for tracking performance over time.
The main components of this benchmarking program are shown as follow and the full code can be found at the linked source code in GitHub.
public class BenchmarkLoadDocuments {
private static final Logger LOGGER = Dbf0Util.getLogger(BenchmarkLoadDocuments.class);
public static void main(String[] args) throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINE, true);
var argsItr = Arrays.asList(args).iterator();
var readFile = new File(argsItr.next());
var directory = new File(argsItr.next());
var pendingWritesMergeThreshold = Integer.parseInt(argsItr.next());
var indexRate = Integer.parseInt(argsItr.next());
var partitions = Integer.parseInt(argsItr.next());
var readingThreadCount = Integer.parseInt(argsItr.next());
var writingThreadsCount = Integer.parseInt(argsItr.next());
Preconditions.checkState(!argsItr.hasNext());
var base = new FileDirectoryOperationsImpl(directory);
base.mkdirs();
base.clear();
var executor = Executors.newScheduledThreadPool(30);
var store = new ReadWriteStorageWithBackgroundTasks<>(
createStore(pendingWritesMergeThreshold, indexRate, partitions, base, executor),
executor);
store.initialize();
var errors = new AtomicInteger(0);
var readDone = new AtomicBoolean(false);
var writes = new AtomicLong(0);
var queue = new LinkedBlockingQueue<String>(100);
var startTime = System.nanoTime();
var reportFuture = executor.scheduleWithFixedDelay(
() -> report(errors, writes, directory, startTime),
0, 1, TimeUnit.SECONDS);
var readOffset = readFile.length() / readingThreadCount;
var readThreads = IntStream.range(0, readingThreadCount)
.mapToObj(i -> new Thread(() -> readQueue(errors, readFile, i * readOffset,
(i + 1) * readOffset, queue), "read-" + i))
.collect(Collectors.toList());
readThreads.forEach(Thread::start);
var writeThreads = IntStream.range(0, writingThreadsCount)
.mapToObj(i -> new Thread(() -> write(errors, readDone, writes, queue, store), "write-" + i))
.collect(Collectors.toList());
writeThreads.forEach(Thread::start);
var threads = new ArrayList<>(readThreads);
threads.addAll(writeThreads);
while (errors.get() == 0 && readThreads.stream().anyMatch(Thread::isAlive)) {
for (Thread readThread : readThreads) {
if (readThread.isAlive()) {
readThread.join(200L);
}
}
}
readDone.set(true);
if (errors.get() != 0) {
for (Thread thread : threads) {
if (thread.isAlive()) {
thread.interrupt();
}
}
}
for (Thread thread : threads) {
thread.join();
}
reportFuture.cancel(false);
store.close();
report(errors, writes, directory, startTime);
System.exit(errors.get() == 0 ? 0 : 1);
}
@NotNull static HashPartitionedReadWriteStorage<DElement, DElement>
createStore(int pendingWritesMergeThreshold, int indexRate, int partitions,
FileDirectoryOperationsImpl base, ScheduledExecutorService executor) throws IOException {
return HashPartitionedReadWriteStorage.create(partitions,
partition -> createLsmTree(base.subDirectory(String.valueOf(partition)),
pendingWritesMergeThreshold, indexRate, executor));
}
@NotNull static LsmTree<FileOutputStream, DElement, DElement>
createLsmTree(FileDirectoryOperationsImpl directoryOperations,
int pendingWritesMergeThreshold, int indexRate,
ScheduledExecutorService executorService) throws IOException {
directoryOperations.mkdirs();
return LsmTree.<FileOutputStream>builderForDocuments()
.withBaseDeltaFiles(directoryOperations)
.withPendingWritesDeltaThreshold(pendingWritesMergeThreshold)
.withScheduledExecutorService(executorService)
.withIndexRate(indexRate)
.withMaxInFlightWriteJobs(3)
.withMaxDeltaReadPercentage(0.75)
.withMergeCronFrequency(Duration.ofSeconds(1))
.build();
}
private static void readQueue(AtomicInteger errors, File file, long start, long end, BlockingQueue<String> queue) {
try (var channel = FileChannel.open(file.toPath())) {
var result = channel.position(start);
Preconditions.checkState(result == channel);
var reader = new BufferedReader(Channels.newReader(channel, StandardCharsets.UTF_8));
if (start != 0) {
reader.readLine();
}
int i = 0;
while (errors.get() == 0) {
if (i++ % 10 == 0 && channel.position() > end) {
break;
}
var line = reader.readLine();
if (line == null) {
break;
}
queue.put(line);
}
} catch (InterruptedException ignored) {
} catch (Exception e) {
errors.incrementAndGet();
LOGGER.log(Level.SEVERE, e, () -> "Error in reading input");
}
}
private static void write(AtomicInteger errors, AtomicBoolean readDone, AtomicLong writes,
BlockingQueue<String> queue,
ReadWriteStorage<DElement, DElement> store) {
var adapter = DElementTypeAdapter.getInstance();
var idKey = DString.of("id");
try {
while (errors.get() == 0) {
var line = queue.poll(100, TimeUnit.MILLISECONDS);
if (line == null) {
if (readDone.get()) {
break;
}
continue;
}
var element = (DMap) adapter.fromJson(line);
var id = (DString) element.getEntries().get(idKey);
store.put(id, element);
writes.incrementAndGet();
}
} catch (InterruptedException ignored) {
} catch (Exception e) {
errors.incrementAndGet();
LOGGER.log(Level.SEVERE, e, () -> "Error in writing");
}
}
...
}
While the benchmark completes when all data has been loaded, it is possible, in fact likely, that the backing
LSMTree
instances are still actively merging delta files with the base. The program closes the data
store, which aborts this process. As we'll be reusing those data stores in subsequent benchmarks, it is useful to
add an additional step that completes the merging of all delta files with the base to provide a standard starting
point. A simple program
MergedPartitionedLsmTreeDeltas
is used to accomplish this merging.
Benchmarking GET Documents
Next, we benchmark the performance of the document store in fetching individual documents through
GET
operations. To provide a set of known keys, the program
SampleKeys
is ran and it samples roughly 100 million comment ids from the document store files for use in this benchmark.
The
GET
benchmarking harness simply runs for a fixed duration of time, in all reported results 3
minutes, and counts the number of
GET
operations performed throughout. Again, results are reported
roughly once a second and each result includes the nanosecond-scale system time. We explore the impact of
concurrent performance by varying the number of threads concurrently performing
GET
operations across
different benchmarking trials. Additionally, benchmarks are ran using documents stores with different number of
partitions to quantify how this impacts performance.
High-level components of this benchmarking harness are shown as follows.
public class BenchmarkGetDocuments {
private static final Logger LOGGER = Dbf0Util.getLogger(BenchmarkGetDocuments.class);
public static void main(String[] args) throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINE, true);
var argsItr = Arrays.asList(args).iterator();
var directory = new File(argsItr.next());
var keysPath = new File(argsItr.next());
var partitions = Integer.parseInt(argsItr.next());
var indexRate = Integer.parseInt(argsItr.next());
var coreThreads = Integer.parseInt(argsItr.next());
var getThreads = Integer.parseInt(argsItr.next());
var duration = Duration.parse(argsItr.next());
Preconditions.checkState(!argsItr.hasNext());
Preconditions.checkState(directory.isDirectory());
Preconditions.checkState(keysPath.isFile());
var executor = Executors.newScheduledThreadPool(coreThreads);
try {
var keys = loadKeys(keysPath);
runGets(directory, partitions, indexRate, getThreads, duration, keys, executor);
} finally {
executor.shutdown();
executor.awaitTermination(10, TimeUnit.SECONDS);
}
}
private static void runGets(File directory, int partitions, int indexRate, int getThreads,
Duration duration, List<DString> keys,
ScheduledExecutorService executor) throws Exception {
try (var store = BenchmarkLoadDocuments.createStore(100000, indexRate, partitions,
new FileDirectoryOperationsImpl(directory), executor)) {
store.initialize();
var error = new AtomicBoolean(false);
var done = new AtomicBoolean(false);
var gets = new AtomicLong(0);
var threads = IntStream.range(0, getThreads).mapToObj(i -> new Thread(() -> getThread(error, done, gets, keys, store)))
.collect(Collectors.toList());
var startTime = System.nanoTime();
var doneFuture = executor.schedule(() -> done.set(true), duration.toMillis(), TimeUnit.MILLISECONDS);
var reportFuture = executor.scheduleWithFixedDelay(() -> report(error, gets, directory, startTime),
0, 1, TimeUnit.SECONDS);
threads.forEach(Thread::start);
while (!error.get() && threads.stream().anyMatch(Thread::isAlive)) {
for (var thread : threads) {
thread.join(200L);
}
}
if (!doneFuture.isDone()) {
doneFuture.cancel(false);
}
reportFuture.cancel(false);
for (Thread thread : threads) {
thread.join();
}
report(error, gets, directory, startTime);
}
}
private static void getThread(AtomicBoolean error, AtomicBoolean done, AtomicLong gets,
List<DString> keys,
ReadWriteStorage<DElement, DElement> store) {
try {
var random = new Random();
while (!error.get() && !done.get()) {
var key = keys.get(random.nextInt(keys.size()));
var value = store.get(key);
if (value == null) {
throw new RuntimeException("No value for " + key);
}
gets.getAndIncrement();
}
} catch (Exception e) {
LOGGER.log(Level.SEVERE, "Error in get", e);
error.set(true);
}
}
...
}
Benchmarking Update (GET+PUT) Documents
Lastly, we benchmark performance for updates, each consisting of a
GET, modification of the
document, and a subsequent
PUT
to store the updated value. For modification, the program simply
increments the score of the fetched comment. The same set of sampled keys created for
GET
benchmarking
are reused in these trials. Similar to the
GET
benchmark, we vary the number of threads performing
concurrent operations and also use data stores with different partition counts in different trials.
A unique challenge of the update scenario is that
PUT
operations modify the underlying data store.
Hence, a data store cannot be reused after one trial since it is in different state relative to when the trial
began. A rather simple solution is to create a lightweight copy of the original loaded and merged data store using
symbolic links of the individual files that compose the document store. In an update benchmarking run, new delta
files are written, they are merged with the base, and the now redundant delta and base files are deleted. Since the
original files are symbolically linked to create the trial data store, the deletes only remove the links and leave
the underlying files for use in subsequent trials.
High-level components of this benchmarking harness are shown as follows.
public class BenchmarkUpdateDocuments {
private static final Logger LOGGER = Dbf0Util.getLogger(BenchmarkUpdateDocuments.class);
public static void main(String[] args) throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINE, true);
var argsItr = Arrays.asList(args).iterator();
var directory = new File(argsItr.next());
var keysPath = new File(argsItr.next());
var partitions = Integer.parseInt(argsItr.next());
var pendingWritesMergeThreshold = Integer.parseInt(argsItr.next());
var indexRate = Integer.parseInt(argsItr.next());
var coreThreads = Integer.parseInt(argsItr.next());
var updateThreads = Integer.parseInt(argsItr.next());
var duration = Duration.parse(argsItr.next());
Preconditions.checkState(!argsItr.hasNext());
Preconditions.checkState(directory.isDirectory());
Preconditions.checkState(keysPath.isFile());
var executor = Executors.newScheduledThreadPool(coreThreads);
try {
ArrayList<DString> keys = loadKeys(keysPath);
runUpdates(directory, pendingWritesMergeThreshold, partitions, indexRate, updateThreads,
duration, keys, executor);
} finally {
executor.shutdown();
executor.awaitTermination(10, TimeUnit.SECONDS);
}
}
private static void runUpdates(File directory, int pendingWritesMergeThreshold,
int partitions, int indexRate,
int updateThreads, Duration duration, List<DString> keys,
ScheduledExecutorService executor) throws Exception {
try (var store = BenchmarkLoadDocuments.createStore(
pendingWritesMergeThreshold, indexRate, partitions,
new FileDirectoryOperationsImpl(directory), executor)) {
store.initialize();
var error = new AtomicBoolean(false);
var done = new AtomicBoolean(false);
var updates = new AtomicLong(0);
var threads = IntStream.range(0, updateThreads)
.mapToObj(i -> new Thread(() -> updateThread(error, done, updates, keys, store)))
.collect(Collectors.toList());
var startTime = System.nanoTime();
var doneFuture = executor.schedule(() -> done.set(true), duration.toMillis(), TimeUnit.MILLISECONDS);
var reportFuture = executor.scheduleWithFixedDelay(() -> report(error, updates, directory, startTime),
0, 1, TimeUnit.SECONDS);
threads.forEach(Thread::start);
while (!error.get() && threads.stream().anyMatch(Thread::isAlive)) {
for (var thread : threads) {
thread.join(200L);
}
}
if (!doneFuture.isDone()) {
doneFuture.cancel(false);
}
reportFuture.cancel(false);
for (Thread thread : threads) {
thread.join();
}
report(error, updates, directory, startTime);
}
}
private static void updateThread(AtomicBoolean error, AtomicBoolean done, AtomicLong updates,
List<DString> keys, ReadWriteStorage<DElement, DElement> store) {
var scoreKey = DString.of("score");
try {
var random = new Random();
while (!error.get() && !done.get()) {
var key = keys.get(random.nextInt(keys.size()));
var value = store.get(key);
if (value == null) {
throw new RuntimeException("No value for " + key);
}
var map = (DMap) value;
var hash = new HashMap<>(map.getEntries());
var score = (DInt) hash.get(scoreKey);
Preconditions.checkNotNull(score);
hash.put(scoreKey, DInt.of(score.getValue() + 1));
var updated = DMap.of(hash);
store.put(key, updated);
updates.getAndIncrement();
}
} catch (Exception e) {
LOGGER.log(Level.SEVERE, "Error in update", e);
error.set(true);
}
}
...
}
Analysis of Benchmarking Results
Computing Stats for the 147 Million Reddit Comments in JSON
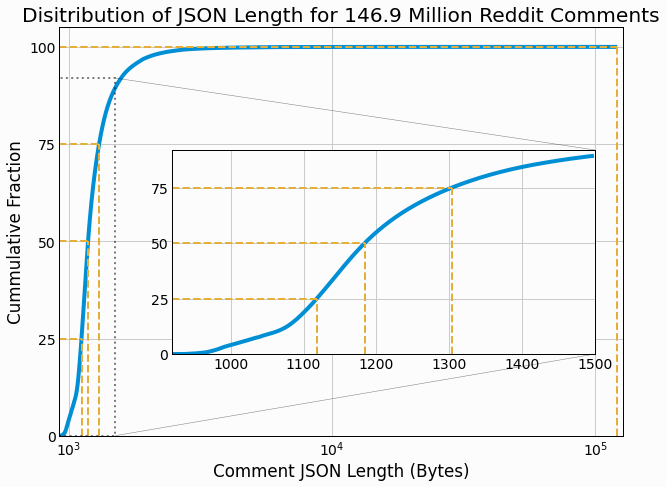
We first compute some simple properties of the comment dataset to guide subsequent analysis. The total size of the input JSON data is 185.86 GB, which implies a mean JSON-serialized length of 1265.6 bytes. Additionally, the distribution of entry sizes are computed and select quantiles are as follows.
| Percentile % | 0.0 | 25.0 | 50.0 | 75.0 | 90.0 | 95.0 | 99.0 | 99.9 | 100.0 |
|---|---|---|---|---|---|---|---|---|---|
| Length Bytes | 919 | 1,119 | 1,184 | 1,304 | 1,516 | 1,742 | 2,506 | 5,106 | 121,186 |
The overall cumulative distribution is plotted and a long tail is found with a small number of comments having significantly long lengths than the median.
Analysis of Loading
Loading benchmarking trials are performed for various thread count combinations as well as different numbers of
partitions. Loading is found to take between roughly 15 and 33 minutes across the different trials. From the total
duration of loading, the loading rate of
PUT
operations per a second is computed and shown in the
following figure with partition count highlighted using different color bars.
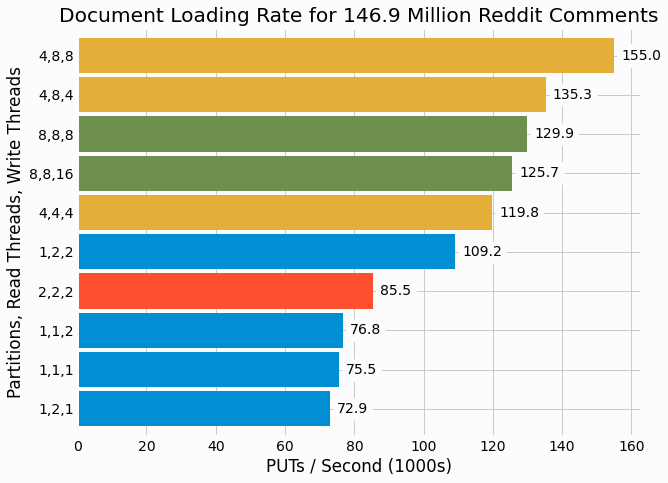
As expected, a higher level of concurrency, consisting of more reading and writing threads, generally leads to higher performance. Interestingly, optimal performance is found with 4 partitions and further increasing to 8 results in degraded performance. In previous benchmarking of a partitioned store, we generally found increasing partition count to increase performance. We'll consider why this may be the case for the current benchmarking within the discussion section of this project.
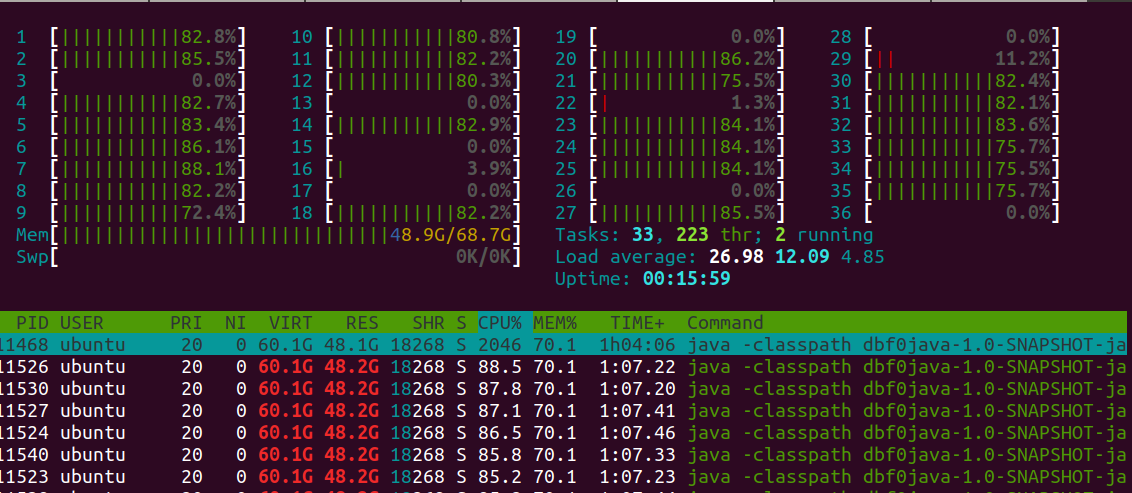
To verify that the highest performing scenarios aren't compute-bound, the
htop
command is used to
check process utilization during a re-run of the 4,8,8 benchmarking trial. Load level is found to be sufficiently
below the maximum possible value of 36 as shows processors aren't oversubscribed.
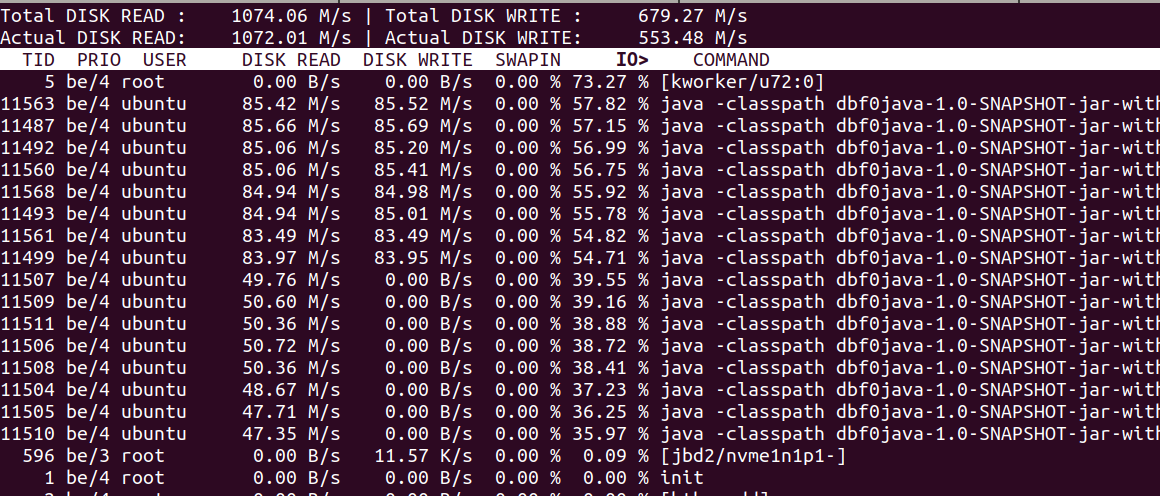
Additionally,
iotop
commands shows substantial IO being performed for both disk reading and
writing.
We also analyze the time-dependent performance of these loading trials. The following figures shows the
PUT
rate at each reported one second interval for different partition counts, each at the optimal
thread count. Individual data points are shown as partially transparent circles and cubic splines show a smoothing
of the results as plotted lines.
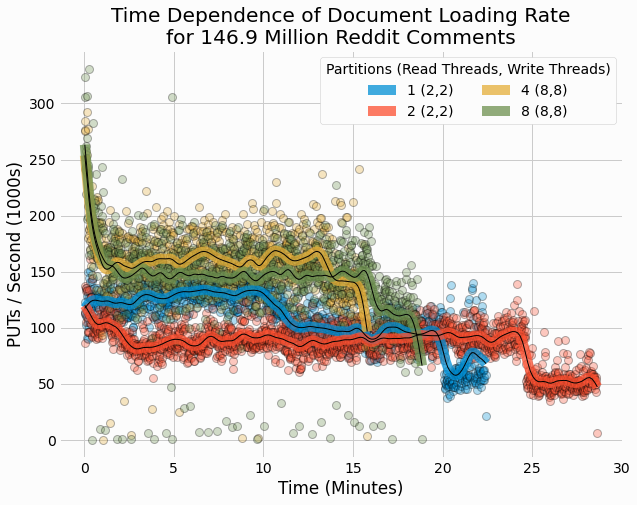
We see that performance generally starts out relatively high and then decreases to a roughly fixed rate for a significant period of time. From there, performance may further decrease near the end of the benchmarking run. There are substantial variations in performance without an obvious pattern to this behavior. The discussion section of this project will propose explanations of this time-dependent behavior in loading.
Lastly, we plot the total size of the data store files for each trial over time.
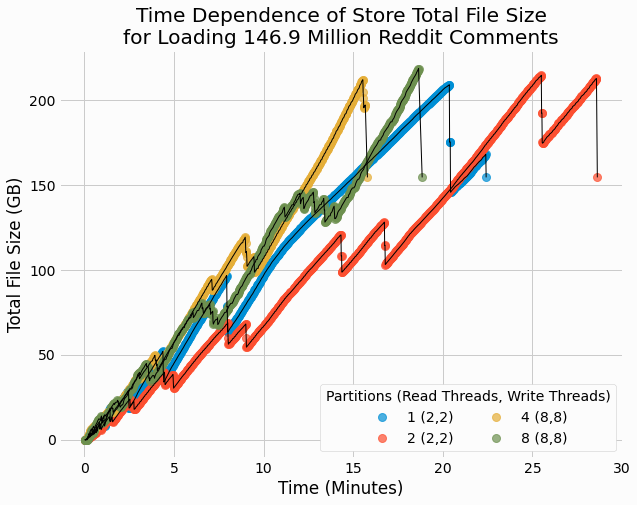
These results are similar to the earlier results for size of partitioned store over time, with size generally increasing and occasional large sudden drops. Such drops were previously attributed to the end of delta/base merging, after which the old delta and base files are deleted. It also noteworthy that all benchmark trials end with a total data size of roughly 150 GB, which is a moderate decrease from the 186 GB of the input JSON data. Hence, the document serialization format does provide some benefit over simply storing entries in JSON format.
Analysis of GET
Next, we analyze the results of the
GET
benchmarking trials. Results are collected for partition
counts of both 4 and 8. For each partition count, we vary the number of threads performing concurrent operations
from 1 to 96 across different trials. Using the total number of
GET
operations performed in each 3
minute trial, the average
GET
rate is calculated. The following figure shows how performance
quantified by this metric scales with thread count for each partition count.
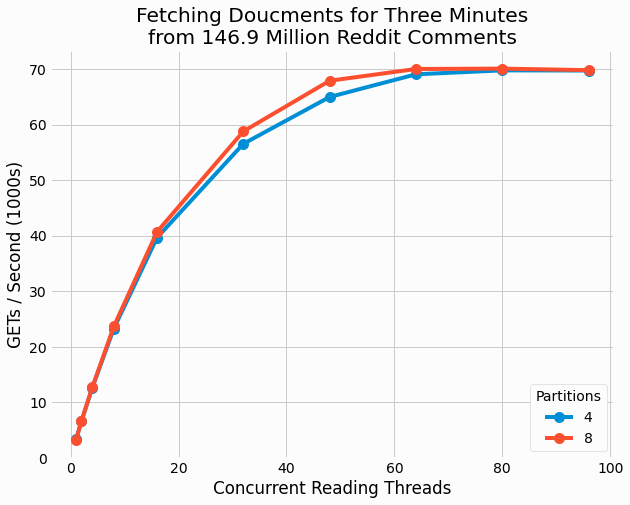
The results for the two partition counts are near identical as that shows the number of partitions doesn't impact performance. This makes sense as only read operations are performed in this benchmarking and therefore there is no lock contention between threads as could be ameliorated with higher partition counts. The total volume of data addressed by the store in unaffected by partition count and it makes little difference how data is split into files for the number of files considered here.
It is interesting that performance continues to scale all the way up to 64 threads, even though the machine only
has 36 vCPUs. This suggests that
GET
operations are not heavily compute-bound despite the need to
deserialize entries from disk. Instead, sufficient disk wait time is commonly encountered in individual
GET
requests so as to allow the thread to be swapped off of a core so as to allow another thread to
run. Beyond 64 threads, performance largely plateaus, but we don't observe degraded performance as would suggest an
over subscription of the cores.
We also plot the time-dependent performance of
GET
operations for both partition counts with 64
threads.
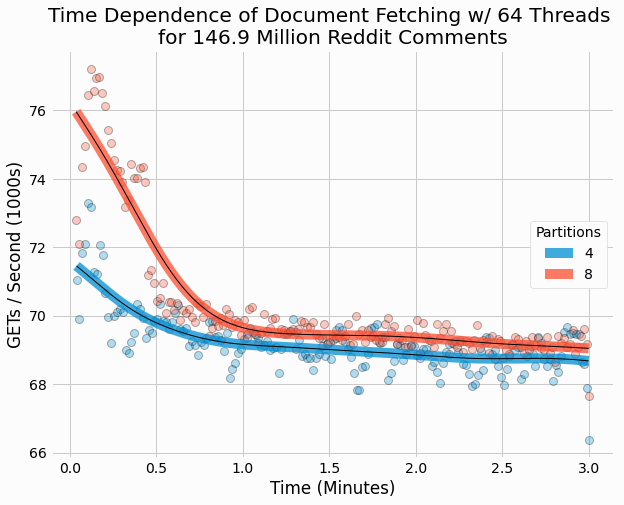
These results are largely constant over time, with a slight peak at the beginning and a small decrease over time.
Analysis of Update (GET+PUT)
Lastly, we analyze the performance of the update benchmarking. Similar to the
GET
analysis, we
start by calculating the average rate of updates per a second for each trial over its 3 minute duration. The
following figure shows how this scales with number of threads performing concurrent updates for three different
partition counts.
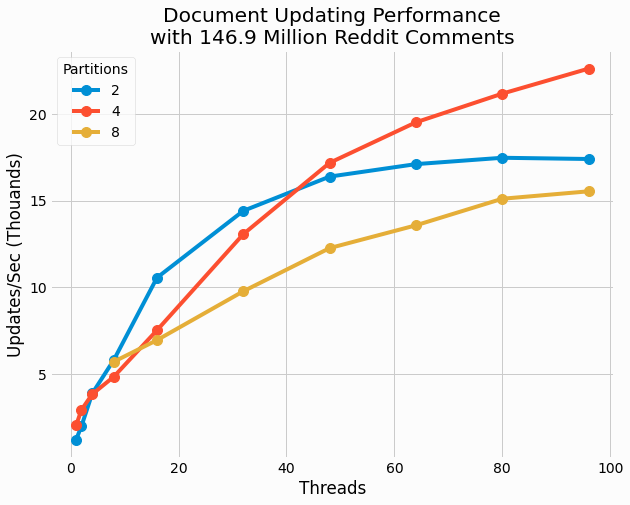
These results are quite interesting in that no single partition count outperforms the others for all thread counts. For 32 and fewer threads, the 2 partition cases outperform the other cases. Yet for higher thread count, 4 partitions results in optimal performance. 8 partitions generally under performs relative to the two other cases.
Further, for 4 partitions, performance continues to scale with increasing thread count all the way to the maximum value of 96. This suggests these update operations are not compute bound, but instead significant IO delay is encountered in individual threads as facilitates them being moved off cores for another thread to run.
It is also noteworthy that the highest observed performance is 22.6k updates/sec, which is less than half the
highest
GET
performance of 70.1k gets/sec. This result shows that the combination of
GET
and
PUT
operations are significantly more expensive than
GET
operations. This may be
attributed to the creation of delta files as must be searched in subsequent
GET
operations before
searching the base.
Next, we plot the time-dependence of update performance for several different thread count trials, all with 4 partitions.
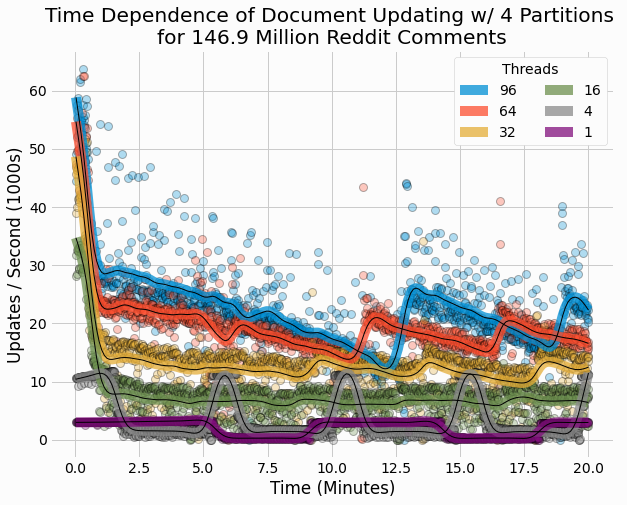
These results also show similarities to earlier results for performance over time of a partitioned store in that there is some periodic behavior. The period behavior of earlier performance results was attributed to the competition between writing and reading IO operations, with reading performance enhanced during periods of times where writes are collected in memory for subsequent batch writing. While writes are collected in memory, deltas aren't being written and read performance improves. The current results for thread count of 4 show the strongest periodic performance. For other thread counts, this is less apparent, although we certainly see significant jumps in performance as could also be attributed to lulls in delta writing.
We also plot the time-dependence of total file size for these 4 partition count results.
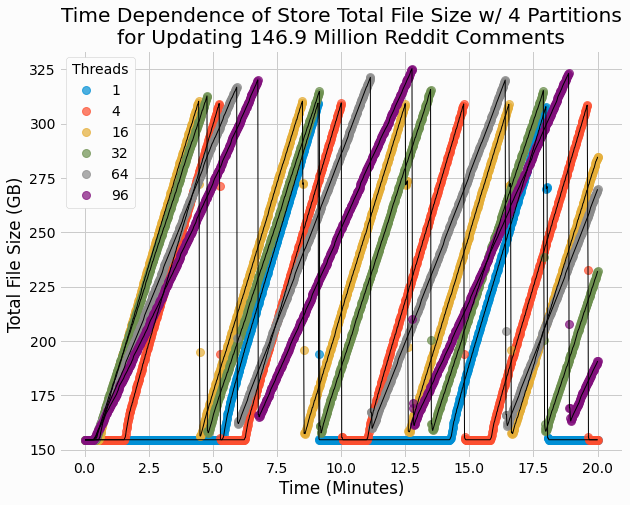
Here we can see steep increases in file sizes, followed by sudden drops where the store size roughly halves. This behavior can be attributed to base/delta merging, during which a new base is written to a temporary file. The new base should be roughly the same size as the original since entries are neither added nor deleted in these benchmark. Once the new base file has been prepared and set as the current base, the old file is deleted as corresponds to the sudden drop off in total file size.
Plotting the time-dependent size for different partition counts highlights some important differences of store behavior using a different number of partitions.
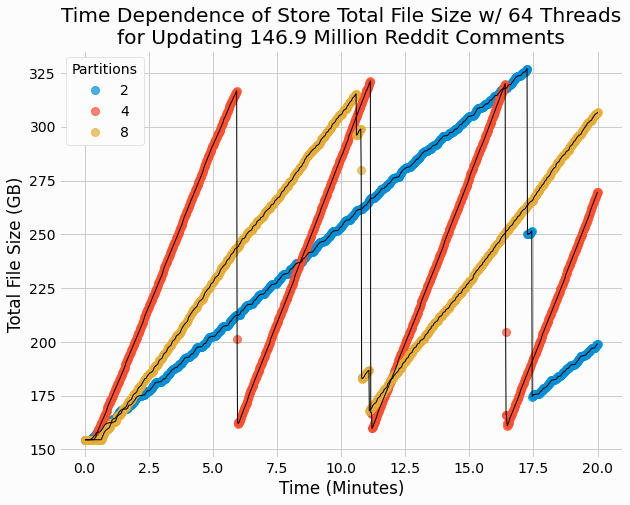
We see that higher partition counts results in more frequent periods as corresponds to faster merging. Since individual partitions can be merged in parallel, using a higher partition count results in less data to merge for each individual partition. Since each partition is merged in a serial single threaded work flow, the smaller partition counts are easily bottlenecked on reading a single large file. Whereas the higher partition counts allow multiple threads to concurrently process multiple files in parallel.
Discussion and Next Steps
Storing documents is a significant milestone in our journey through database development. With semi-structured
values, we'll be able to develop support for secondary indexes and partial
GET
and
SET
operations, which are valuable features for a storage engine. Additionally, the support for semi-structured data
alleviates applications of having to define custom serialization formats for their data as would be required for a
simple byte array key/value store. Many application might simply use JSON encoding and we've found that our custom
serialization format is more space efficient.
While present benchmarking results for our new document storage engine show some similarities to
previous results for performance of a partitioned
store, including periodic performance over time, we also discover some new behavior. Of particular interest is
that the optimal
PUT
performance is observed with 4 partitions and further increasing partitions
degrades performance. In contrast, previous results for a byte array key/value store show performance increasing
with partition count up to the maximum investigated value of 16. This suggests some overhead with adding partitions
that is unique to document stores. Its not obvious where this overhead comes from, although it may be attributed to
the background sorting, serialization, and writing of delta files. This step is more compute-intensive with
document stores relative to simple byte array stores and increasing partition count results in more potential
concurrent runs of these jobs.
The benchmarking results for
PUT
trials also show some degradation over time. We haven't previously
explored the time-dependent behavior of
PUT
heavy workloads so its possible that these results aren't
unique to a document store. The degradation can likely be explained by increasingly expensive delta/base merging as
the size of the store increases over time. Larger base files result in more IO consumed in merging and this
competes with IO used in reading the input JSON data.
Another interesting result consists of large variations in performance for both the loading benchmarks and the
updating one. These variation differ from the fluctuating periodic behavior previously seen for the byte array
key/value store as attributed to IO competition between
PUT
/
GET
/
DELETE
operations and delta writing and merging. Instead, the newly observed variations show highly random behavior over
short periods of time. Larger variation is seen with higher thread count, particularly so when going over the vCPU
count, and this suggests some CPU contention. While overall performance doesn't degrade, and generally increases
with higher thread count, the constant swapping of threads off of cores might explain these variations. This could
also be connected to variations in disk performance, with some IO operations blocking such that the thread is
swapped off core before its allocated time is complete.
With support for document storage developed, we can start developing more sophisticated database features. Of
particularly interest are
secondary
indexes
as allows application to efficiently look values using attributes other than the primary key. Secondary
indexes have many similarities to a primary index, but one key difference is the secondary key is not necessarily
unique and therefore multiple values can be associated with a single secondary key. For an example from the Reddit
comment data, imagine if the
subreddit
attribute was used as a secondary key. Popular subreddits could
easily be associated with millions of comments and the secondary index would have to reflect that and allow a user
to access all of these values. Check out our next project in the series,
Multivalue LSMTree Storage Engine
to learn how we can store an
arbitrarily large number of values associated with a single key for the storage of secondary indexes.