
Basic In-Memory Key/Value Store
Develop our first database, an in-memory key/value store, and experiment with different mechanisms for handling concurrent data writing and reading.
Introduction
In this project, we'll implement a basic key/value store that holds all of its data in memory. For simplicity, our keys and values will consist of short byte arrays (i.e., binary data). We'll build off our work in the Simple Socket Server and Client project to implement a server and a client that are each multi-threaded. Since this will allow multiple concurrent reads and/or writes, we'll explore different approaches to applying locking to prevent race conditions. Lastly, we'll benchmark our key/value store in a few different scenarios; e.g., ready heavy vs. write heavy workloads.
You can find the full code for this project within the DBFromZero Java repository on github to read, modify and run yourself.
Working with Byte Arrays
Since we'll working a lot with byte arrays in this project, it helps to first develop a byte array wrapper that
provides some convenience methods. This includes the methods
hashCode()
and
equals(Object), which allow us to use this wrapper as a key in hash code based data structures such
as
HashMap. Naked arrays do not implement these two methods and therefore cannot be used in such
cases.
public class ByteArrayWrapper {
private final byte[] array;
public ByteArrayWrapper(byte[] array) {
this.array = Preconditions.checkNotNull(array);
}
public byte[] getArray() {
return array;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
ByteArrayWrapper that = (ByteArrayWrapper) o;
return Arrays.equals(array, that.array);
}
@Override
public int hashCode() {
return Arrays.hashCode(array);
}
@Override
public String toString() {
return Hex.encodeHexString(array);
}
public ByteArrayWrapper copy() {
return new ByteArrayWrapper(Arrays.copyOf(array, array.length));
}
}
Next, we need to decide how to write and read variable-length byte arrays within client/server communication. A
simple solution, is to prefix each array with a single byte that specifies the length of the array so that the
reader knows exactly how many bytes to read. Methods for reading and writing these length-prefixed arrays are
developed in the
PrefixIo
class. This class also provides single
byte
constants for
denoting the different types of messages that can be sent between the client and server.
class PrefixIo {
// prefixes to identify different types of messages
// client requests
static final byte SET = (byte) 's';
static final byte GET = (byte) 'g';
// server responses
static final byte FOUND = (byte) 'f';
static final byte NOT_FOUND = (byte) 'n';
static ByteArrayWrapper readPrefixLengthBytes(InputStream s) throws IOException {
var length = s.read();
if (length < 0) {
throw new RuntimeException("Empty input stream");
}
var array = new byte[length];
Dbf0Util.readArrayFully(s, array);
return new ByteArrayWrapper(array);
}
static void writePrefixLengthBytes(OutputStream s, ByteArrayWrapper w) throws IOException {
var array = w.getArray();
if (array.length > Byte.MAX_VALUE) {
throw new RuntimeException("Byte array length " + array.length + " is too long");
}
s.write(array.length);
s.write(array);
}
}
Developing our Key/Value Store Server
We can now begin to develop our server. To this end, common server functionality developed in the
Simple Socket Server and Client project
is moved into base classes for building servers
and clients. The abstract class
BaseServer
provides this functionality on the server side with the
abstract method
processConnection
overridden in derived classes to define their specific behavior.
This method is called for each connection that the server receives.
public abstract class BaseServer extends Thread {
...
abstract protected void processConnection(Socket socket) throws IOException;
...
Using this base class, we develop the
KeyValueServer
which responds to
SET
and
GET
requests.
class KeyValueServer extends BaseServer {
private static final Logger LOGGER = Dbf0Util.getLogger(KeyValueServer.class);
private final Map<ByteArrayWrapper, ByteArrayWrapper> map;
KeyValueServer(InetSocketAddress bindAddress, int nThreads, Map<ByteArrayWrapper, ByteArrayWrapper> map) {
super(bindAddress, nThreads);
this.map = Preconditions.checkNotNull(map);
}
@Override
protected void processConnection(Socket socket) throws IOException {
// read the first byte from the client, which denotes the message type
int operation = socket.getInputStream().read();
switch (operation) {
case -1:
LOGGER.warning("unexpected end of stream");
return;
case PrefixIo.SET:
processSet(socket);
break;
case PrefixIo.GET:
processGet(socket);
break;
default:
LOGGER.warning("bad operation: " + operation);
}
}
private void processSet(Socket socket) throws IOException {
var key = PrefixIo.readPrefixLengthBytes(socket.getInputStream());
var value = PrefixIo.readPrefixLengthBytes(socket.getInputStream());
LOGGER.finest(() -> "Set " + key + " to " + value);
map.put(key, value);
}
private void processGet(Socket socket) throws IOException {
var key = PrefixIo.readPrefixLengthBytes(socket.getInputStream());
var value = map.get(key);
if (value == null) {
LOGGER.finest(() -> "No value for " + key);
socket.getOutputStream().write(PrefixIo.NOT_FOUND);
} else {
LOGGER.finest(() -> "Found value for " + key + " of " + value);
socket.getOutputStream().write(PrefixIo.FOUND);
PrefixIo.writePrefixLengthBytes(socket.getOutputStream(), value);
}
}
}
On construction, this class takes a
Map
for it's backing storage so that we can experiment with
different
Map
implementations in testing out the key/value server.
Developing the Key/Value Client
Similar to
BaseServer, an abstract class
BaseConnector
encapsulates the functionality
for a client connection and this is used to develop our key/value client connecting logic.
public abstract class BaseConnector extends Thread {
...
abstract protected void processConnection(Socket socket) throws IOException;
...
Before developing the client, we define two interface that will be used by the client to specify client
behavior. In testing, we can develop different implementations of these interfaces to test out different behavior.
The first interface,
KeyValueSource
defines how the client determines what keys and values to use in
SET
and
GET
requests. The value generating logic takes a key so that we can
deterministically determine the value that should be associated with a key and therefore in check that the proper
value was returned from a
GET
request.
interface KeyValueSource {
ByteArrayWrapper generateKey();
ByteArrayWrapper generateValueForKey(ByteArrayWrapper key);
}
The second interface,
KeyValueTracker
allows us to track what keys have been set. This will be used
to help us detect potential bugs in the server where it appears to drop keys that had previously been set. For some
of our testing, we won't want the overhead of tracking set keys so we can instead use a no operation (i.e., noop)
version of this interface.
interface KeyValueTracker {
void trackSetKey(ByteArrayWrapper key);
boolean expectKeySet(ByteArrayWrapper key);
}
We also define a class to hold all of the stats that will be collected by the client.
class KeyValueClientStats {
final AtomicInteger set = new AtomicInteger(0);
final AtomicInteger get = new AtomicInteger(0);
final AtomicInteger found = new AtomicInteger(0);
final AtomicInteger missingKey = new AtomicInteger(0);
String statsString() {
return set.get() + " " + get.get() + " " + found.get() + " " + missingKey.get();
}
}
Using these components, we develop our client.
class KeyValueConnector extends BaseConnector {
private static final Logger LOGGER = Dbf0Util.getLogger(KeyValueConnector.class);
// specifies what fraction of requests should be SET vs GET
private final float setFraction;
private final KeyValueSource source;
private final KeyValueTracker tracker;
private final KeyValueClientStats stats;
private final Random random;
KeyValueConnector(InetSocketAddress connectAddress, String name,
float setFraction, KeyValueSource source,
KeyValueTracker tracker, KeyValueClientStats stats) {
super(connectAddress, name);
this.setFraction = setFraction;
this.source = source;
this.stats = stats;
this.tracker = tracker;
this.random = new Random();
}
@Override
protected void processConnection(Socket s) throws IOException {
if (random.nextFloat() < setFraction) {
performSet(s);
} else {
performGet(s);
}
}
...
The set operation is rather simple. We generate a key, compute it's value, and then send a
SET
request to the server containing the key and value.
private void performSet(Socket s) throws IOException {
var key = source.generateKey();
var value = source.generateValueForKey(key);
LOGGER.finest(() -> "set key " + key + " to " + value);
s.getOutputStream().write(PrefixIo.SET);
PrefixIo.writePrefixLengthBytes(s.getOutputStream(), key);
PrefixIo.writePrefixLengthBytes(s.getOutputStream(), value);
stats.set.incrementAndGet();
tracker.trackSetKey(key);
}
For get, we send a
GET
message containing the key and then read the response from the server. We
need to handle two cases: the case where the server did not have the key and the case where the key was found. In
the not found case, we want to check if we expected this key to be in the key/value store and count missing keys.
In the found case, we want to check that the value matches our expected value.
private void performGet(Socket s) throws IOException {
var key = source.generateKey();
LOGGER.finest(() -> "get key " + key);
s.getOutputStream().write(PrefixIo.GET);
PrefixIo.writePrefixLengthBytes(s.getOutputStream(), key);
stats.get.incrementAndGet();
int result = s.getInputStream().read();
switch (result) {
case -1:
LOGGER.warning("unexpected end of stream");
return;
case PrefixIo.FOUND:
stats.found.incrementAndGet();
var readValue = PrefixIo.readPrefixLengthBytes(s.getInputStream());
LOGGER.finest(() -> String.format("found %s=%s", key, readValue));
var expectedValue = source.generateValueForKey(key);
if (!readValue.equals(expectedValue)) {
LOGGER.warning(() -> String.format("incorrect value for %s: expected %s but given %s",
key, expectedValue, readValue));
}
break;
case PrefixIo.NOT_FOUND:
LOGGER.finest("not found");
if (tracker.expectKeySet(key)) {
stats.missingKey.incrementAndGet();
}
break;
default:
LOGGER.warning("bad result: " + result);
}
}
Experimenting with Map Implementations
With the server and client developed, we can now start experimenting with them. First, we want to investigate
how different implementations of
Map
behave in a mutli-threaded server. The
HashMap
implementation is not
thread safe and therefore we would expect potential race conditions when used in our multi-threaded server.
We start by creating a
KeyValueServer
backed by a
HashMap.
static KeyValueServer hashMapKeyValueServer(InetSocketAddress bindAddress, int nThreads) {
return new KeyValueServer(bindAddress, nThreads, new HashMap<>());
}
Next, we'll develop a
KeyValueSource
that generates randoms keys. The key length is configurable so
that we can vary the size of the key space.
class RandomKeyValueSource implements KeyValueSource {
private final Random random;
private final ByteArrayWrapper key;
private final ByteArrayWrapper value;
RandomKeyValueSource(int keyLength, int valueLength) {
this.random = new Random();
this.key = new ByteArrayWrapper(new byte[keyLength]);
this.value = new ByteArrayWrapper(new byte[valueLength]);
}
@Override
public ByteArrayWrapper generateKey() {
random.nextBytes(key.getArray());
return key;
}
@Override
public ByteArrayWrapper generateValueForKey(ByteArrayWrapper key) {
// for each key, deterministically compute a companion value
var k = key.getArray();
var v = value.getArray();
for (int i = 0; i < v.length; i++) {
v[i] = (byte) ~(int) k[i % k.length];
}
return value;
}
}
Lastly, we'll setup a multi-threaded client/server system in which we expect to encounter race conditions. The client will run two connector threads concurrently.
-
smallKeySpaceChecker: A read heavy connector that considers a small key space -
largeKeySpaceWriter: A write heavy connector that considers a significantly larger key space
Note that the two connectors considers entirely different key spaces since the keys are different lengths.
Nonetheless, we expect the large volumes of writes in a large key space to cause issues in reading keys within the
small space due to race conditions in the backing
HashMap.
public class CreateHashMapRaceCondition {
private static final InetSocketAddress ADDRESS = new InetSocketAddress("localhost", 9000);
public static void main(String[] args) throws Exception {
Dbf0Util.enableConsoleLogging(Level.FINE);
var server = KeyValueServer.hashMapKeyValueServer(ADDRESS, 4);
var smallKeySpaceChecker = new KeyValueConnector(ADDRESS, "checker", 0.2f,
new RandomizedKeyValueSource(1, 4),
KeyValueTracker.memoryTracker(),
new KeyValueClientStats()
);
var largeKeySpaceWriter = new KeyValueConnector(ADDRESS, "writer", 1.0f,
new RandomizedKeyValueSource(8, 4),
KeyValueTracker.noopTracker(),
new KeyValueClientStats()
);
var client = new Client(server, smallKeySpaceChecker, largeKeySpaceWriter);
server.start();
client.start();
}
private static class Client extends BaseClient {
private final KeyValueServer server;
private final KeyValueConnector smallKeySpaceChecker;
private final KeyValueConnector largeKeySpaceWriter;
public Client(KeyValueServer server,
KeyValueConnector smallKeySpaceChecker,
KeyValueConnector largeKeySpaceWriter) {
super(Set.of(smallKeySpaceChecker, largeKeySpaceWriter));
this.server = server;
this.smallKeySpaceChecker = smallKeySpaceChecker;
this.largeKeySpaceWriter = largeKeySpaceWriter;
}
@Override
protected void waitUntilComplete() throws InterruptedException {
while (true) {
System.out.println("size: " + server.size());
System.out.println("checker: " + smallKeySpaceChecker.getStats().statsString());
System.out.println("writer: " + largeKeySpaceWriter.getStats().statsString());
System.out.println();
Thread.sleep(500);
}
}
}
}
In running the test system, we discover missing keys due to the expected race conditions.
checker: 0 0 0 0
writer: 52 0 0 0
size: 283
checker: 646 2382 1495 0
writer: 52 0 0 0
...
size: 2174
checker: 1825 7126 6137 1 # First missing key
writer: 1919 0 0 0
...
size: 101309
checker: 25047 99653 98657 4
writer: 101067 0 0 0
...
size: 1629430
checker: 236696 949216 947848 376
writer: 1629275 0 0 0
The missing keys are attributed to a race condition whereby a write from one thread causes the
HashMap
to grow beyond it's currently configured load capacity and therefore has to allocate a new
array for it's table of hash-positioned entries. It then populates this new table with the existing contents of the
HashMap. If another thread attempts to read from the table while the copying is running, then the
reading thread cannot access any keys that have yet to be copied. Hence, the missing keys in our read-heavy
connector.
Even worse situations can happen when multiple threads attempt to write to the
HashMap
at the same
time. As an exercise, you can modify
CreateHashMapRaceCondition
to create a race condition with
multiple concurrent writes. What happens and can you explain why this happens?
These results demonstrate that we cannot use a
HashMap
to handle the concurrent access patterns of
our multi-threaded key/value store. Another
Map
implementation that we can consider is
Hashtable
, which
uses locking to synchronize it's operations. To verify this is the case, we re-run the test using a
KeyValueServer
backed by a
Hashtable.
static KeyValueServer hashTableKeyValueServer(InetSocketAddress bindAddress, int nThreads) {
return new KeyValueServer(bindAddress, nThreads, new Hashtable<>());
}
And the results show no missing keys after running for a while.
size: 1077538
checker: 167267 666816 665741 0
writer: 1077282 0 0 0
ConcurrentHashMap
is another thread-safe implementation of
Map. In many use cases, this implementation provides better
performance because internally it stores data in different segments and performs locking at the individual segment
level. In contrast,
Hashtable
uses a single lock for guarding all entries and therefore cannot support
concurrent operations. Further,
ConcurrentHashMap
manages its internal structure in such a way that no
locking is required for get operations.
Repeating the test with
ConcurrentHashMap
also shows no missing keys.
static KeyValueServer concurrentHashMapKeyValueStore(InetSocketAddress bindAddress, int nThreads) {
return new KeyValueServer(bindAddress, nThreads, new ConcurrentHashMap<>());
}
size: 2056205
checker: 405713 1625911 1624916 0
writer: 2055949 0 0 0
Benchmarking
A simple benchmarking harness is developed to run both the key/value database server and the client. Its arguments include several different properties of the database, client, and workload so that we can benchmark a range of different scenarios.
public class Benchmark {
private static final InetSocketAddress ADDRESS = new InetSocketAddress("localhost", 9000);
private static final Map<String, Class<? extends Map>> MAP_CLASSES = ImmutableMap.of(
"hashtable", Hashtable.class,
"concurrent", ConcurrentHashMap.class
);
public static void main(String[] args) throws Exception {
Preconditions.checkArgument(args.length == 7);
Dbf0Util.enableConsoleLogging(Level.INFO);
var serverThreads = Integer.parseInt(args[0]);
var clientThreads = Integer.parseInt(args[1]);
var mapType = args[2];
var keyLength = Integer.parseInt(args[3]);
var valueLength = Integer.parseInt(args[4]);
var setFrac = Float.parseFloat(args[5]);
var duration = Duration.parse(args[6]);
var map = ((Class<? extends Map<ByteArrayWrapper, ByteArrayWrapper>>) MAP_CLASSES.get(mapType))
.getConstructor().newInstance();
var server = new KeyValueServer(ADDRESS, serverThreads, map);
var stats = new KeyValueClientStats();
var client = new SleepingClient(IntStream.range(0, clientThreads).mapToObj(
i -> new KeyValueConnector(ADDRESS, "conn-" + i, setFrac,
new RandomKeyValueSource(keyLength, valueLength),
KeyValueTracker.noopTracker(), stats))
.collect(ImmutableList.toImmutableList()),
duration
);
server.start();
Thread.sleep(100);
client.start();
client.join();
server.closeServerSocket();
server.join();
System.out.println(new Gson().toJson(stats));
}
}
In benchmarking, we consider these different factors:
- client/sever threads : values of 1, 4, 8, 16, and 32 are considered
-
map type
- either
HashtableorConcurrentHashMap -
key length
- varies the size of the key space
- 2 bytes: a small dense key space of size 256^2 = 65,536
- 16 bytes: a large sparse key space of size 256^16 = 3.4e38
-
set fraction
- the fraction of client requests for
SETvsGETrequests- 0.1: read heavy
- 0.5: balanced
- 0.9: write heavy
All benchmarking trials are ran for 10 seconds and value length is fixed at 64 bytes. 10 trials are ran for each parameter combination to allow us to measure the variation of the results.
For comparison to the Simple Socket Server and Client project, we use the same AWS EC2 instance configuration.
- Instance type : c5n.2xlarge
- vCPUs : 8
- RAM : 21 GiB
- OS Image : Ubuntu 18.04 LTS - Bionic
- Kernel : Linux version 4.15.0-1065-aws
- JRE : OpenJDK 64-Bit Server VM version 11.0.6
- net.ipv4.tcp_tw_reuse : Enabled to prevent port exhaustion due to TIME-WAIT ( details )
Benchmarking is performed using a simple Python script that iterates through all defined parameter combinations,
runs the Java
Benchmark
harness, and records the results for subsequent analysis. It takes roughly
five hours to run all benchmarks.
Analysis of Benchmarking Results
We compute the total operations per a second for each benchmarking run as the sum of
SET
and
GET
operations. Results are then aggregated across different trials to give the median operations per
a second as well as the 25th and 75th percentiles for quantifying variance.
High-level Results
We start with a high-level analysis of the map implementation, key space size, and the workload as specified by set fraction (either read heavy, balanced, or write heavy). For each combination of these parameters, we find the server/client thread counts combination that gives the highest operations per a second. These high level results are shown in the following figure.
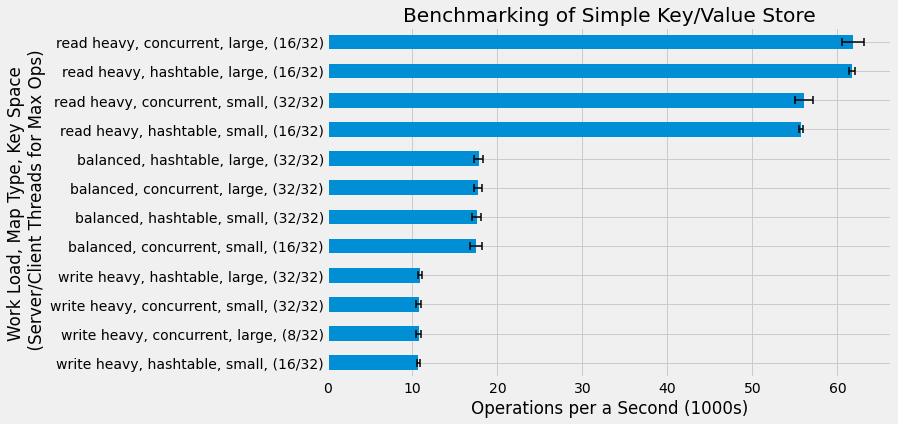
Our main observation is that workload has the largest impact on performance with read heavy workloads having the highest operations per a second and write heavy having the lowest. Map implementation and key space size appear to have a relatively small impact on the overall performance. This is quite interesting and we'll consider why this the case in the subsequent discussion section of this project. We also see that higher performance is achieved with the large key space relative to the small key space in all cases, although this effect is smaller than the workload impact.
It is also a bit surprising that the highest performance with respect to threading is achieved with either 16 or 32 server threads and 32 clients threads, despite the fact that the benchmarking host only has 8 vCPUs. We'll further analyze how threading configurations impact performance in the next section.
Impact of Threading
We now analyze the impact of threading on different workloads, map implementations, and key space sizes. First,
we consider the
ConcurrentHashMap
map implementation and a large key space since this gave overall
highest operations per a second. For each of the workloads, we plot how performance varies with different numbers
of server/client threads. For brevity, we only plot the nine highest performing thread configurations as well as
the single threaded server and client case. Each axes of the following figure also includes the relative different
between the highest performance case and single threaded case in the axes title.
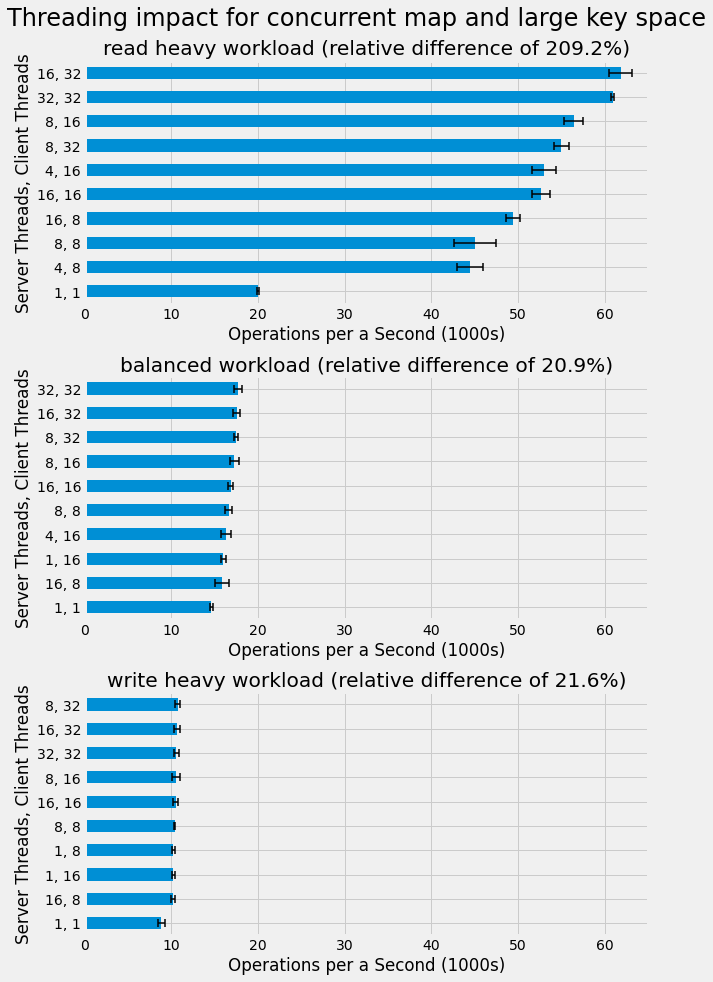
The impact of threading is found to be largest for the read heavy workload with performance over tripling between the single threaded case and highest performing one. In contrast, threading has a more modest impact in the balanced and write heavy workloads. For all workloads, performance is maximized by maxing out client threads to 32. This suggests we could possibly get even higher performance with more client threads, although our earlier benchmarking in the Simple Socket Server and Client project showed lower performance when going beyond 16 client threads. In general, systems with more client threads than server threads outperform those with an equal number of threads in both the client and server. This suggests a non-trivial overhead in the client, which may be attributed to generating random byte arrays.
Next we analyze the impact of threading when using the
Hashtable
map implementation and see how its
different locking mechanism relative to
ConcurrentHashMap
changes the results.
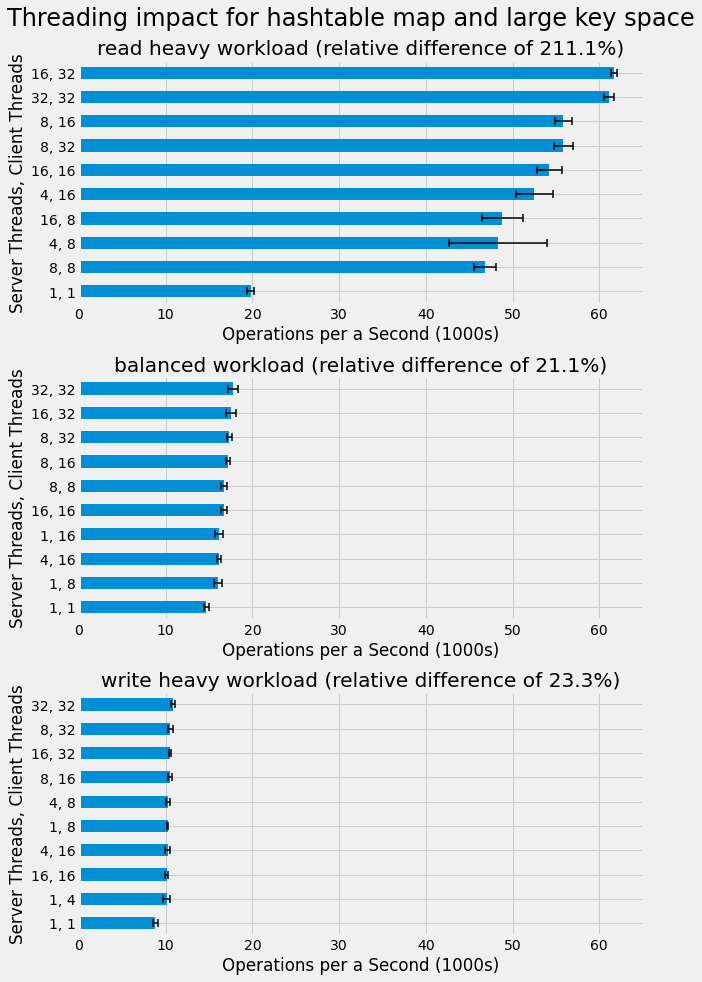
Overall, we see that the threading trend for
Hashtable
are quite similar to those seen for
ConcurrentHashMap.
A similar analysis of threading impact is also performed for both map implementations with the small key space and results are very similar to those with the large key space. Results are not included here for brevity and you can view the notebook for the results.
Discussion and Next Steps
We've now completed our first database! It may be simple, only storing keys in memory and providing no persistent storage, but it is a start. Further, such in-memory only key/value stores have utility in certain use cases such as caching frequently used results in front of a disk-based database to increase performance.
We have benchmarked our key/value store and discovered a large disparity between the performance of read heavy
and write heavy workloads. Essentially, we've found that it is significantly more expensive to write to an
in-memory map than it is to read. This can likely be attributed to the various booking that a
Map
has
to perform for each set to add the key/value or change the value for a key.
Further, it is found that mutli-threading can triple the performance of read heavy workloads, but has more
modest impact of roughly 20% improvement for write heavy workloads. Even with our key/value store backed by a
ConcurrentHashMap
that is composed of disjoints segments with their own lock, we don't get much
improvement when increasing threads in the server and client. This might be attributed to need to continuously
allocate memory when writing new objects, yet if that were the case we'd expect to see some disparity between the
small key space and large key space results. As a quick check, a small number of benchmarking results were
collected for a very small key space with keys of length 1 (only 256 unique keys) and the results were comparable
to those for the small and large key spaces. We can think about this and possibly revisit this project when we have
some hypotheses about how to increase write performance with multiple threads.
For our next database, we'll develop actual disk-based persistence and that will introduce some new challenges. Check out Disk-Based Storage Engine for Read-Only Key/Value Data to learn about these challenges and see how they can be addressed.