
Developing Partitioned Storage and Analyzing Time-Dependent Benchmarks
Our key/value storage engine continues to mature with the addition of partitioning. Partitioning, (i.e., sharding) consists of splitting a database up into separate sub-databases (i.e., partitions) that each store a portion of the full data. Each partition can then act with some level of independence.

Our latest project introduces partitioning into our previously-developed Log-Structured Merge-Tree storage engine. This results in multiple distinct LSMtrees that each manage a portion of the keys and each LSMTree can act independently. Hence, multiple concurrent writes can be performed in different LSMTrees and this is expected to reduce lock contention and enhance concurrent performance.
Benchmarking results show a doubling of overall performance across a variety of different workloads when applying partitioning.
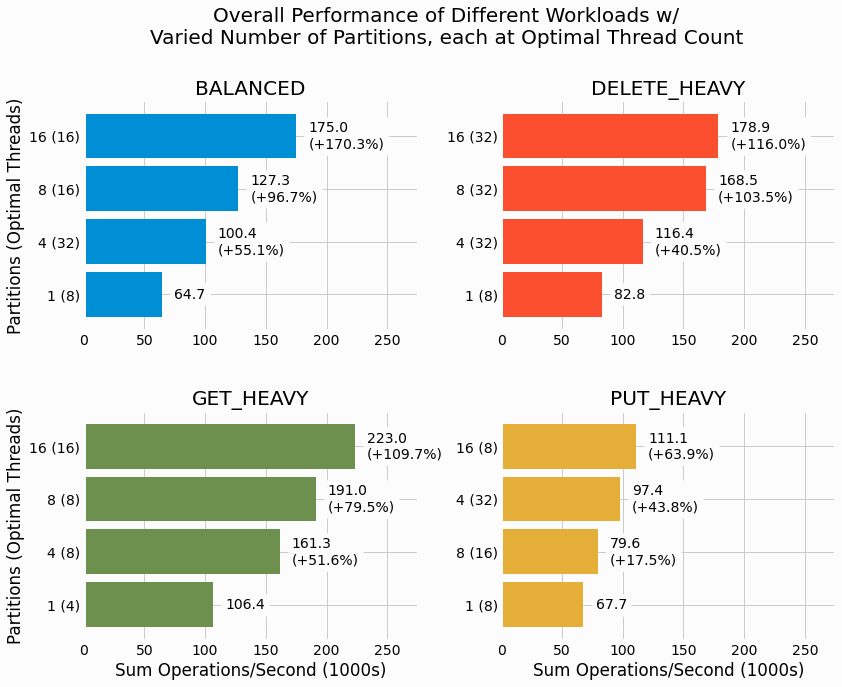
Checkout the analysis section of the project for more details and additional results.
Newly introduced in this project is a
time-dependent analysis
of
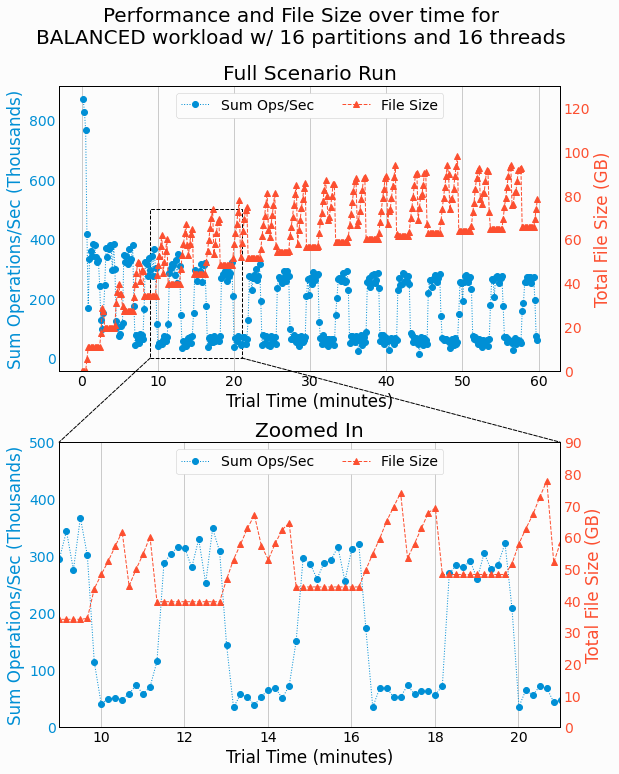
storage engine performance over each one hour benchmarking run. Through this analysis, we discover that the storage
engine performance shows periodic behavior with performance differing by a roughly a factor of 3 between low and
high performance regions of time. Correlating the performance with disk space usage shows the degraded performance
occurs when disk usage increases, which corresponds to writing deltas and merging deltas with the base. While this
wasn't expected, it makes sense considering the competition between disk reads from
GET
requests,
writes in delta generation, and the combination of reads and writes in delta/base merging.
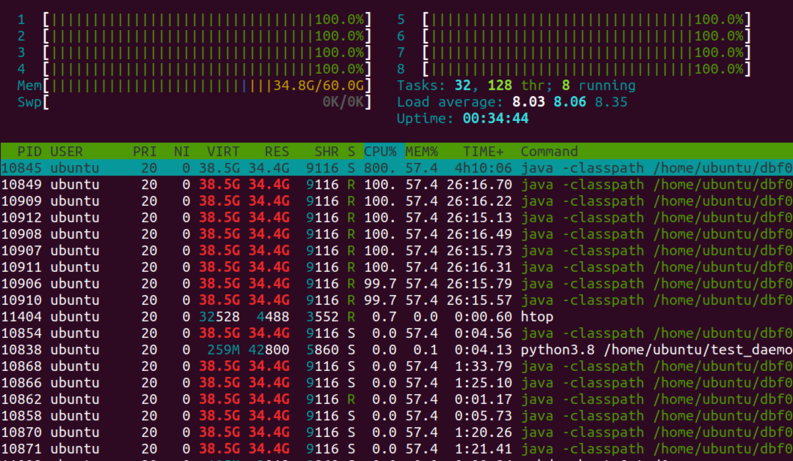
Time-dependent analysis is also used to investigate the abysmally low performance discovered for put-heavy workloads with many concurrent threads performing operations and using a store with a high number of partitions. Subsequent manual monitoring for debugging of such a run reveals that the host's 8 vCPUs are heavily oversubscribed with many more threads attempting to run than possible. These results explain the abysmally low performance in these cases and we discuss why only put-heavy workloads are impacted.
For our next project, we'll address data durability by introducing
write-ahead logging
to keep a record of all write
operations on disk. This project is actively being developed and I'm discovering some surprising benchmarking
results when exploring different
fsync
strategies for ensuring the data is on disk. Check back soon
for this new project.