
Developing a Log-Structured Merge-Tree for Persistent Reads and Writes
We now have a disk-based, key/value storage engine that supports random writes in addition to reads. This is an exciting milestone in our journey through database development! To address the unique challenges associated with random writes, we explore the Log-Structured Merge-Tree (LSMTree) data structure. You can learn all about the LSMTree and also walk through the development and benchmarking of an LSMTree-based storage engine in our latest project, Log-Structured Merge-Tree for Persistent Reads and Writes
As explained in-depth in the
project
background section, an LSMTree leverages multiple types of containers for storing its key/value data. These
different types of containers each have unique properties, chiefly storing in memory versus storing on disk, to
best suite how each container is used. In-memory containers are used to collect writes (both
put
and
delete
requests) and when the collection of writes grows large enough, these are written to disk in
batch. The persistence process includes sorting and indexing by key to support efficient searching for keys when
subsequently reading from the file. Each of these files forms a read-only container that is used in conjunction
with the in-memory containers.
Further, multiple disk-based containers can be efficiently combined through merge sort to produce a single consolidated store. In doing so, multiple records for a single key from different containers can be reduced down to a single record. As discussed further in the background section of the project, it is important to always prefer the more recent record for a given key when performing this consolidation.
The overall structure of an LSMTree in terms of the different containers it uses is summarized in the following diagram.

There are several concurrent processes in a LSMTree for creating, combining, and deleting containers and these
processes requires careful coordination. The
development section
goes into more
detail, including how we use the
ReadWriteLock
to allow multiple concurrent readers while still
allowing a writer to gain exclusive access for modifications. I am happy to report that this project includes a
unit testing section
as
promised. Further this is accomplished with a general
ReadWriteStorageTester
that can be reused in future projects to run many sanity checks against a
storage engine that supports random reads and writes. The following code snippets shows an example of how this
simplifies testing.
@Test public void testSingleThreaded() throws IOException {
var tree = createLsmTree(1000);
var tester = ReadWriteStorageTester.builderForBytes(tree, RandomSeed.CAFE.random(), 16, 4096)
.debug(true)
.checkDeleteReturnValue(false)
.checkSize(false)
.build();
tester.testPutDeleteGet(10 * 1000, PutDeleteGet.BALANCED, KnownKeyRate.MID);
}
Confident in the correctness of our LSMTree, we move on to
benchmarking its performance in a variety of scenarios. Many
parameters are considered in benchmarking and you can find the full results in the linked project benchmarking
section. One interesting thing we explore is key space size; i.e., the maximum number of possible unique keys that
are used in
put,
get, and
delete
requests. With a small enough key space, in
this case 10 million is found to be relatively small, the database reaches a maximum fixed size during our one hour
benchmarking run. This happens because after every possible key has been added, future
put
requests
just modify an existing key. Conversely, with larger key spaces, the database size continues to grow throughout the
entire benchmarking run. The larger data size created with larger key spaces is found to decrease performance and
this is attributed to overall heavier input/output (IO) load for larger data size.
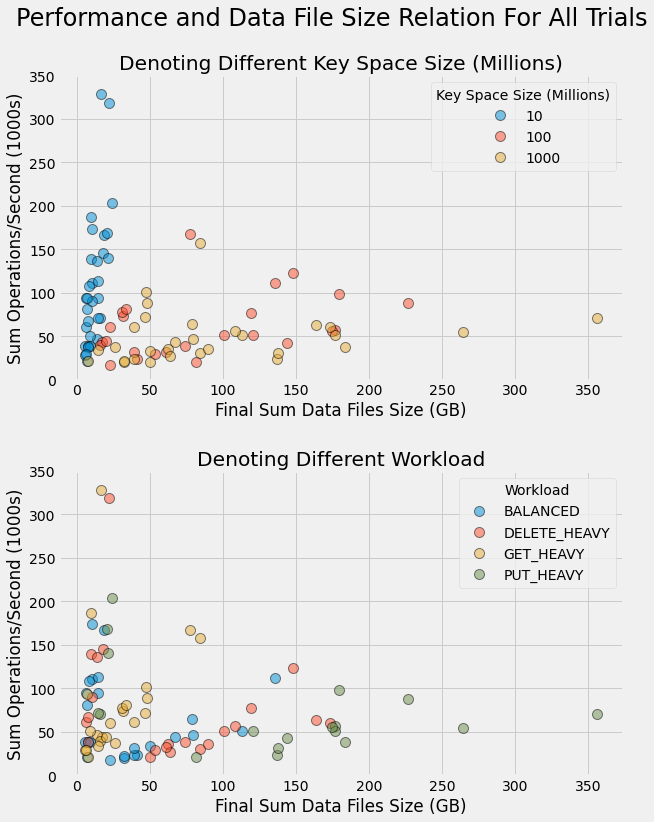
You can find more details about these results as well as the results for additional parameters in the benchmarking analysis section of the project.
As you can see from the figure, our key/value storage engine is able to manage data sizes of up to 350 GB, while still maintaining roughly 50k operations/second. With smaller data sets, we get substantially higher performance. This is quite exciting!
One interesting observation we find in analyzing the benchmarking results is that four threads performing
concurrent operations on our LSMTree is the optimal number. Increasing thread count beyond this leads to diminished
performance. In contrast, in our
read-only key value store
we
previously found 16 and 64 threads to lead to higher performance than using just 4. We speculate that these results
for our LSMTree can be attributed to lock contention. I.e., any time one thread wants to perform a write in the
form of a
put
or
delete
operation, all other threads are excluded from performing
operations on the LSMTree, including reading for
get
operations.
In our next project we'll explore whether we can ameliorate issues related to lock contention using partitioning/sharding, i.e., splitting our data into multiple segments, and thereby allowing multiple concurrent operations to be performed on different segments without coordination. And spoiler alert, I have some preliminary results that show partitioning can substantially increase performance in our LSMTree storage engine. Check back soon for our project on partitioning, including the final benchmarking results.