
Developing a Document Database and Testing it on 147 Million Reddit Comments
We can now store arbitrarily complex data in our key/value store using newly developed support for semi-structured data (e.g., JSON). Our latest project, Document Storage Engine for Semi-Structured Data, generalize our partitioned, log-structured merge-tree (LSMTree) key/value store to use generic and expendable serialization formats. Further, we develop a new data model for documents that is similar to JSON, including types such as integers, strings, arrays, and maps. A serialization protocol is developed to allow storing documents in the LSMTree. You can see a description of the serialization format and examples in the following diagram.

To test out our new data store, we consider a dataset of 147 million Reddit comments (185 GB) by pushshift.io. Each comment is encoded in JSON format as shown in the following example.
{
"all_awardings": [],
"associated_award": null,
"author": "frankylovee",
"author_created_utc": 1440098192,
"author_flair_background_color": null,
"author_flair_css_class": null,
"author_flair_richtext": [],
"author_flair_template_id": null,
"author_flair_text": null,
"author_flair_text_color": null,
"author_flair_type": "text",
"author_fullname": "t2_ppvut",
"author_patreon_flair": false,
"awarders": [],
"body": "I try not to feed my cat when she screams at me, but she literally will not stop until I do.\n\nEdit: cat tax https://imgur.com/gallery/v70Fh85",
"can_gild": true,
"can_mod_post": false,
"collapsed": false,
"collapsed_reason": null,
"controversiality": 0,
"created_utc": 1564617600,
"distinguished": null,
"edited": 1564710503,
"gilded": 0,
"gildings": {},
"id": "evn2i5p",
"is_submitter": false,
"link_id": "t3_ckej3g",
"locked": false,
"no_follow": true,
"parent_id": "t3_ckej3g",
"permalink": "/r/AnimalsBeingJerks/comments/ckej3g/dont_encourage_the_screaming_kitten/evn2i5p/",
"quarantined": false,
"removal_reason": null,
"retrieved_on": 1573370605,
"score": 109,
"send_replies": true,
"steward_reports": [],
"stickied": false,
"subreddit": "AnimalsBeingJerks",
"subreddit_id": "t5_2wfjv",
"subreddit_name_prefixed": "r/AnimalsBeingJerks",
"subreddit_type": "public",
"total_awards_received": 0
}
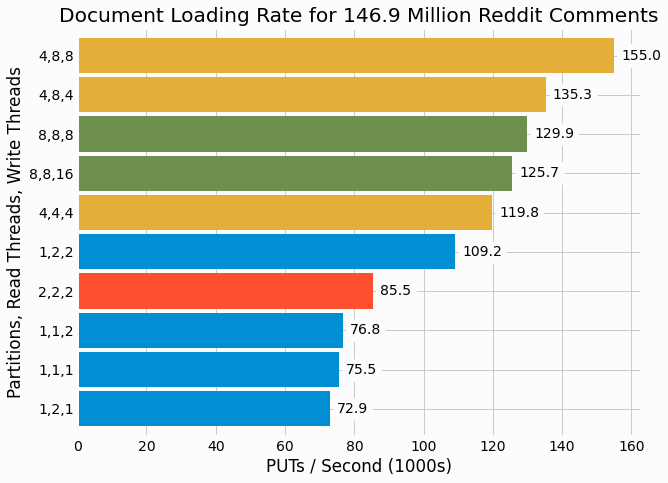
Benchmarking is performed to quantify the performance of the new document store with different configuration options and different degrees of concurrency. We find that that the full dataset of 147 million Reddit comments can be loaded in between 15 and 33 minutes. Loading rates for different benchmarking trials are shown in the following figure.
Additionally, we benchmark and analyze the performance of fetching documents from the store.
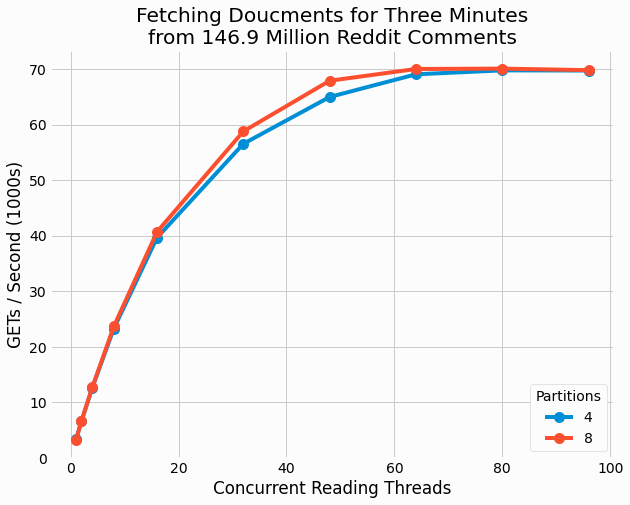
It is interesting that performance continues to scale all the way up to 64 threads, even though the machine only
has 36 vCPUs. This suggests that
GET
operations are not heavily compute-bound despite the need to
deserialize entries from disk. Additionally, we find minor different in performance for 4 versus 8 partitions. This
makes sense as only read operations are performed in this benchmarking and therefore there is no lock contention
between threads as could be ameliorated with higher partition counts.
Lastly, we benchmark the performance of updating a comment, which consists of fetching the current document, incrementing its score, and then writing the updating value back to the store.
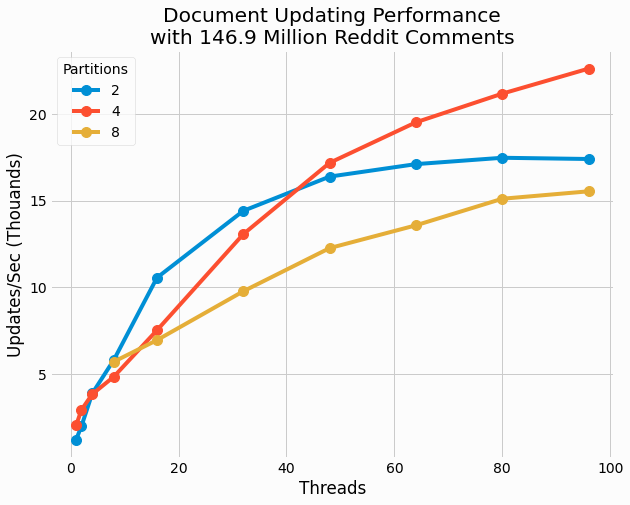
These results are quite interesting in that no single partition count outperforms the others for all thread counts. For 32 and fewer threads, the 2 partition cases outperform the other cases. Yet for higher thread count, 4 partitions results in optimal performance. 8 partitions generally under performs relative to the two other cases.
Document storage is significant feature for our prototype database. Further, with semi-structured values, we'll be able to develop support for secondary indexes and partial GET and SET operations, which are valuable features for a storage engine. Secondary indexes have many similarities to a primary index, but one key difference is the secondary key is not necessarily unique and therefore multiple values can be associated with a single secondary key. Hence, we'll need to develop support for associating an arbitrarily large number of values with a single key to implement secondary indexes. I'm currently developing our multi-value key/value store project so check back soon to learn how we can address this challenge.