
Working With Disks to Create a Persistent, Read-Only Key/Value Store
We've started working with actual persistent storage in our new project, a Disk-Based Storage Engine for Read-only Key/Value Data. In this project, we explore some of the unique software engineering challenges associated with working with disks and learn how to address them. To simplify some of these challenges in our first project using disks, we develop a key/value store that only supports random reads with writes performed in one large, initial batch.
In addition to development, we also benchmark our new key/value store on AWS EC2 instances using three different types of disk drives.
- HDD : magnetic Hard Disk Drive
- SSD : Solid State Drive
- NVMe : high-performance Non-Volatile Memory Express drive
And as one might expect, the type of disk drive used has a massive impact on performance.
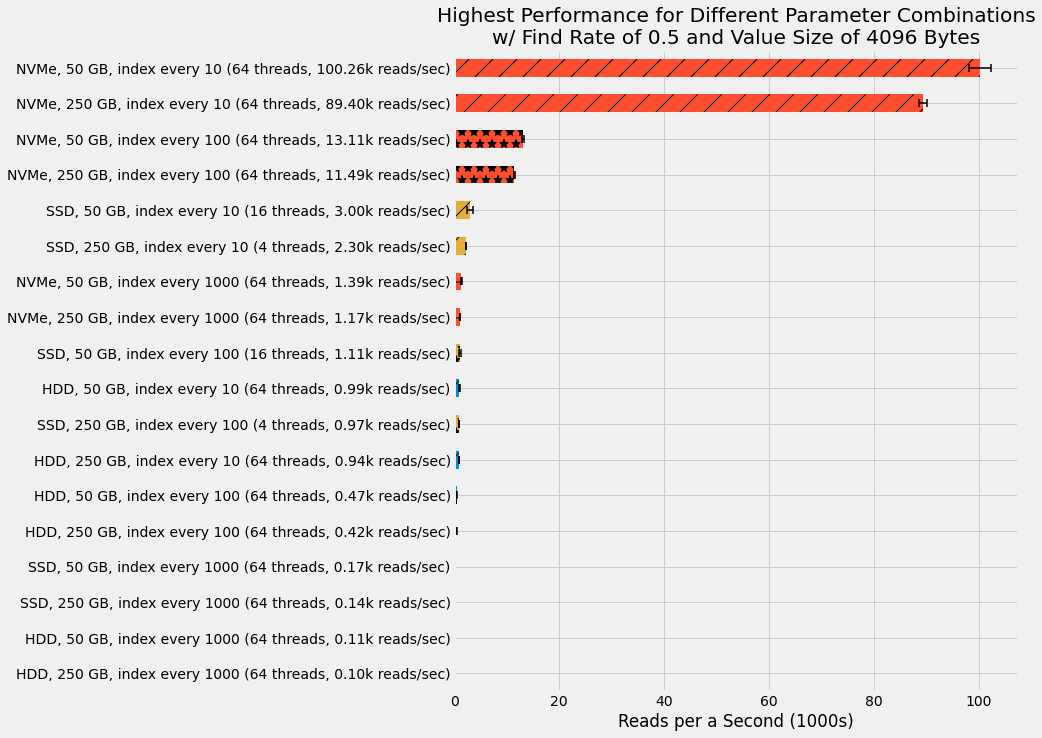
You can find additional benchmarking results and details in the project page.
These results are for data sizes of 50 GB and 250 GB. We also benchmark a smaller 10 GB data size, but we eliminate those results from further analysis due to some anomalous behavior. Specifically, we find the SSD showing roughly 50% higher performance than the NVMe, which is unexpected. It is hypothesized that this is the result of the operating system page cache holding a substantial portion of the underlying data in memory and therefore we're not actually testing the SSD performance. This is a common gotcha in working with disks and the project page provides more details on the page cache and additional considerations for working with disks.
A fun axillary challenge in this project consists of generated large key/value files (up to 250 GB) that are
sorted by keys. From my experience working with Hadoop, I was already familiar with
external sorting
by using merge sort to combine multiple small
sorted files into a single large sorted file. Yet I had never before implemented such an algorithm directly and it
was fun to do so. I'll admit that the guava routine
Iterators.mergeSorted
does most of the heavy
lifting.
Next, we'll be adding support for random writes with disk-based persistence. At present, I'm having a lot of fun playing around with BTrees and block management in an append-only file in developing this project. Also looking forward to exploring Log-structured merge-trees (LSM trees). Hope to have that new project for you soon.
Lastly, I've been thinking a bit about benchmarking. Currently, I've just been developing combinations of shell scripts and Python scripts that I run in screen sessions on individual EC2 instances to perform benchmarking. This requires more manual work than I'd like and therefore I've been experimenting with some simple automation tools for creating and managing a group of EC2 instances for running benchmarks. As this comes together, I'll release a small Python library for benchmarking automation. More details to follow.